7.5_A_unified_viewpoint
7.5 A unified viewpoint
Up to now, we have introduced different TD algorithms such as Sarsa, -step Sarsa, and Q-learning. In this section, we introduce a unified framework to accommodate all these algorithms and MC learning.
In particular, the TD algorithms (for action value estimation) can be expressed in a unified expression:
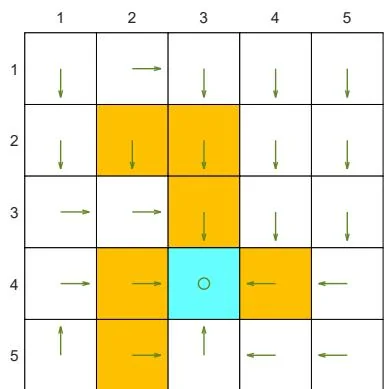
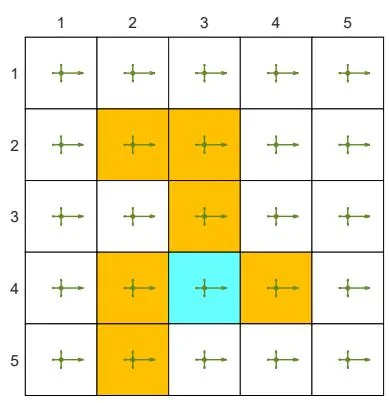
(a) Optimal policy
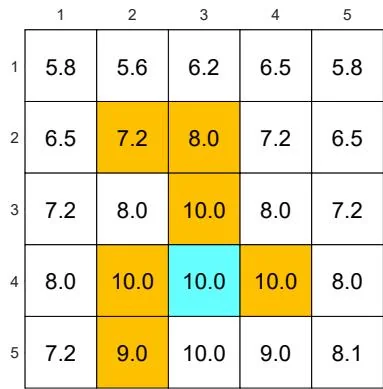
(b) Optimal state value
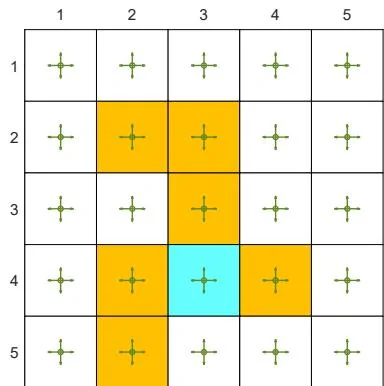
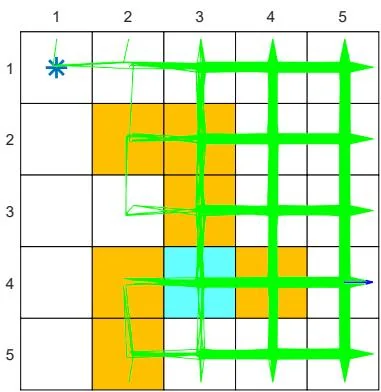
(c) Behavior policy
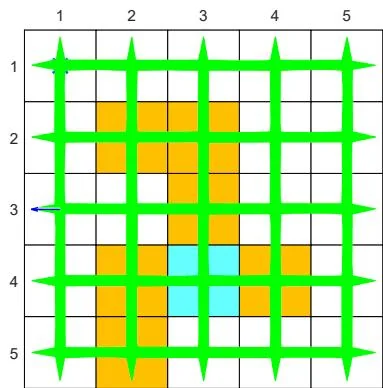
(d) Generated episode
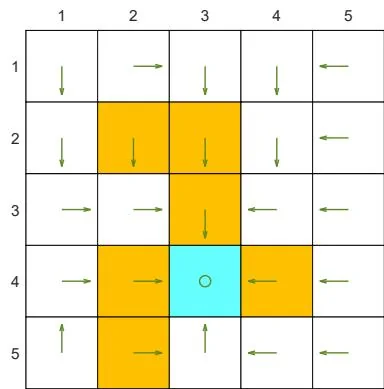
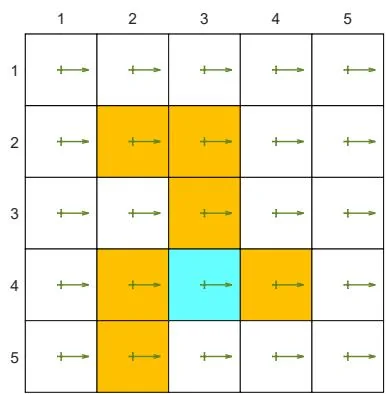
(e) Learned policy
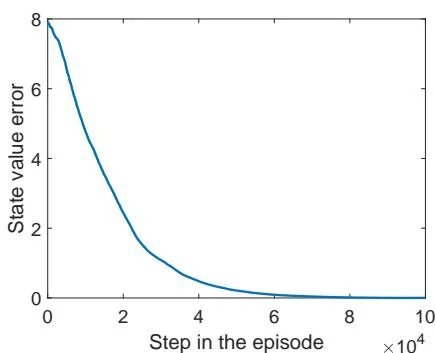
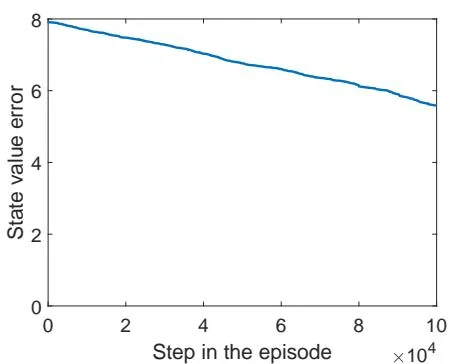
(f) State value error when
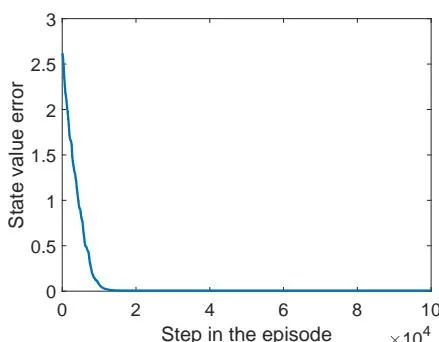
(g) State value error when
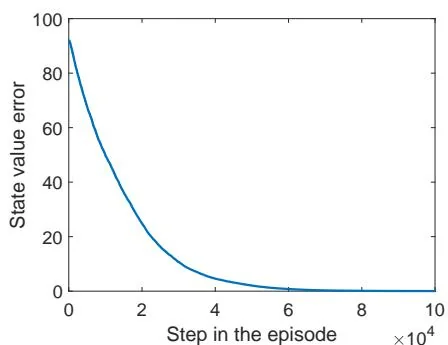
(h) State value error when
Figure 7.4: Examples for demonstrating off-policy learning via Q-learning. The optimal policy and optimal state values are shown in (a) and (b), respectively. The behavior policy and the generated episode are shown in (c) and (d), respectively. The estimated policy and the estimation error evolution are shown in (e) and (f), respectively. The cases with different initial values are shown in (g) and (h).
(a)
(b)
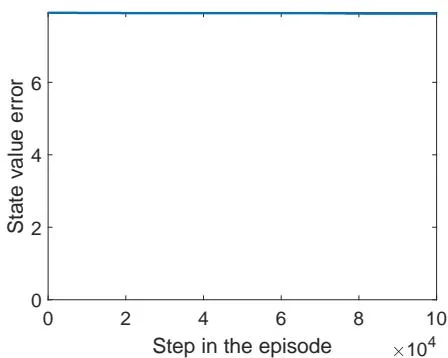
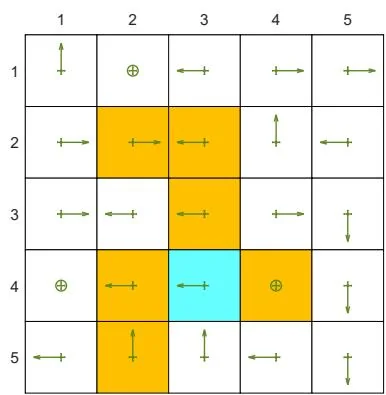
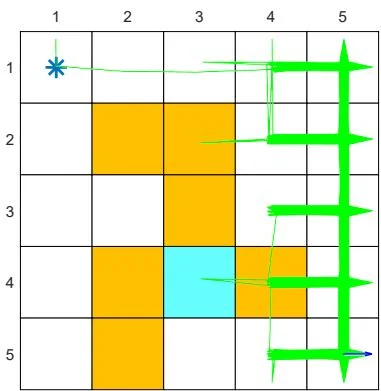
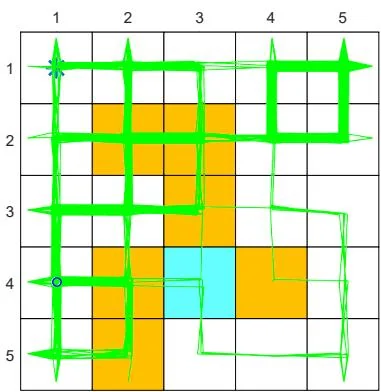
Figure 7.5: The performance of Q-learning drops when the behavior policy is not exploratory. The figures in the left column show the behavior policies. The figures in the middle column show the generated episodes following the corresponding behavior policies. The episode in each example has 100,000 steps. The figures in the right column show the evolution of the root-mean-square error of the estimated state values.
(c)
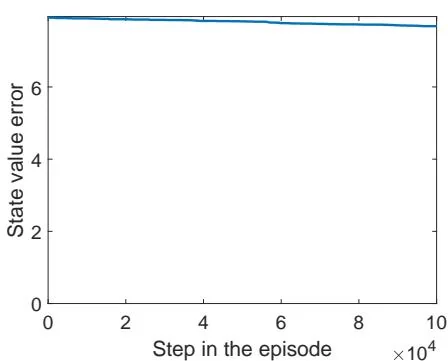
Table 7.2: A unified point of view of TD algorithms. Here, BE and BOE denote the Bellman equation and Bellman optimality equation, respectively.
where is the target. Different TD algorithms have different . See Table 7.2 for a summary. The MC learning algorithm can be viewed as a special case of (7.20): we can set and then (7.20) becomes .
Algorithm (7.20) can be viewed as a stochastic approximation algorithm for solving a unified equation: . This equation has different expressions with different . These expressions are summarized in Table 7.2. As can be seen, all of the algorithms aim to solve the Bellman equation except Q-learning, which aims to solve the Bellman optimality equation.