15.7_Performance_and_Further_Reading
15.7 Performance and Further Reading
Our sample program uses CUDA events to report the performance of some number of consecutive kernel launches (default 100) and reports the rates of both output coefficients (which varies with the template size) and the "template-pixel" rate, or the number of inner loop iterations per unit time.
The raw performance of GPUs at performing this computation is astonishing. A GeForce GTX 280 (GT200) can perform almost 25 billion template-pixel calculations per second (Gtpix/s), and the GeForce 680 GTX (GK104) delivers well over 100 Gtpix/s.
The default parameters of the program are not ideal for performance measurement. They are set to detect the dime in the lower right corner and optionally write out the image in Figure 15.3. In particular, the image is too small to keep the GPU fully busy. The image is only pixels (74K in size), so only 310 blocks are needed by the shared memory implementation to perform the computation. The --padWidth and --padHeight command-line options can be used in the sample program to increase the size of the image and thus the number of correlation coefficients computed (there are no data dependencies in the code, so the padding can be filled with arbitrary data); a image is both more realistic and gets best utilization out of all GPUs tested.
Figure 15.5 summarizes the relative performance of our 5 implementations.
corrTexTex: template and image both in texture memory
corrTexConstant: template in constant memory
corrShared: template in constant memory and image in shared memory
corrSharedSM: corrShared with SM-aware kernel invocations
corrShared4: corrSharedSM with the inner loop unrolled 4x
The various optimizations did improve performance, to varying degrees, as shown in Figure 15.6. Moving the template to constant memory had the biggest impact on GK104, increasing performance by ; moving the image to shared memory had the biggest impact on GF100, increasing performance by . The SM-aware kernel launches had the most muted impact, increasing performance on GT200 by (it does not affect performance on the other architectures, since using the built-in multiplication operator is also fastest).
On GT200, corrShared suffered from bank conflicts in shared memory, so much so that corrShared is slower than corrTexConstant; corrShared4 alleviates these bank conflicts, increasing performance by .
The size of the template also has a bearing on the efficiency of this algorithm: The larger the template, the more efficient the computation on a per-template-pixel basis. Figure 15.6 illustrates how the template size affects performance of the corrShared4 formulation.
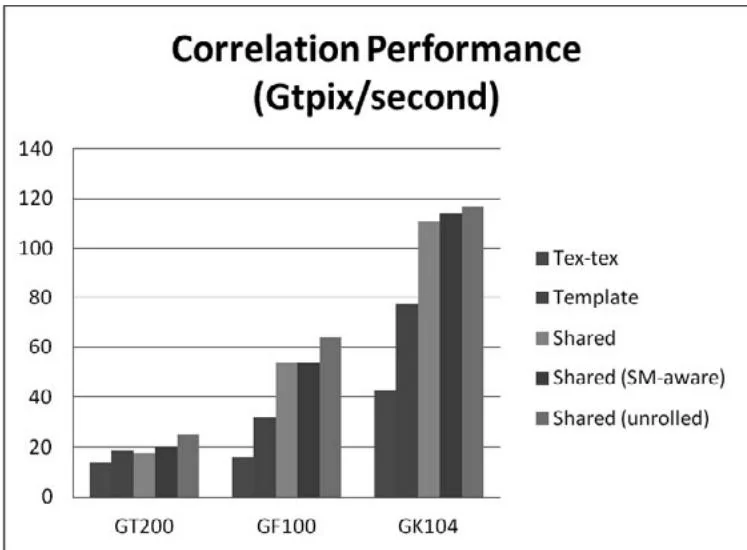
Figure 15.5 Performance comparison.
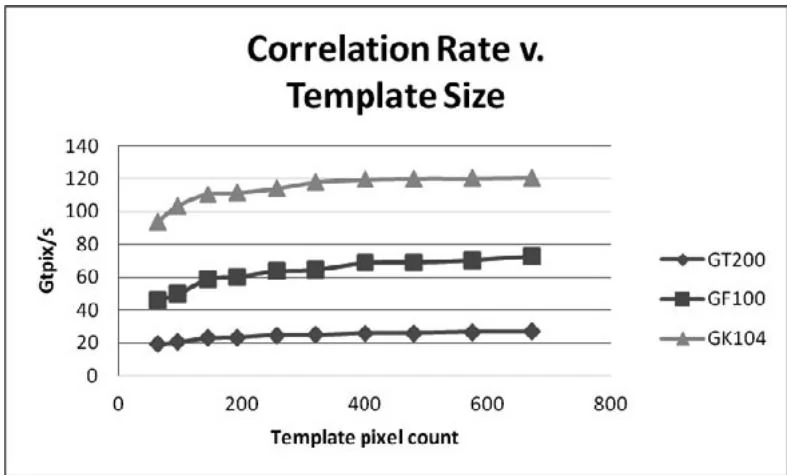
Figure 15.6 Correlation rate versus template size.
As the template grows from to , GT200 performance improves (19.6 Gtpix/s to 26.8 Gtpix/s), GF100 improves (46.5 Gtpix/s to 72.9 Gtpix/s), and GK104 improves (93.9 Gtpix/s to 120.72 Gtpix/s).
For small templates, the compiler generates faster code if the template size is known at compile time. Moving wTemplate and hTemplate to be template
parameters and specializing for an template improved performance as follows.