6.1_检索增强生成简介
6.1 检索增强生成简介
检索增强生成(RAG)旨在通过检索和整合外部知识来增强大语言模型生成文本的准确性和丰富性,其是一个集成了外部知识库、信息检索器、大语言模型等多个功能模块的系统。RAG利用信息检索、深度学习等多种技术为大语言模型在生成过程中引入最新的、特定领域的知识,从而克服传统大语言模型的局限性,提供更加精准和可靠的生成内容。本节我们将主要介绍RAG系统的相关背景、定义以及基本组成。
6.1.1 检索增强生成的背景
大语言模型在多种生成任务上展现出了令人惊艳的能力,其可以辅助我们撰写文案、翻译文章、编写代码等。但是,大模型生成的内容可能存在“幻觉”现象——生成内容看似合理但实际上逻辑混乱或与事实相悖。这导致大语言模型生成内容的可靠性下降。“幻觉”现象可能源于大语言模型所采用的训练数据,也可能源于模型本身。
1. 训练数据导致的幻觉
训练数据是大语言模型知识的根本来源。训练数据在采集完成后直接用于训练模型。但是其中包含的知识可能在模型训练后又发生了更新。这将导致知识过时的问题。不仅如此,知识在训练数据采集完成后仍会新增,并且训练数据采集也无法覆盖世间所有知识,尤其是垂域知识,这将导致知识边界的问题。此外,训练数据中还可能包含不实与偏见信息,从而导致知识偏差问题。
对于知识过时问题,由于训练数据涵盖的知识止步于大语言模型训练的时间截面,其掌握的知识无法与现实世界同步更新。此处,以ChatGPT为例1,对于问
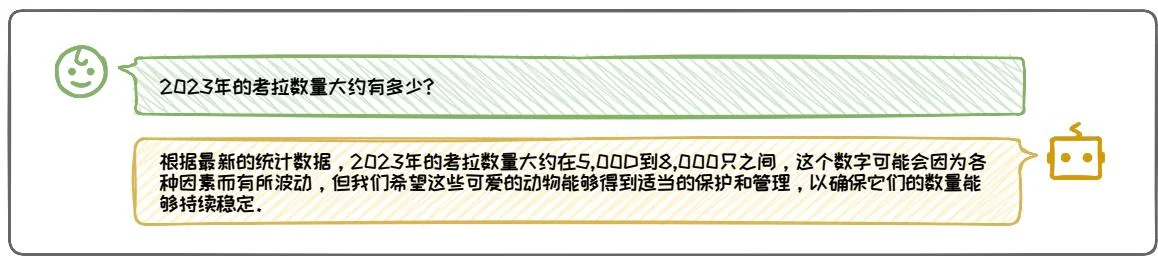
图6.1:知识过时引起的幻觉现象示例。

图6.2: 模型自身导致的幻觉示例。
题 “2023 年的考拉数量大约有多少?”,模型的回答为 5,000 到 8,000 只之间,如图 6.1 所示。然而,正确数量应约为 86,000 到 176,000 只。由于 ChatGPT 的完成训练的时间节点是 2022 年,导致它无法掌握 2023 年的知识,给出了错误的回答。
虽然大语言模型的训练数据非常庞大,但仍然是有限的。因此,模型内部的知识必然存在知识边界,即缺乏某些特定领域的知识。例如,当我们想知道考拉的基因数量时,模型可能无法提供正确的信息,因为预训练数据中并不包含相关信息。此外,由于大语言模型的语料很多是从互联网直接爬取而未核验的,其中可能会存在含偏向某些特定观点或存在事实性偏差的低质量数据,从而带来知识偏差,导致模型输出存在不良偏差。
2. 模型自身导致的幻觉
除了训练数据的影响,我们还发现在某些场景下,即使训练数据中已经包含了相关知识,大语言模型仍然会出现幻觉现象。如图6.2中的例子所示,我们同样使用ChatGPT进行测试,可以看到模型并没有意识到考拉是树袋熊的音译别名,而错误的把这两个名称认为是两种不同的动物,偏离了事实。为了进一步探究大语

图6.3: 内部泛化能力不足的进一步示例。
言模型是否真的不具备相关知识。我们进行了进一步实验,结果如图 6.3 所示,此时大语言模型给出了正确回答。上述示例表明,大语言模型实际上包含了问题的正确知识,但依然出现了偏差的回答。
上述偏差可能来自于模型自身,可能的因素包括:(1)知识长尾:训练数据中部分信息的出现频率较低,导致模型对这些知识的学习程度较差;(2)曝光偏差:由于模型训练与推理任务存在差异,导致模型在实际推理时存在偏差;(3)对齐不当:在模型与人类偏好对齐阶段中,偏好数据标注不当可能引入了不良偏好;(4)解码偏差:模型解码策略中的随机因素可能影响输出的准确性。
上述幻觉问题极大地影响了大语言模型的生成质量。这些问题的成因主要是大语言模型缺乏相应的知识或生成过程出现了偏差,导致其无法正确回答。借鉴人类的解决方式,当我们遇到无法回答的问题时,通常会借助搜索引擎或查阅书籍资料来获取相关信息,进而帮助我们得出正确答案。自然地,对于大语言模型不熟悉的知识,我们是否也可以查找相关的信息,从而帮助它得到更准确的回答呢?为了验证这一设想,我们可以进行一个简单的实验,同样是上面的两个例子,我们简单地以 Prompt 的形式加入相关的外部知识,如图 6.5、图 6.7 所示,模型很自然

As at March 2024, the latest estimate of population size for koalas in Queensland, New South Wales and the Australian Capital Territory (the listed population), without any additional assumptions, is between 95,000 and 238,000. In 2023, the adjusted population estimate, accounting for areas where there is little or no data, generated a listed koala population estimate of between 86,000 and 176,000 koalas.
This broadly aligns with the Threatened Species Scientific Committee (TSSC) estimate of 92,184 koalas in the combined Queensland, New South Wales, and Australian Capital Territory population, based on best available information and expert elicitation in 2021.
The latest population estimate generated using the NKMP moves closer to the 2023 adjusted population estimate.

图6.4: 关于2023树袋熊数量的网络资料截图。
图 6.5: 添加外部信息纠正知识过时引起的幻觉示例。
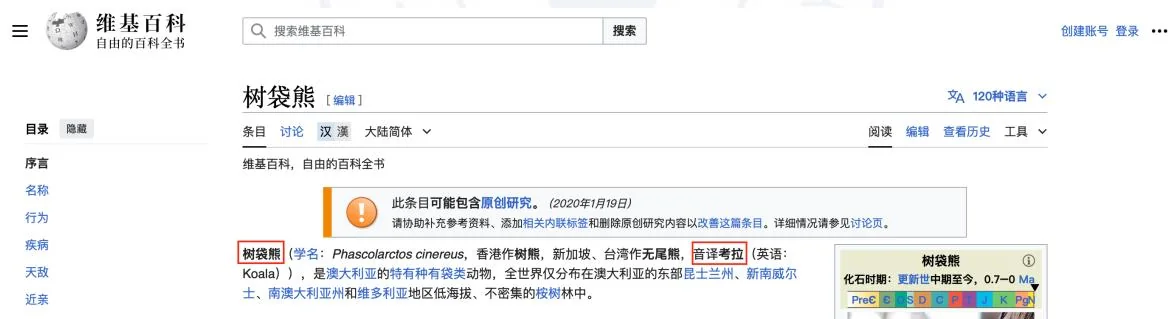
图6.6: 关于树袋熊名称的维基百科截图。
地得出了正确的回答,其中图 、图 为对应的知识来源。这种思路便是检索增强生成 (Retrieval-Augmented Generation, RAG) 的核心思想。接下来,我们对RAG系统进行简要介绍。

图6.7: 添加外部信息纠正模型自身引起的幻觉示例。
6.1.2 检索增强生成的组成
RAG 的概念最早出现在 Facebook AI Research 的论文 Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks [28] 中。其通常集成了外部知识库 (Corpus)、信息检索器 (Retriever)、生成器 (Generator, 即大语言模型) 等多个功能模块。通过结合外部知识库和大语言模型的优势, 大幅提升模型在开放域问答、多轮对话等任务中的生成质量, 其基本架构如图 6.8 所示。具体而言, 给定一个自然语言问题 (Query), 检索器将问题进行编码, 并从知识库 (如维基百科) 中高效检索出与问题相关的文档。然后, 将检索到的知识和原始问题一并传递给大语言模型, 大语言模型根据检索到的知识和原始问题生成最终的输出。RAG 的核心优势在于不需要对大语言模型的内部知识进行更新, 便可改善大语言模型的幻觉现象, 提高生成质量。这可以有效避免内部知识更新带来的计算成本和对旧知识的灾难性遗忘 (Catastrophic Forgetting)。
接下来,我们通过图6.8中的例子来描述RAG的基本工作流程。用户输入一个问题“2023年的考拉数量有多少?”,首先,该问题会传递给RAG框架的检索器模块,检索器从知识库中检索相关的知识文档,其中包含了与2023年的考拉数量相关的信息;接下来,这些信息通过Prompt的形式传递给大语言模型(大语言模型利用外部知识的形式是多样的,通过Prompt进行上下文学习是其中最常用的形
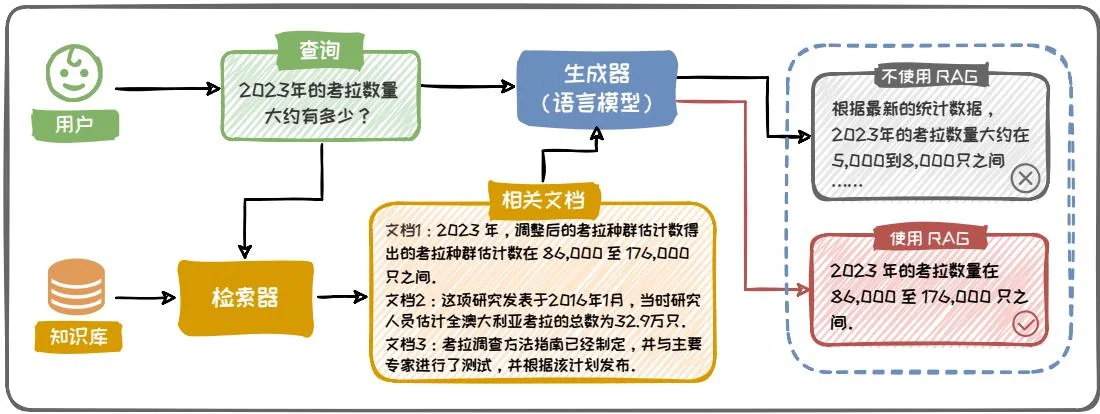
图6.8: RAG基本架构示意图。
式),最终得出了正确的答案:“2023年的考拉数量在86,000至176,000只之间。”然而,同样的问题,如果让大语言模型在不使用RAG的情况下直接回答,则无法得到正确的答案,这说明了RAG系统的有效性。
仅仅简单地对外部知识库、检索器、大语言模型等功能模块进行连接,无法最大化 RAG 的效用。本章将围绕以下三个问题,探讨如何优化设计 RAG 系统。
如何优化检索器与大语言模型的协作?根据是否对大语言模型进行微调,我们将现有的 RAG 系统分为(1)黑盒增强架构,不访问模型的内部参数,仅利用输出反馈进行优化;(2)白盒增强架构,允许对大语言模型进行微调。详细内容将在 6.2 节介绍。
如何优化检索过程?讨论如何提高检索的质量与效率,主要包括:(1)知识库构建,构建全面高质量的知识库并进行增强与优化;(2)查询增强,改进原始查询,使其更精确和易于匹配知识库信息;(3)检索器,介绍常见的检索器结构和搜索算法;(4)检索效率增强,介绍用于提升检索效率的常用相似度索引算法;(5)重排优化,通过文档重排筛选出更有效的信息。详细内容将在6.3节介绍。
如何优化增强过程?讨论如何高效利用检索信息,主要包括:(1)何时增强,
确定何时需要检索增强,以提升效率并避免干扰信息;(2) 何处增强,讨论生成过程中插入检索信息的常见位置;(3) 多次增强,针对复杂与模糊查询,讨论常见的多次增强方式;(4) 降本增效,介绍现有的知识压缩和缓存加速策略。详细内容将在 6.4 节介绍。
本节初步介绍了我们为什么需要 RAG 和 RAG 是什么这两个问题。接下来的章节将针对上面提出的三个问题,对具体技术细节详细讨论。