5.4_MC_epsilon-Greedy_Learning_without_exploring_starts
5.4 MC -Greedy: Learning without exploring starts
We next extend the MC Exploring Starts algorithm by removing the exploring starts condition. This condition actually requires that every state-action pair can be visited sufficiently many times, which can also be achieved based on soft policies.
5.4.1 -greedy policies
A policy is soft if it has a positive probability of taking any action at any state. Consider an extreme case in which we only have a single episode. With a soft policy, a single episode that is sufficiently long can visit every state-action pair many times (see the examples in Figure 5.8). Thus, we do not need to generate a large number of episodes starting from different state-action pairs, and then the exploring starts requirement can be removed.
One type of common soft policies is -greedy policies. An -greedy policy is a stochastic policy that has a higher chance of choosing the greedy action and the same nonzero probability of taking any other action. Here, the greedy action refers to the action with the greatest action value. In particular, suppose that . The corresponding -greedy policy has the following form:
where denotes the number of actions associated with .
When , -greedy becomes greedy. When , the probability of taking any action equals .
The probability of taking the greedy action is always greater than that of taking any
other action because
for any .
While an -greedy policy is stochastic, how can we select an action by following such a policy? We can first generate a random number in by following a uniform distribution. If , then we select the greedy action. If , then we randomly select an action in with the probability of (we may select the greedy action again). In this way, the total probability of selecting the greedy action is , and the probability of selecting any other action is .
5.4.2 Algorithm description
To integrate -greedy policies into MC learning, we only need to change the policy improvement step from greedy to -greedy.
In particular, the policy improvement step in MC Basic or MC Exploring Starts aims to solve
where denotes the set of all possible policies. We know that the solution of (5.4) is a greedy policy:
where
Now, the policy improvement step is changed to solve
where denotes the set of all -greedy policies with a given value of . In this way, we force the policy to be -greedy. The solution of (5.5) is
where . With the above change, we obtain another algorithm called . The details of this algorithm are given in Algorithm 5.3. Here, the every-visit strategy is employed to better utilize the samples.
Algorithm 5.3: MC -Greedy (a variant of MC Exploring Starts)
Initialization: Initial policy and initial value for all . Returns and for all .
Goal: Search for an optimal policy.
For each episode, do
Episode generation: Select a starting state-action pair (the exploring starts condition is not required). Following the current policy, generate an episode of length : . Initialization for each episode:
For each step of the episode, do
Returns
Policy evaluation:
Policy improvement:
Let and
If greedy policies are replaced by -greedy policies in the policy improvement step, can we still guarantee to obtain optimal policies? The answer is both yes and no. By yes, we mean that, when given sufficient samples, the algorithm can converge to an -greedy policy that is optimal in the set . By no, we mean that the policy is merely optimal in but may not be optimal in . However, if is sufficiently small, the optimal policies in are close to those in .
5.4.3 Illustrative examples
Consider the grid world example shown in Figure 5.5. The aim is to find the optimal policy for every state. A single episode with one million steps is generated in every iteration of the MC -Greedy algorithm. Here, we deliberately consider the extreme case with merely one single episode. We set , , and .
The initial policy is a uniform policy that has the same probability 0.2 of taking any action, as shown in Figure 5.5. The optimal -greedy policy with can be obtained after two iterations. Although each iteration merely uses a single episode, the policy gradually improves because all the state-action pairs can be visited and hence their values can be accurately estimated.
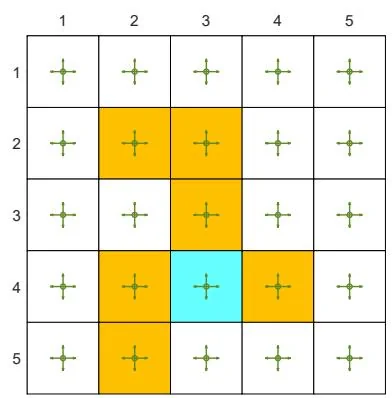
(a) Initial policy
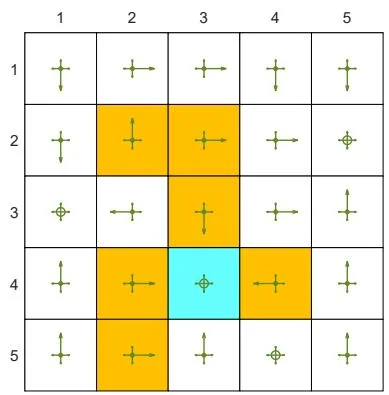
(b) After the first iteration
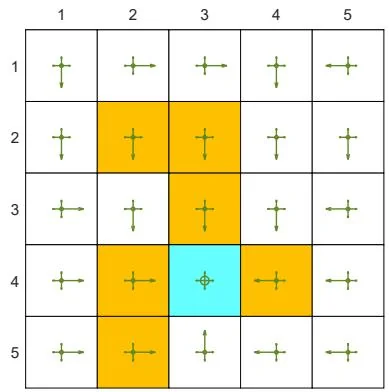
(c) After the second iteration
Figure 5.5: The evolution process of the MC -Greedy algorithm based on single episodes.