2.4_基于Encoder-Decoder架构的大语言模型
2.4 基于 Encoder-Decoder 架构的大语言模型
Encoder-Decoder 架构在 Encoder-only 架构的基础上引入 Decoder 组件,以完成机器翻译等序列到序列(Sequence to Sequence, Seq2Seq)任务。本节将对 Encoder-Decoder 架构及其代表性模型进行介绍。
2.4.1 Encoder-Decoder 架构
Encoder-Decoder 架构主要包含编码器和解码器两部分。该架构的详细组成如图2.10所示。其中,编码器部分与 Encoder-only 架构中的编码器相同,由多个编码模块堆叠而成,每个编码模块包含一个自注意力模块以及一个全连接前馈模块。模型的输入序列在通过编码器部分后会被转变为固定大小的上下文向量,这个向量包含了输入序列的丰富语义信息。解码器同样由多个解码模块堆叠而成,每个解码模块由一个带掩码的自注意力模块、一个交叉注意力模块和一个全连接前馈模块组成。其中,带掩码的自注意力模块引入掩码机制防止未来信息的“泄露”,确保解码过程的自回归特性。交叉注意力模块则实现了解码器与编码器之间的信息交互,对于生成与输入序列高度相关的输出至关重要。
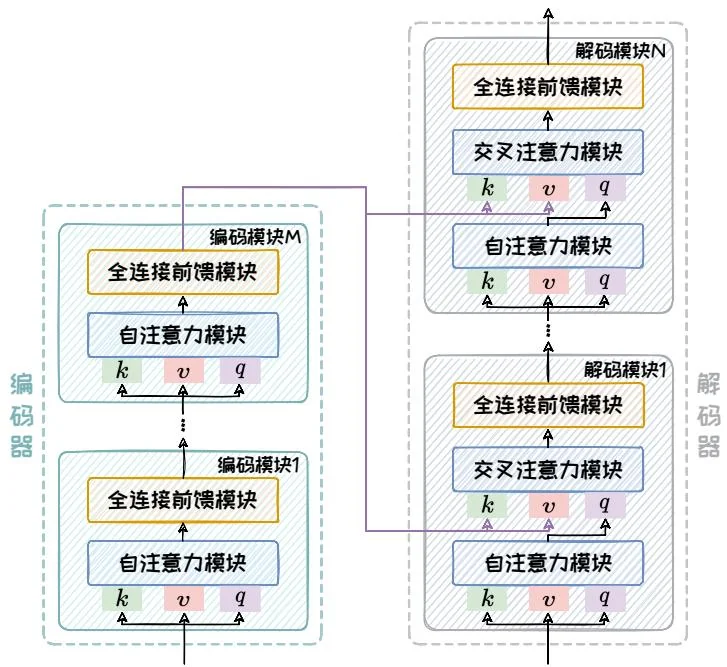
图2.10:Encoder-Decoder架构。
自注意模块在编码器和解码器中的注意力目标不同的。在编码器中,我们需要对输入序列的上下文进行“通盘考虑”,所以采用双向注意力机制以全面捕捉上下文信息。但在解码器中,自注意力机制则是单向的,仅以上文为条件来解码得到
下文,通过掩码操作避免解码器“窥视”未来的信息。交叉注意力通过将解码器的查询(query)与编码器的键(key)和值(value)相结合,实现了两个模块间的有效信息交流。
通过自注意力和交叉注意力机制的结合,Encoder-Decoder架构能够高效地编码输入信息并生成高质量的输出序列。自注意力机制确保了输入序列和生成序列内部的一致性和连贯性,而交叉注意力机制则确保了解码器在生成每个输出Token时都能参考输入序列的全局上下文信息,从而生成与输入内容高度相关的结果。在这两个机制的共同作用下,Encoder-Decoder架构不仅能够深入理解输入序列,还能够根据不同任务的需求灵活生成长度适宜的输出序列,在机器翻译、文本摘要、问答系统等任务中得到了广泛应用,并取得了显著成效。本节将介绍两种典型的基于Encoder-Decoder架构的代表性大语言模型:T5[29]和BART[18]。
2.4.2 T5语言模型
自然语言处理涵盖了语言翻译、文本摘要、问答系统等多种任务。通常,每种任务都需要对训练数据、模型架构和训练策略进行定制化设计。这种定制化设计不仅耗时耗力,而且训练出的模型难以跨任务复用,导致开发者需要不断“重复造轮子”。为了解决这一问题,Google Research团队在2019年10月提出了一种基于Encoder-Decoder架构的大型预训练语言模型T5(Text-to-Text Transfer Transformer),其采用了统一的文本到文本的转换范式来处理多种任务。下面分别从模型结构、预训练方式以及下游任务三个方面对T5模型进行介绍。
1. T5模型结构
T5 模型的核心思想是将多种 NLP 任务统一到一个文本转文本的生成式框架中。在此统一框架下,T5 通过不同的输入前缀来指示模型执行不同任务,然后生成相应的任务输出,正如图2.11所示。这种方法可以视为早期的提示(Prompt)技
术的运用,通过构造合理的输入前缀,T5模型能够引导自身针对特定任务进行优化,而无需对模型架构进行根本性的改变。这种灵活性和任务泛化能力显著提高了模型的实用性,使其能够轻松地适应各类新的NLP任务。
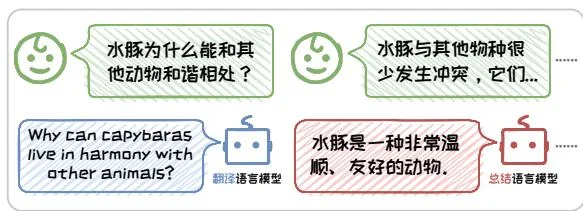
图2.11:传统语言模型和T5统一框架。
在模型架构方面,T5与原始的包括一个编码器和一个解码器的Transformer架构相同。每个编码器和解码器又分别由多个编码模块和解码模块堆叠而成。T5模型根据不同的具体参数,提供了五个不同的版本,分别是T5-Small、T5-Base、T5-Large、T5-3B以及T5-11B。T5-Small由6个编码模块和6个解码模块堆叠而成,其中隐藏层维度为512,自注意力头的数量为8,总参数数量约为6000万;T5-Base与BERT-Base对标,由12个编码模块和12个解码模块堆叠而成,其中隐藏层维度为768,自注意力头的数量为12,总参数数量约为2.2亿;T5-Large与BERT-Large对标,由24个编码模块和24个解码模块堆叠而成,隐藏层维度为1024,自注意力头的数量为16,总参数数量约为7.7亿;T5-3B在T5-Large的基础上,把自注意力头的数量扩大到32,另外还将全连接前馈网络的中间层维度扩大了4倍,总参数数量约为28亿;T5-11B在T5-3B的基础上,进一步将自注意力头的数量扩大到128,并又将全连接前馈网络的中间层维度扩大了4倍,总参数数量约为110亿。
2. T5预训练方式
为了获取高质量、覆盖范围广泛的预训练数据集,Google Research团队从大规模网页数据集CommonCrawl14中提取了大量的网页数据,并经过严格的清理和
过滤,最终生成了C4数据集(Colossal Clean Crawled Corpus),其覆盖了各种网站和文本类型,总规模达到了约750GB。
基于此数据集,T5 提出了名为 Span Corruption 的预训练任务。这一预训练任务从原始输入中选择 的 Token 进行破坏,每次都选择连续三个 Token 作为一个小段(span)整体被掩码成 [MASK]。与 BERT 模型中采用的单个 Token 预测不同,T5 模型需要对整个被遮挡的连续文本片段进行预测。这些片段可能包括连续的短语或子句,它们在自然语言中构成了具有完整意义的语义单元。这一设计要求模型不仅等理解局部词汇的表面形式,还要可以捕捉更深层次的句子结构和上下文之间的复杂依赖关系。Span Corruption 预训练任务显著提升了 T5 的性能表现,尤其是在文本摘要、问答系统和文本补全等需要生成连贯和逻辑性强的文本生成任务中。
3. T5下游任务
基于预训练阶段学到的大量知识以及新提出的文本转文本的统一生成式框架,T5模型可以在完全零样本(Zero-Shot)的情况下,利用Prompt工程技术直接适配到多种下游任务。同时,T5模型也可以通过微调(Fine-Tuning)来适配到特定的任务。但是,微调过程需要针对下游任务收集带标签训练数据,同时也需要更多的计算资源和训练时间,因此通常只被应用于那些对精度要求极高且任务本身较为复杂的应用场景。
综上所述,T5模型的文本转文本的统一生成式框架不仅简化了不同自然语言处理任务之间的转换流程,也为大语言模型的发展提供了新方向。如今,T5模型已经衍生了许多变体,以进一步改善其性能。例如,mT5[43]模型扩展了对100多种语言的支持,T0[31]模型通过多任务训练增强了零样本学习(Zero-Shot Learning)能力,Flan-T5[8]模型专注于通过指令微调,以实现进一步提升模型的灵活性和效率等等。
2.4.3 BART语言模型
BART(Bidirectional and Auto-Regressive Transformers)是由Meta AI研究院同样于2019年10月提出的一个Encoder-Decoder架构模型。不同于T5将多种NLP任务集成到一个统一的框架,BART旨在通过多样化的预训练任务来提升模型在文本生成任务和文本理解任务上的表现。
1. BART模型结构
BART的模型结构同样与原始的Transformer架构完全相同,包括一个编码器和一个解码器。每个编码器和解码器分别由多个编码模块和解码模块堆叠而成。BART模型一共有两个版本,分别是BART-Base以及BART-Large。BART-Base由6个编码模块和6个解码模块堆叠而成,其中隐藏层维度为768,自注意力头的数量为12,总参数数量约为1.4亿;BART-Large由12个编码模块和12个解码模块堆叠而成,其中隐藏层维度为1024,自注意力头的数量为16,总参数数量约为4亿。
2.BART预训练方式
在预训练数据上,BART使用了与RoBERTa[23]相同的语料库,包含小说数据集BookCorpus[46]、英语维基百科数据集15、新闻数据集CC-News16、网页开放数据集OpenWebText17以及故事数据集Stories,总数据量达到约160GB。
在预训练任务上,BART以重建被破坏的文本为目标。其通过Token遮挡任务(TokenMasking)、Token删除任务(TokenDeletion)、连续文本填空任务(TextInfilling)、句子打乱任务(SentencePermutation)以及文档旋转任务(DocumentRotation)等五个任务来破坏文本,然后训练模型对原始文本进行恢复。这种方式
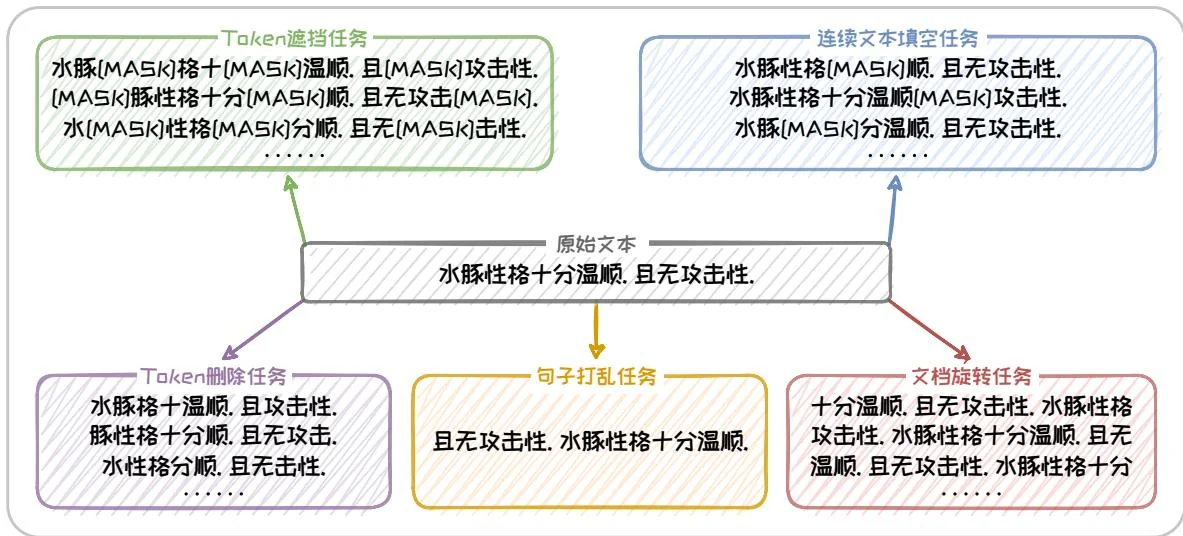
图2.12:BART预训练任务。
锻炼了模型对文本结构和语义的深入理解,增强了其在面对不完整或损坏信息时的鲁棒性。五个文本破坏任务的具体形式如下所述。
Token 遮挡任务 (Token Masking): 类似于 BERT 中的 MLM 任务, 在原始文本中随机采样一部分 Token 并将其替换为 [MASK], 从而训练模型推断被删除的 Token 内容的能力。
Token 删除任务 (Token Deletion): 在原始文本中随机删除一部分 Token, 从而训练模型推断被删除的 Token 位置以及内容的能力。
连续文本填空任务(Text Infilling):类似于 T5 的预训练任务,在原始文本中选择几段连续的 Token(每段作为一个 span),整体替换为 [MASK]。其中 span 的长度服从 的泊松分布,如果长度为 0 则直接插入一个 [MASK]。这一任务旨在训练模型推断一段 span 及其长度的能力。
句子打乱任务 (Sentence Permutation): 将给定文本拆分为多个句子, 并随机打乱句子的顺序。旨在训练模型推理前后句关系的能力。
文档旋转任务(Document Rotation):从给定文本中随机选取一个 Token,作为文本新的开头进行旋转。旨在训练模型找到文本合理起始点的能力。
在图2.12中,以给定文本“水豚性格十分温顺。且无攻击性。”为例,对这个五个任务进行演示。在预训练结束后,可以对BART进行微调使其能够将在预训练阶段学到的语言知识迁移到具体的应用场景中,适配多种下游任务。这种从预训练到微调的流程,使得BART不仅在文本生成任务上表现出色,也能够适应文本理解类任务的挑战。后续同样也出现了BART模型的各种变体,包括可处理跨语言文本生成任务的mBART[22]模型等。
综上所述,基于Encoder-Decoder架构的大语言模型,在生成任务中展示了良好的性能表现。表2.2从模型参数量和预训练语料规模的角度对本章提到的基于Encoder-Decoder架构的模型进行了总结。可以看出此时模型参数数量的上限已达110亿。在模型结构和参数规模的双重优势下,相较于基于Encoder-only架构的模型,这些模型在翻译、摘要、问答等任务中取得了更优的效果。
表 2.2: Encoder-Decoder 架构代表模型参数和语料大小表。