3.5_相关应用
3.5 相关应用
Prompt 工程的应用极为广泛,几乎涵盖了所有需要与大语言模型进行高效交互的场景。这项技术不仅能够帮助我们处理一些基础任务,还能显著提升大语言模型在应对复杂任务时的表现。Prompt 工程在构建 Agent 完成复杂任务、进行数据合成、Text-to-SQL 转换,以及设计个性化的 GPTs 等方面,发挥着不可或缺的作用。下面我们将依次介绍 Prompt 工程在这些应用场景中的具体作用。
3.5.1 基于大语言模型的 Agent
智能体(Agent)是一种能够自主感知环境并采取行动以实现特定目标的实体[35]。作为实现通用人工智能(AGI)的有力手段,Agent被期望能够完成各种复杂任务,并在多样化环境中表现出类人智能。然而,以往的Agent通常依赖简单的启发式策略函数,在孤立且受限的环境中进行学习和操作,这种方法难以复制人类水平的决策过程,限制了Agent的能力和应用范围。近年来,大语言模型的不断
发展,涌现出各种能力,为 Agent 研究带来了新的机遇。基于大语言模型的 Agent(以下统称 Agent)展现出了强大的决策能力。其具备全面的通用知识,可以在缺乏、训练数据的情况下,也能进行规划、决策、工具调用等复杂的行动。
Prompt 工程技术在 Agent 中起到了重要的作用。在 Agent 系统中,大语言模型作为核心控制器,能够完成规划、决策、行动等操作,这些操作很多都依赖 Prompt 完成。图 3.30 展示了一个经典的 Agent 框架,该框架主要由四大部分组成:配置模块 (Profile)、记忆模块 (Memory)、计划模块 (Planning) 和行动模块 (Action) [35]。Prompt 工程技术贯穿整个 Agent 流程,为每个模块提供支持。
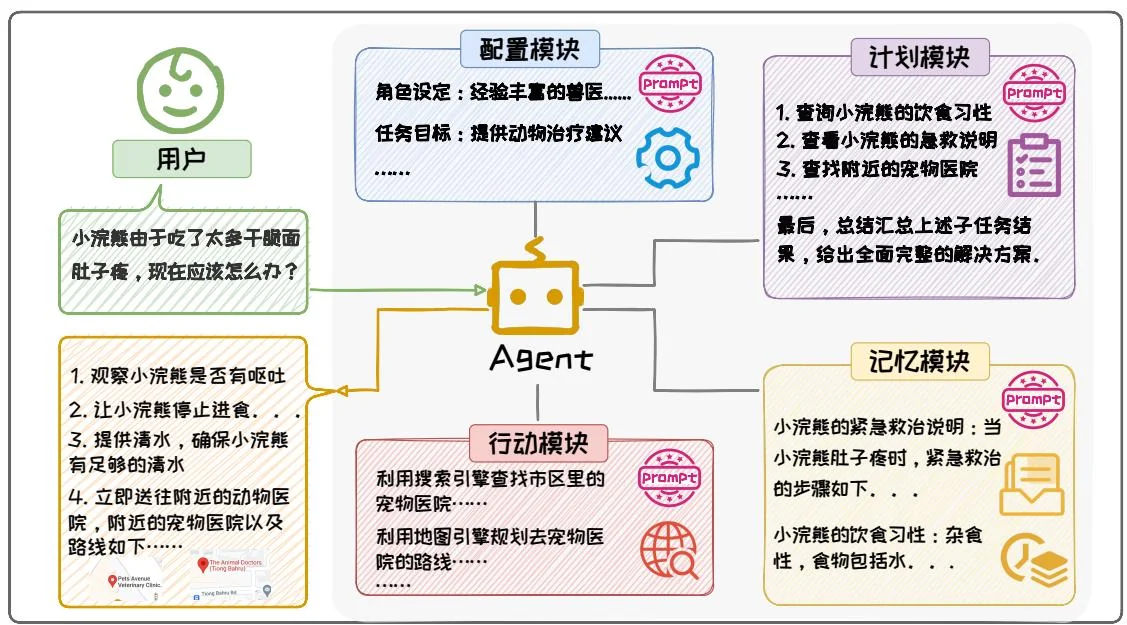
图3.30:基于大语言模型的Agent框架流程示意图。
在 Agent 中,上述四个组件各司其职,分工协作,共同完成复杂任务:(1)配置模块利用 Prompt 工程中的角色扮演技术,来定义 Agent 的角色。设定 Agent 的背景、技能、职责等信息,这些角色设定信息以上下文的形式嵌入到 Agent 每一次交互的 Prompt 中。(2)记忆模块是 Agent 的知识与交互记忆的存储中心。记忆模块通过检索增强等技术获取记忆,这一过程涉及到使用 Prompt 工程中的上下文学
习技术来构造和优化查询,从而帮助更加精准检索到相关记忆。在获取记忆之后,将这些记忆将被添加到交互的 Prompt 中,帮助 Agent 利用这些记忆知识,实现更为准确高效的决策与行动。(3)计划模块则扮演着任务分解者的角色,它将复杂的任务细化为一系列更为简单、易于管理的子任务。在这一过程中,通过 Prompt 工程中的思维链技术,让大语言模型分解任务并进行规划,按照链式顺序输出子任务;同时还利用了上下文学习技术,构造少样本示例来调控分解出的子任务的粒度,确保整个任务流程的顺畅与高效。(4)行动模块负责将计划模块生成的计划转化为具体的行动步骤,并借助外部工具执行这些步骤以实现 Agent 的目标。通常会为 Agent 提供工具 API 的接口,把调用 API 接口的示例作为上下文,让大语言模型生成调用 API 的代码,之后执行这些代码,从而得到执行步骤的结果。
如图3.30展示了一个小浣熊健康助理Agent处理用户请求“小浣熊由于吃了太多干脆面肚子疼,现在应该怎么办?”的流程。在这个例子中,首先,配置模块为Agent设定了明确的角色定位——经验丰富的兽医,并明确了任务目标为提供专业的动物治疗建议。为确保角色设定与任务目标的一致性,相关信息始终以下下文形式嵌入至输入给大语言模型的Prompt中,从而为后续处理奠定坚实基础。其次,计划模块根据用户的具体请求,精心规划了救助小浣熊的行动方案。该模块将整体任务细化为多个子任务,包括搜寻小浣熊的相关资料及救助信息、查找附近的宠物医院以及总结各个子任务的执行结果以给出全面回答等。接着,记忆模块从知识库中搜寻小浣熊的相关信息,包括小浣熊饮食习性、如何急救小浣熊等,提供了必要的背景知识支持。然后,行动模块通过调用搜索工具,迅速搜索到附近最近的宠物医院,并调用地图工具规划出最佳的送医路线。最后,计划模块将多个子任务的执行结果进行汇总,并综合考虑各种因素,执行最佳行动方案。该方案不仅包括观察小浣熊的行为、提供专业的照顾建议,还详细阐述了如何为小浣熊紧急送医的步骤,以生动形象的方式向用户展示整个救助过程。
基于大语言模型的 Agent,在不同行业和应用场景都展现出了巨大的潜力。斯坦福大学利用 GPT-4 模拟了一个虚拟的西部小镇 [25]。他们创建了一个虚拟环境,让多个基于 GPT-4 的 Agent 在其中生活和互动。这些 Agent 通过 Prompt 工程里面的角色扮演技术设定了不同的角色,如医生、教师和市长等,并根据自己的角色和目标自主行动,进行交流,解决问题,并推动小镇的发展。HuggingGPT [30] 则以 ChatGPT 为核心控制器,用户给定一个任务后,它首先将任务拆分为多个子任务,并从 Huggingface 上调用不同的模型来解决这些子任务。在得到子任务的结果之后,HuggingGPT 将这些结果汇总起来,返回最终结果,展现了其在复杂任务编排规划和模型调度协同方面的强大能力。这些 Agent 的研究不仅推动了大语言模型的发展与应用落地,也为 Agent 在现实世界中的应用提供了新的视角和方法。
3.5.2 数据合成
数据质量是制约大语言模型性能上限的关键要素之一,正所谓“Garbage in, Garbage Out”[27],无论模型架构多么优秀,训练算法多么优秀,计算资源多么强大,最终模型的表现都高度依赖于训练数据的质量。然而,获取高质量数据资源面临挑战。研究显示,公共领域的高质量语言数据,如书籍、新闻、科学论文和维基百科,预计将在2026年左右耗尽[33]。特定领域的垂直数据因隐私保护和标注难度高等问题,难以大量提供高质量数据,限制了模型的进一步发展。
面对这些挑战,数据合成作为一种补充或替代真实数据的有效手段,因其可控性、安全性和低成本等优势而受到广泛关注。特别是利用大语言模型生成训练数据,已成为当前研究的热点议题,其通过Prompt工程技术,利用大语言模型强大的思维能力、指令跟随能力,来合成高质量数据,其中一个代表性方法是Self-Instruct[37]。Self-Instruct通过Prompt工程技术构建Prompt,通过多步骤调用大语言模型,并依据已有的少量指令数据,合成大量丰富且多样化的指令数据。以金融
场景为例,我们可以先人工标注少量金融指令数据(如数百条),例如“请根据提供的几只基金情况,为我挑选出最佳基金”。随后,我们运用 Self-Instruct 方法调用大语言模型,我们能够将这些数据扩展至数万条,且保持高质量和多样性,如生成“请指导我如何选择股票和基金进行投资”等指令。
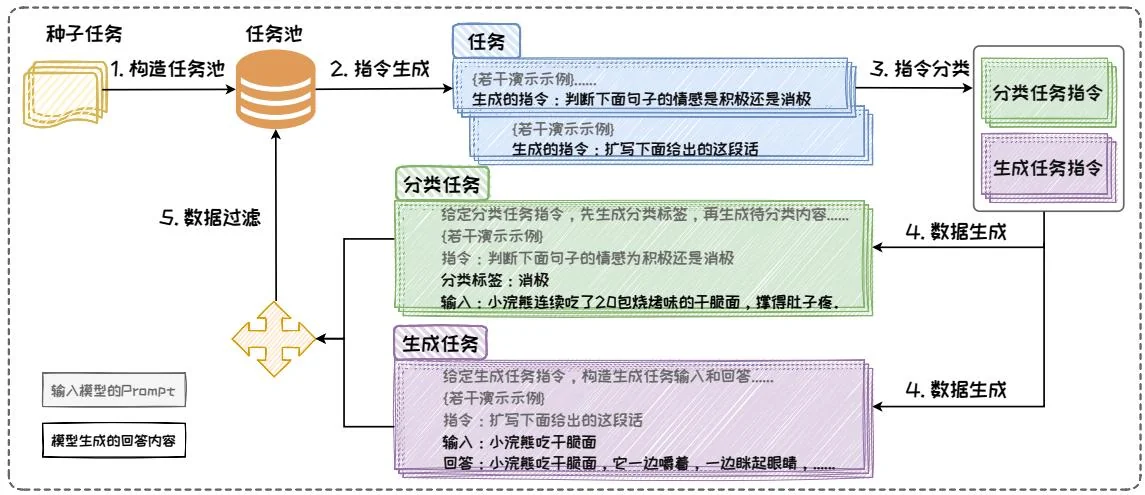
图3.31: Self-Instruct流程示例图。
如图3.31所示,Self-Instruct包含构建任务池、指令生成、指令分类、数据生成、数据过滤五个步骤。任务池存储了初始的指令数据以及存储后续生成的指令数据;指令生成负责参考任务池中的样例,生成指令数据中的指令部分;指令分类将生成的指令分类为分类任务或生成任务,在这两种任务模式下,生成数据的方式不同;数据生成则根据已有的指令,生成指令数据中的输入部分和回答部分;数据过滤则复杂去除低质量的数据,保证生成的指令数据质量。它从一个有限的手动编写任务种子集开始,通过与大语言模型交互,不断生成指令数据,扩充原始的数据集。
构建任务池。人工手工设计了 175 个指令数据集,作为初始任务池,后续模型会不断参考任务池的示例,来生成指令数据,并将生成的指令数据加入任务池中。
• 2. 指令生成。从任务池中随机抽取 8 个现有指令作为演示示例组成 Prompt 中的上下文, 以少样本学习的方式构造 Prompt 让模型生成指令。图中生成了两个指令: “扩写下面给出的这段话” 和 “判断下面句子的情感为积极还是消极”。
• 3. 指令分类。编写若干条“指令-分类任务/生成任务”样例对,作为上下文构造 Prompt,让模型判断该指令对应的任务是分类任务还是生成任务。图中“扩写下面给出的这段话”和“判断下面句子的情感为积极还是消极”分别被分类为生成任务和分类任务。
4. 数据生成。对分类任务和生成任务使用 Prompt 工程中的上下文学习技术,构造不同的 Prompt 来生成指令数据中的输入部分和回答部分。对于“扩写下面给出的这段话”这条指令,它是分类任务,在 Prompt 中指示模型先生成类别标签,再生成相应的输入内容,从而使得生成的输入内容更加偏向于该类别标签;对于“判断下面句子的情感为积极还是消极”这条指令,它是生成任务,在 Prompt 中指示模型先生成输入内容,再生成对应的回答。
数据过滤。通过设置各种启发式方法过滤低质量或者高重复度的指令数据,然后将剩余的有效任务添加到任务池中。
上述过程中,第二步到第五步不断循环迭代,直到任务池中收集到足够的数据时停止。
数据合成的意义在于,它不仅能够缓解高质量数据资源的枯竭问题,还能通过生成多样化的数据集,提高模型的泛化能力和鲁棒性。此外,数据合成还能在保护隐私的前提下,为特定领域的垂直数据提供有效的补充。并且,通过利用大型语言模型进行数据合成,生成的数据可以用于微调小型模型,显著提升其效果,实现模型蒸馏。
3.5.3 Text-to-SQL
互联网技术进步带动数据量指数增长,目前金融、电商等各行业的海量高价值数据主要存储在关系型数据库中。从关系型数据库中查询数据需要使用结构化查询语言(Structured Query Language,SQL)进行编程。然而,SQL逻辑复杂复杂,编程难度较高,只有专业人员才能够熟练掌握,这为非专业人士从关系型数据库中查询数据设置了障碍。为了降低数据查询门槛,零代码或低代码来的数据查询接口亟待研究。Text-to-SQL技术可以将自然语言查询翻译成可以在数据库中执行的SQL语句,是实现零代码或低代码数据查询的有效途径。通过Text-to-SQL的方式,我们只需要动动嘴,用大白话就能对数据库进行查询,而不必自己编写SQL语句。这让广大普通人都可以自由操作数据库,挖掘数据库中隐含的数据价值。

图3.32: Text-to-SQL示例。
传统的 Text-to-SQL 方法通常使用预训练-微调的范式训练 Text-to-SQL 模型。这些方法需要大量训练数据,费时费力且难以泛化到新的场景。近年,大语言模型涌现出的代码生成能力,为零样本 Text-to-SQL 带来可能。图 3.32 展示了一个应用大语言模型进行零样本 Text-to-SQL 的例子。用户把问题输入给大语言模型,询问“小浣熊 “Peter” 的主人叫什么名字?”。“大语言模型会根据用户的问题,生成对应的 SQL 语句,即”SELECT a.name FROM Owners as a JOIN Raccoons as b ON
a OWNER_id = b OWNER_id WHERE b.name = 'Peter';"。随后,SQL语句可以在对应数据库中执行,得到用户提问的答案,并返回给用户。
最早使用大语言模型来做零样本 Text-to-SQL 的方法是 C3 [7]。C3 的核心在于 Prompt 工程的设计,给出了如何针对 Text-to-SQL 任务设计 Prompt 来优化生成效果。如图 3.33 所示,C3 由三个关键部分组成:清晰提示(Clear Prompting)、提示校准(Calibration with Hints)和一致输出(Consistent Output),分别对应模型输入、模型偏差和模型输出。
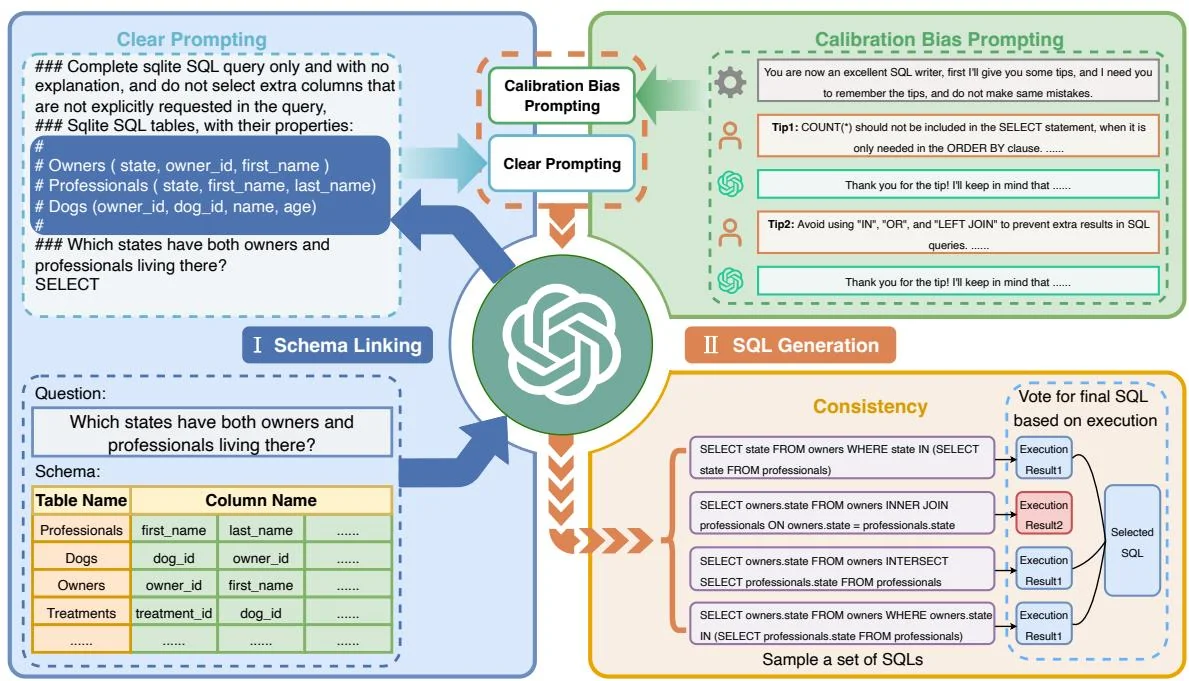
图3.33:C3方法整体框架图。
在模型输入端,C3 提出要采用 清晰提示(Clear Prompting)。其包含两部分:(1) 清晰布局(Clear Layout),通过明确符号划分指令、上下文和问题,确保指令模板清晰,显著提升 ChatGPT 对问题的理解能力。这一策略体现了 Prompt 技巧中的“排版清晰”原则,确保信息有效传递。(2) 清晰上下文(Clear Context),设计零样本 Prompt,指示 ChatGPT 从数据库中召回与问题相关的表和列。此举旨在检索关键信息,去除无关内容,减少上下文长度和冗余信息,从而提高生成 SQL
的准确性。这体现了 Prompt 技巧中“上下文丰富且清晰”的原则,确保了模型在处理任务时能够聚焦于关键信息。
为应对ChatGPT本身的固有偏差,C3中采用提示校准(Calibration with Hints)。通过插件式校准策略,利用包含历史对话的上下文提示,将先验知识纳入ChatGPT。在历史对话中,设定ChatGPT为优秀SQL专家角色,通过对话引导其遵循预设提示,通过这种角色扮演的方式,有效校准偏差。
在模型的输出端,C3采用输出校准(Output Calibration)来应对大语言模型固有的随机性。C3将Self-Consistency方法应用到Text-to-SQL任务上,对多种推理路径进行采样,选择最一致的答案,增强输出稳定性,保持SQL查询的一致性。
3.5.4 GPTS
GPTs是OpenAI推出的支持用户自定义的GPT应用,允许用户通过编写Prompt,添加工具等方式创建定制版的GPT应用,也可以使用别人分享的GPTs模型。
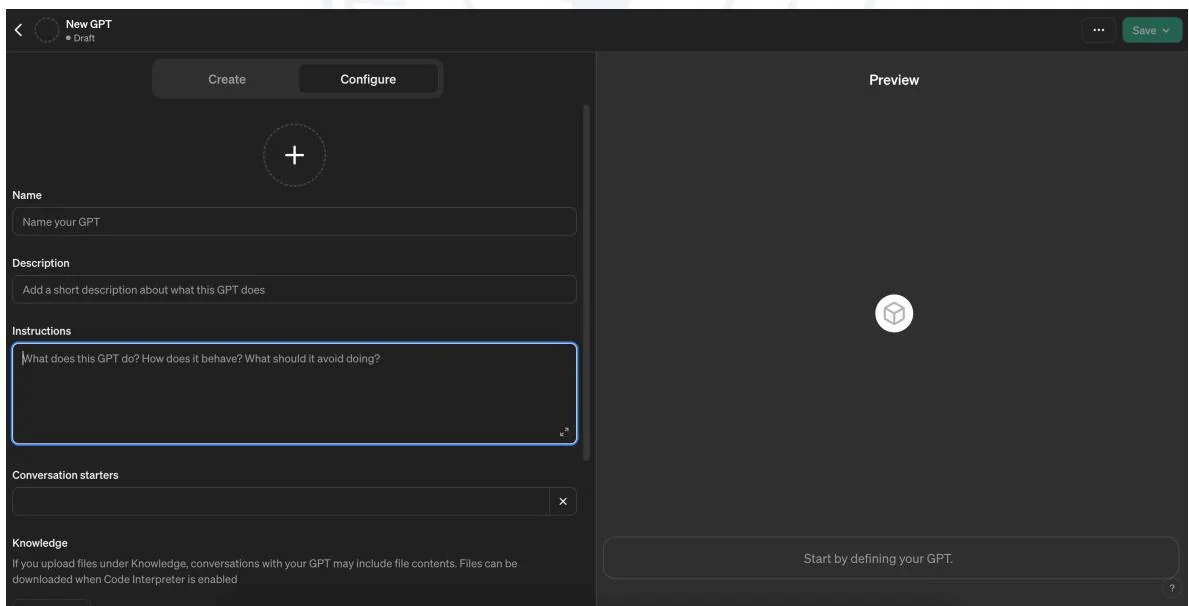
图3.34: 制作GPTS的页面图。
图3.34展示了如何制作GPTs。在这个专属页面中,用户拥有充分的自由度来自定义GPTs的能力和功能。通过“Description”指明该GPTs的功能,方便其他用户快速理解其功能和作用;而“Instructions”则是为GPTs预设Prompt,使得GPTs能够实现预期的功能。运用本章所介绍的Prompt工程技术编写这些关键内容,可以显著提高GPTs的性能。此外,用户还可以定制专属的知识库,并根据需求选择所需的能力,例如网络搜索、图像生成、代码解释等。完成个性化GPTs的制作后,用户可以选择将其分享,供其他用户使用。
在本节中,我们详细探讨了 Prompt 工程在多个领域中的具体应用场景应用场景。Prompt 工程在提升大语言模型的交互和执行能力方面具有重要作用。无论是在任务规划、数据合成、个性化模型定制,还是 Text-to-SQL 中,Prompt 工程都展现了其独特的优势和广阔的应用前景。
参考文献
[1] Maciej Besta et al. “Graph of Thoughts: Solving Elaborate Problems with Large Language Models”. In: AAAI. 2024.
[2] Tom B. Brown et al. "Language Models are Few-Shot Learners". In: arXiv preprint arXiv:2005.14165 (2020).
[3] Tom B. Brown et al. "Language Models are Few-Shot Learners". In: NeurIPS. 2020.
[4] Stephanie C. Y. Chan et al. "Data Distributional Properties Drive Emergent In-Context Learning in Transformers". In: NeurIPS. 2022.
[5] Aakanksha Chowdhery et al. “PaLM: Scaling Language Modeling with Pathways”. In: Journal of Machine Learning Research 24 (2023), 240:1–240:113.
[6] DeepSeek-AI et al. “DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model”. In: arXiv preprint arXiv:2405.04434 (2024).
[7] Xuemei Dong et al. "C3: Zero-shot Text-to-SQL with ChatGPT". In: arXiv preprint arXiv:2307.07306 (2023).
[8] Philip Gage. “A new algorithm for data compression”. In: The C User's Journal 12.2 (1994), pp. 23–38.
[9] Dan Hendrycks et al. “Measuring Massive Multitask Language Understanding”. In: ICLR. 2021.
[10] Sepp Hochreiter and Jürgen Schmidhuber. “Long Short-Term Memory”. In: Neural Computation 9.8 (1997), pp. 1735–1780.
[11] Huiqiang Jiang et al. "LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models". In: EMNLP. 2023.
[12] Takeshi Kojima et al. “Large Language Models are Zero-Shot Reasoners”. In: NeurIPS. 2022.
[13] Aobo Kong et al. “Better Zero-Shot Reasoning with Role-Play Prompting”. In: arXiv preprint arXiv:2308.07702 (2023).
[14] Jannik Kossen, Yarin Gal, and Tom Rainforth. “In-Context Learning Learns Label Relationships but Is Not Conventional Learning”. In: arXiv preprint arXiv:2307.12375 (2024).
[15] Junlong Li et al. "Self-Prompting Large Language Models for Zero-Shot Open-Domain QA". In: arXiv preprint arXiv:2212.08635 (2024).
[16] Xiaonan Li et al. “Unified Demonstration Retriever for In-Context Learning”. In: ACL. 2023.
[17] Jiachang Liu et al. “What Makes Good In-Context Examples for GPT-3?” In: ACL, 2022, pp. 100–114.
[18] Nelson F Liu et al. “Lost in the middle: How language models use long contexts”. In: Transactions of the Association for Computational Linguistics 12 (2024), pp. 157–173.
[19] Yao Lu et al. “Fantastically Ordered Prompts and Where to Find Them: Overcoming Few-Shot Prompt Order Sensitivity”. In: ACL. 2022.
[20] Man Luo et al. “In-context Learning with Retrieved Demonstrations for Language Models: A Survey”. In: arXiv preprint arXiv:2401.11624 (2024).
[21] Ziyang Luo et al. "Wizardcoder: Empowering code large language models with evol-instruct". In: arXiv preprint arXiv:2306.08568 (2023).
[22] Yuren Mao et al. “FIT-RAG: Black-Box RAG with Factual Information and Token Reduction”. In: arXiv preprint arXiv:2403.14374 (2024).
[23] Sewon Min et al. “Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?” In: EMNLP. 2022.
[24] Jane Pan et al. “What In-Context Learning”“Learns” In-Context: Disentangling Task Recognition and Task Learning”. In: ACL. 2023.
[25] Joon Sung Park et al. "Generative Agents: Interactive Simulacra of Human Behavior". In: UIST. 2023.
[26] Allan Raventós et al. “Pretraining task diversity and the emergence of non-Bayesian in-context learning for regression”. In: NeurIPS. 2023.
[27] L. Todd Rose and Kurt W. Fischer. “Garbage in, garbage out: Having useful data is everything”. In: Measurement: Interdisciplinary Research and Perspectives 9.4 (2011), pp. 224–226.
[28] Alexander Scarlatos and Andrew Lan. “RetICL: Sequential Retrieval of In-Context Examples with Reinforcement Learning”. In: arXiv preprint arXiv:2305.14502 (2024).
[29] Mike Schuster and Kaisuke Nakajima. "Japanese and korean voice search". In: ICASSP. 2012.
[30] Yongliang Shen et al. “HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face”. In: NeruIPS. 2023.
[31] Seongjin Shin et al. “On the Effect of Pretraining Corpora on In-context Learning by a Large-scale Language Model”. In: NAACL. 2022.
[32] Rohan Taori et al. “Alpaca: A strong, replicable instruction-following model”. In: Stanford Center for Research on Foundation Models. (2023).
[33] Pablo Villalobos et al. "Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning". In: arXiv preprint arXiv:2211.04325 (2022).
[34] Changhan Wang, Kyunghyun Cho, and Jiatao Gu. “Neural machine translation with byte-level subwords”. In: AAAI. 2020.
[35] Lei Wang et al. “A survey on large language model based autonomous agents”. In: Frontiers of Computer Science 18.6 (2024), p. 186345.
[36] Xuezhi Wang et al. "Self-Consistency Improves Chain of Thought Reasoning in Language Models". In: ICLR. 2023.
[37] Yizhong Wang et al. "Self-Instruct: Aligning Language Models with Self-Generated Instructions". In: ACL. 2023.
[38] Jason Wei et al. "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models". In: NeurIPS. 2022.
[39] Jason Wei et al. “Emergent Abilities of Large Language Models”. In: Transaction of Machine Learning Research 2022 (2022).
[40] Sang Michael Xie et al. “An Explanation of In-context Learning as Implicit Bayesian Inference”. In: ICLR. 2022.
[41] An Yang et al. “Qwen2 Technical Report”. In: arXiv preprint arXiv:2407.10671 (2024).
[42] Shunyu Yao et al. “Tree of Thoughts: Deliberate Problem Solving with Large Language Models”. In: NeurIPS. 2023.
[43] Kang Min Yoo et al. “Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations”. In: EMNLP. 2022.
[44] Tao Yu et al. "Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task". In: EMNLP. 2018.
[45] Chao Zhang et al. "FinSQL: Model-Agnostic LLMs-based Text-to-SQL Framework for Financial Analysis". In: SIGMOD. 2024.
[46] Zhuosheng Zhang et al. "Automatic Chain of Thought Prompting in Large Language Models". In: ICLR. 2023.
[47] Wayne Xin Zhao et al. “A Survey of Large Language Models”. In: arXiv preprint arXiv:2303.18223 (2023).
[48] Yuxiang Zhou et al. “The Mystery of In-Context Learning: A Comprehensive Survey on Interpretation and Analysis”. In: arXiv preprint arXiv:2311.00237 (2024).
4 参数高效微调
大语言模型从海量的预训练数据中掌握了丰富的世界知识。但“尺有所短”,对于预训练数据涉及较少的垂直领域,大语言模型无法仅通过提示工程来完成领域适配。为了让大语言模型更好的适配到这些领域,需要对其参数进行微调。但由于大语言模型的参数量巨大,微调成本高昂,阻碍了大语言模型在一些垂直领域的应用。为了降低微调成本,亟需实现效果可靠、成本可控的参数高效微调。本章将深入探讨当前主流的参数高效微调技术,首先简要介绍参数高效微调的概念、参数效率和方法分类,然后详细介绍参数高效微调的三类主要方法,包括参数附加方法、参数选择方法和低秩适配方法,探讨它们各自代表性算法的实现和优势。最后,本章通过具体案例展示参数高效微调在垂直领域的实际应用。