3.1_Motivating_example_How_to_improve_policies
3.1 Motivating example: How to improve policies?
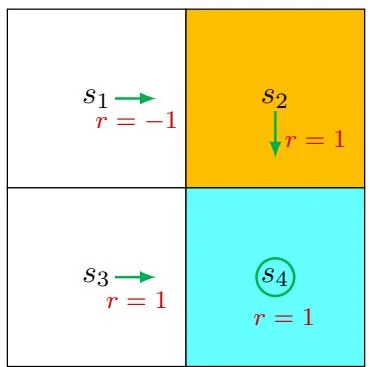
Figure 3.2: An example for demonstrating policy improvement.
Consider the policy shown in Figure 3.2. Here, the orange and blue cells represent the forbidden and target areas, respectively. The policy here is not good because it selects (rightward) in state . How can we improve the given policy to obtain a better policy? The answer lies in state values and action values.
Intuition: It is intuitively clear that the policy can improve if it selects (downward) instead of (rightward) at . This is because moving downward enables the agent to avoid entering the forbidden area.
Mathematics: The above intuition can be realized based on the calculation of state values and action values.
First, we calculate the state values of the given policy. In particular, the Bellman equation of this policy is
Let . It can be easily solved that
Second, we calculate the action values for state :
It is notable that action has the greatest action value:
Therefore, we can update the policy to select at .
This example illustrates that we can obtain a better policy if we update the policy to select the action with the greatest action value. This is the basic idea of many reinforcement learning algorithms.
This example is very simple in the sense that the given policy is only not good for state . If the policy is also not good for the other states, will selecting the action with the greatest action value still generate a better policy? Moreover, whether there always exist optimal policies? What does an optimal policy look like? We will answer all of these questions in this chapter.