3.3_思维链
3.3 思维链
随着语言模型参数规模的持续扩张,其可以更好的捕捉语言特征和结构,从而在语义分析、文本分类、机器翻译等自然语言处理任务中的表现显著增强。但是,在面对算术求解、常识判断和符号推理等需要复杂推理能力的任务时,模型参数规模的增长并未带来预期的性能突破,这种现象被称作“Flat Scaling Curves”[38]。这表明,仅靠模型规模的扩大不足以解决所有问题,我们需要探索新的方法以提升模型的推理能力和智能水平。人类在解决复杂问题时,通常会逐步构建推理路径以导出最终答案。基于这一理念,一种创新的 Prompt 范式——思维链提示(Chain-of-Thought, CoT)[38] 被用于引导模型进行逐步推理。CoT 可以显著提升大语言模型处理复杂任务中的表现,从而突破“Flat Scaling Curves”的限制,激发大语言模型的内在推理潜能。
3.3.1 思维链提示的定义
思维链提示(Chain-of-Thought,CoT)[38]通过模拟人类解决复杂问题时的思考过程,引导大语言模型在生成答案的过程中引入一系列的中间推理步骤。这种方法不仅能够显著提升模型在推理任务上的表现,而且还能够揭示模型在处理复杂问题时的内部逻辑和推理路径。
CoT 方法的核心是构造合适的 Prompt 以触发大语言模型一步一步生成推理路径,并生成最终答案。早期方法在构造 Prompt 时,加入少量包含推理过程的样本示例(Few-Shot Demonstrations)[38],来引导模型一步一步生成答案。在这些示例中,研究者精心编写在相关问题上的推理过程,供模型模仿、学习。这种方法使得模型能够从这些示例中学习如何生成推理步骤,一步步输出答案。图 3.10 展示了一个用于求解数学问题的 CoT 形式的 Prompt 的例子。其中,样例给出了与待求

图3.10: 包含少量样本示例的 CoT 提示示例。
口:一只六白兔在森林里找到了12罐奶糖,然后它不小心打翻了4罐。之后,它又找到了6罐奶糖。六白兔总共找到了多少罐奶糖?
A:大白兔首先找到的奶糖数为12罐,打翻了4罐,剩下 罐,后来又找到6罐,所以,大白兔总共找到的奶糖数为 罐.
口:一只大象在森林里找到了15瓶苏打水,它不小心打翻了5瓶。之后,它又找到了8瓶苏打水,但不小心又打翻了2瓶。大象总共还剩下多少瓶苏打水?
A:大象最初找到的苏打水数为15瓶,打翻了5瓶,剩下 瓶。后来又找到8瓶,但再次打翻了2瓶,剩下 瓶。所以,大象总共剩下的苏打水数为 瓶。
□:浣熊爸爸有8包干腿面,给浣熊妈妈3包,然后把剩下的干腿面处理了,又获得了6包干腿面,自己吃了两包,剩下的都给小浣熊,请问小浣熊手里有几包干腿面?A:
浣熊爸爸最初有8包干腿面,给了浣熊妈妈3包,剩下 包。然后他处理了这5包干腿面,又获得了6包新的,吃了2包,剩下 包。所以,小浣熊手里有4包干腿面。

解问题相关的数学问题的解题步骤作为参考,大语言模型会模仿此样例对复杂的数学计算一步一步进行求解。通过引入 CoT,大语言模型在解算术求解、常识判断和符号推理等复杂问题上性能显著提升。并且在 CoT 的加持下,大语言模型处理复杂问题的能力随着模型参数规模的变大而增强。
在 CoT 核心思想的指引下,衍生出了一系列的扩展的方法。这些扩展的方法按照其推理方式的不同,可以归纳为三种模式:按部就班、三思后行和集思广益。这几种模式的对比如图 3.11 所示。
按部就班。在按部就班模式中,模型一步接着一步一步地进行推理,推理路径形成了一条逻辑连贯的链条。在这种模式下,模型像是在遵循一条预设的逻辑路径,“按部就班”的一步步向前。这种模式以 CoT [38]、Zero-Shot CoT [12]、Auto-CoT [46] 等方法为代表。
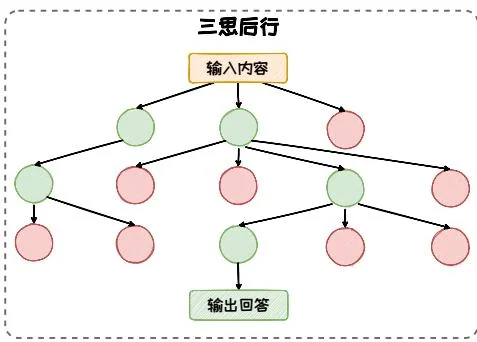
三思后行。在三思后行模式中,模型每一步都停下来估当前的情况,然后从多个推理方向中选择出下一步的行进方向。在这种模式下,模型像是在探索一片未知的森林,模型在每一步都会停下来评估周围的环境,“三思后行”以找出最佳推理路径。这种模式以 ToT [42]、GoT [1] 等方法为代表。

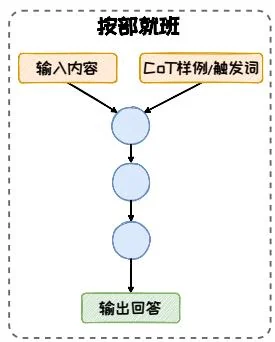
图3.11:不同CoT结构的对比。
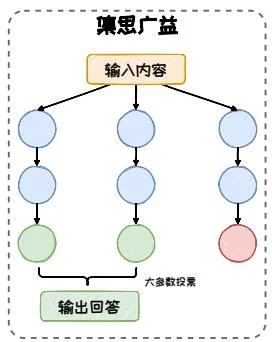
集思广益。在集思广益模式中,模型同时生成多条推理路径并得到多个结果,然后整合这些结果,得到一个更为全面和准确的答案。在这种模式下,模型像是在召开一场智者的会议,每个智者都带来了自己的见解,最终通过讨论和整合,“集思广益”得出一个更优的结论。这一类模式以 Self-Consistency [36]等方法为代表。
3.3.2 按部就班
按部就班模式强调的是逻辑的连贯性和步骤的顺序性。在这种模式下,模型一步接着一步的进行推理,最终得到结论。其确保了推理过程的清晰和有序,使得模型的决策过程更加透明和可预测。原始的少样本思维链(CoT)方法就采用了按部就班模式。其通过手工构造几个一步一步推理回答问题的例子作为示例放入Prompt中,来引导模型一步一步生成推理步骤,并生成最终的答案。这种方法在提升模型推理能力方面取得了一定的成功,但是需要费时费力地手工编写大量CoT示例,并且过度依赖于CoT的编写质量。针对这些问题,研究者在原始CoT的基础上进行了扩展,本节将介绍CoT的两种变体:Zero-Shot CoT和Auto-CoT。
1. Zero-Shot CoT
Zero-Shot CoT [12] 通过简单的提示,如“Let's think step by step”,引导模型自行生成一条推理链。其无需手工标注的 CoT 示例,减少了对人工示例的依赖,多个推理任务上展现出了与原始少样本 CoT 相媲美甚至更优的性能。

图3.12: Zero-Shot CoT提示的流程。
Zero-Shot CoT整体流程如图3.12所示,它使用两阶段方法来回答问题。首先,在第一阶段,在问题后面跟上一句“让我们一步一步思考”或者“Let's think step by step”来作为CoT的提示触发词,来指示大语言模型先生成中间推理步骤,再生成最后的答案。在第二阶段,把原始的问题以及第一阶段生成的推理步骤拼接在一起,在末尾加上一句“Thefore, the answer is”或者“因此,最终答案为”,把这些内容输给大语言模型,让他输出最终的答案。通过这样的方式,无需人工标注CoT数据,即可激发大语言模型内在的推理能力。大语言模型能够逐步推理出正确的答案,展现了Zero-Shot CoT在提升模型推理能力方面的潜力。
2. Auto CoT
在Zero-Shot CoT的基础之上,Auto-CoT[46]引入与待解决问题相关的问题及其推理链作为示例,以继续提升CoT的效果。相关示例的生成过程是由大语言模型自动完成的,无需手工标注。Auto-CoT的流程如图3.13所示,其包含以下步骤:
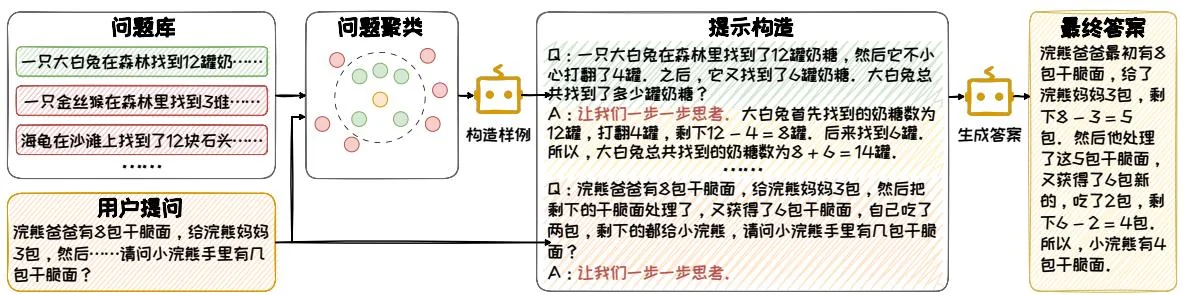
图3.13: Auto-CoT提示的流程。
利用聚类技术从问题库中筛选出与用户提问位于一个簇中的问题。
然后,借助Zero-Shot CoT的方式,为筛选出的问题生成推理链,形成示例。这些示例包含了不同问题及其对应的推理内容,可为模型提供不同解题思路,辅助模型做出更为审慎的推理。
在这些示例的基础上,Auto-CoT 以“让我们一步一步思考”引导大语言模型生成针对用户问题的推理链和答案。
3.3.3 三思后行
三思后行模式强调的是在决策过程中的融入审慎和灵活性。在这种模式下,模型在每一步都会停下来评估当前的情况,判断是否需要调整推理方向。这种模式的核心在于允许模型在遇到困难或不确定性时进行回溯和重新选择,确保决策过程的稳健性和适应性。其模仿了人类在解决问题时,会有一个反复选择回溯的过程。人们会不断从多个候选答案中选择最好的那个,并且如果一条思维路子走不通,就会回溯到最开始的地方,选择另一种思维路子进行下去。基于这种现实生活 的观察,研究者在CoT的基础上提出了思维树(Tree of Thoughts, ToT)[42]、思维图(Graph of Thoughts, GoT)[1]等三思后行模式下的CoT变体。
ToT 将推理过程构造为一棵思维树,其从以下四个角度对思维树进行构造。
拆解。将复杂问题拆分成多个简单子问题,每个子问题的解答过程对应一个思维过程。思维过程拆解的形式和粒度依任务类别而定,例如在数学推理任务上以一行等式作为一个思维过程,在创意写作任务上以内容提纲作为思维过程。
衍生。模型需要根据当前子问题生成可能的下一步推理方向。衍生有两种模式:样本启发和命令提示。样本启发以多个独立的示例作为上下文,增大衍生空间,适合于创意写作等思维空间宽泛的任务;命令提示在 Prompt 中指明规则和要求,限制衍生空间,适用于 24 点游戏等思维空间受限的任务。
评估。利用模型评估推理节点合理性。根据任务是否便于量化评分,选择投票或打分模式。投票模式中,模型在多节点中选择,依据票数决定保留哪些节点;打分模式中,模型对节点进行评分,依据评分结果决定节点的保留。
搜索。从一个或多个当前状态出发,搜索通往问题解决方案的路径。依据任务特点选择不同搜索算法。可以使用深度优先搜索、广度优先搜索等经典搜索算法,也可以使用 搜索、蒙特卡洛树搜索等启发式搜索算法。
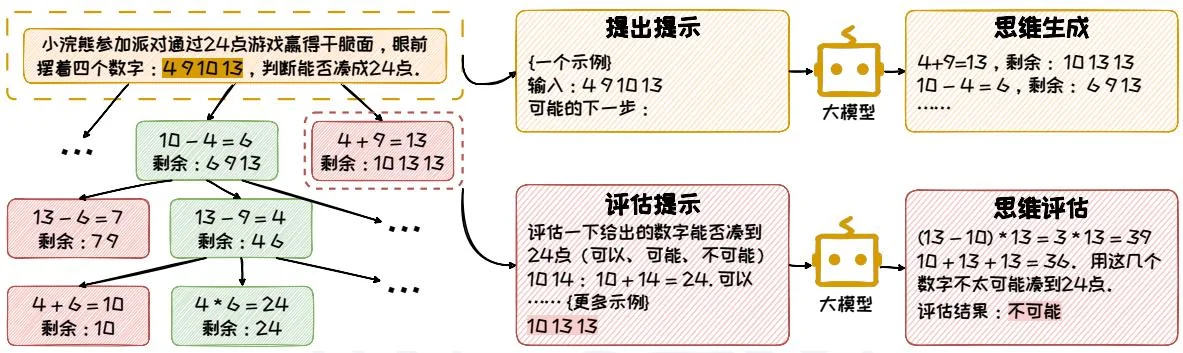
图3.14:ToT提示的流程。
图3.14通过24点游戏展示了一个ToT的具体例子。在这个例子中,给定4个数字,然后让大语言模型利用加减乘除(+/-/)四个运算符来组合这四个数字,使得最终的运算结果为24。首先,ToT基于当前所剩下的数字,通过上下文学习让模型选择两个数字作运算,并生成多个方案,在图上表现为思维树的多个子节点。之后以广度优先搜搜的方式遍历每一个子节点,评估当前剩余的数字是否能够凑到24点,保留可能凑出24点的节点,这一步也是通过上下文学习的方式来实现的。不断重复上述两个步骤,直到得出最终合理的结果。
在 ToT 的基础上,GoT 将树扩展为有向图,以提供了每个思维自我评估修正以及思维聚合的操作。该图中,顶点代表某个问题(初始问题、中间问题、最终问题)的一个解决方案,有向边代表使用“出节点”作为直接输入,构造出思维“入节点”的过程。GoT 相比于 ToT 的核心优势是其思维自我反思,以及思维聚合的能力,能够将来自不同思维路径的知识和信息进行集成,形成综合的解决方案。
3.3.4 集思广益
集思广益模式强调的是通过汇集多种不同的观点和方法来优化决策过程。在这种模式下,模型不仅仅依赖于单一的推理路径,而是通过探索多种可能的解决方案,从中选择最优的答案。这种方法借鉴了集体智慧的概念,即通过整合多个独立的思考结果,可以得到更全面、更准确的结论。在集体智慧的启发下,研究者在CoT的基础上探讨了如何通过自洽性来增强模型的推理能力,提出了Self-Consistency[36]方法。其引入多样性的推理路径并从中选择最一致的答案,从而提高了模型的推理准确性。Self-Consistency不依赖于特定的CoT形式,可以与其他CoT方法兼容,共同作用于模型的推理过程。
如图3.15所示,Self-Consistency的实现过程可以分为三个步骤:(1)在随机采样策略下,使用CoT或Zero-Shot CoT的方式来引导大语言模型针对待解决问题生成一组多样化的推理路径;(2)针对大语言模型生成的每个推理内容,收集其最终的答案,并统计每个答案在所有推理路径中出现的频率;(3)选择出现频率最高的答案作为最终的、最一致的答案。

图3.15: Self-Consistency的流程。
本节探讨了思维链(Chain-of-Thought, CoT)的思想和模式。CoT的核心思想是在提示中模拟人类解决问题的思考过程,在Prompt中嵌入解决问题的推理过程,从而在无需特定任务微调的情况下显著提升模型在推理任务上的表现。CoT方法包含了多种模式:按部就班、按部就班以及集思广益。这些模式可以满足不同的推理需求,增强了大语言模型在复杂任务中的推理能力。