11.5_Performance_and_Summary
11.5 Performance and Summary
This chapter covers four different implementations of SAXPY, emphasizing different strategies of data movement.
Synchronous memcpy to and from device memory
Asynchronous memcpy to and from device memory
Asynchronous memcpy using streams
Mapped pinned memory
Table 11.1 and Figure 11.1 summarize the relative performance of these implementations for 128M floats on GK104s plugged into two different test systems: the Intel i7 system (PCI Express 2.0) and an Intel Xeon E5-2670 (PCI Express 3.0). The benefits of PCI Express 3.0 are evident, as they are about twice as fast. Additionally, the overhead of CPU/GPU synchronization is higher on the E5-2670, since the pageable memcpy operations are slower.
Table 11.1 Streaming Performance
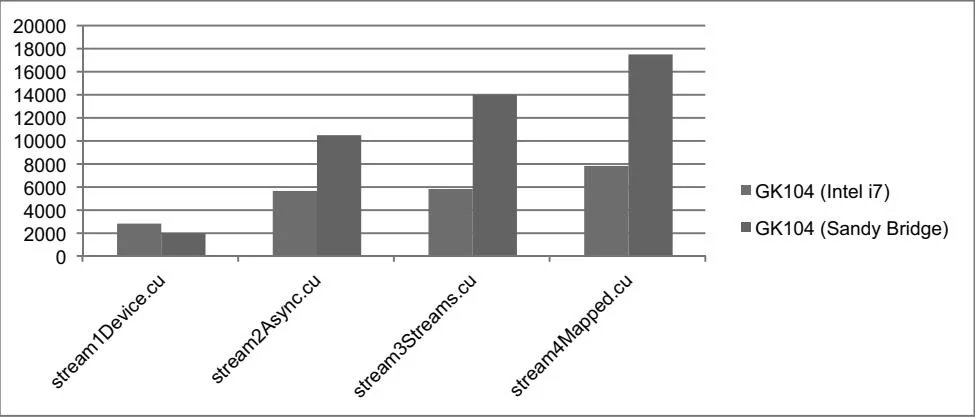
Figure 11.1 Bandwidth (GeForce GTX 680 on Intel i7 versus Sandy Bridge)
This page intentionally left blank
Reduction
Reduction is a class of parallel algorithms that pass over input data and generate a result computed with a binary associative operator . Examples of such operations include minimum, maximum, sum, sum of squares, AND, OR, and the dot product of two vectors. Reduction is also an important primitive used as a subroutine in other operations, such as Scan (covered in the next chapter).
Unless the operator is extremely expensive to evaluate, reduction tends to be bandwidth-bound. Our treatment of reduction begins with several two-pass implementations based on the reduction SDK sample. Next, the threadFenceReduction SDK sample shows how to perform reduction in a single pass so only one kernel must be invoked to perform the operation. Finally, the chapter concludes with a discussion of fast binary reduction with the __syncthreads_count() intrinsic (added with SM 2.0) and how to perform reduction using the warp shuffle instruction (added with SM 3.0).