6.2_异步的内存复制
6.2 异步的内存复制
像内核启动一样,异步的内存复制调用在GPU完成待处理的内存复制之前就会返回。由于GPU能够自主运行,并且可以在没有任何操作系统介入的情况下对主机的内存进行读或写操作,所以,只有锁页内存有资格进行异步的内存复制。
最早期CUDA包含异步内存复制的应用程序是隐藏在CUDA 1.0驱动程序下的。GPU不可以直接访问分页内存,所以驱动程序利用CUDA上下文分配的一对锁页的“临时缓冲区”实现分页的内存复制。图6-3显示了这个过程是如何工作的。
要执行主机端到设备端的内存复制,驱动程序首先通过复制到一个暂存缓冲区来“启动泵”,然后开始一个通过GPU读取那个数据的DMA操作。当GPU开始处理该请求时,驱动程序将更多的数据复制到其他中转缓冲区。CPU和GPU在2个中转缓冲区之间保持来回交互,以及适当的同步,直到GPU完成最后的内存复制。除了复制数据之外,在复制数据时CPU自然也会换进非驻留的页面。

“启动泵”:CPU复制数据到第一个缓冲区

2. 在CPU复制数据到第二个缓冲区的同时,GPU从第一个缓冲区读取数据

图6-3 分页的内存复制
3. 在CPU复制数据到第一缓冲区时GPU从第二个缓冲区读取数据
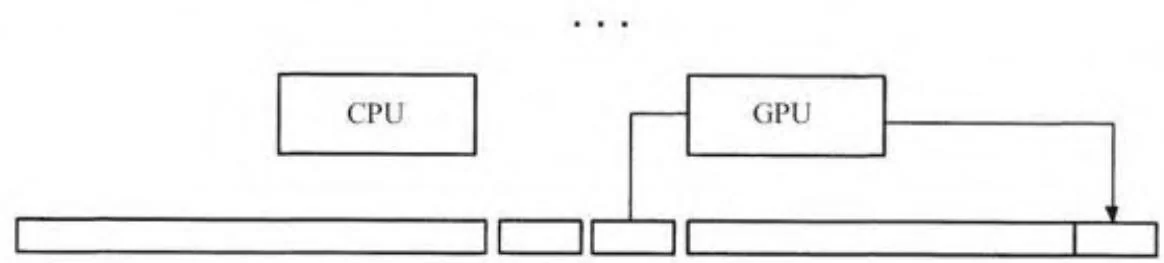
4.最终的GPU内存复制操作
图6- 3 (续)
6.2.1 异步的内存复制:主机端到设备端
正如内核启动一样,异步内存复制会引发驱动程序上的固定CPU开销。在主机到设备的内存复制情况下,所有小于一定尺寸的内存复制都是异步的,因为驱动程序直接把源数据复制到它用来控制硬件的命令缓冲器中。
我们可以写一个应用程序,测量异步的内存复制开销,就像我们早些时候测量内核启动开销一样。下面的代码,是在一个叫做nullHtoDMemcpyAsync.cu文件中的,报告了一个亚马逊EC2上的cgl.4xlarge实例的结果,每个内存复制花费3.3毫秒。由于PCIe几乎可以在那段时间里运行2000次传输,测量一个内存复制的时间如何随着尺寸变大而增长是有意义的。
CUDART_CHECK(udaMalloc(&deviceInt,sizeof(int)));
CUDART_CHECK(udaHostAlloc(&hostInt,sizeof(int),0));
chTimerGetTime(&start); for(int $\mathrm{i} = 0$ :i $<$ cIterations;i++){ CUDArt_CHECK(udaMemcpyAsync(deviceInt,hostInt,sizeof(int),udaMemcpyHostToDevice,NULL));
}
CUDART_CHECK(udaThreadSynchronize());
chTimerGetTime(&stop);breakevenHtoDmemcpy.cu程序测量内存复制大小从4K变到64K的性能。在一个亚马逊EC2中的cgl.4xlarge实例上,它会产生图6-4的效果。这个程序产生的数据非常清晰,足以符合线性回归曲线——在这种情况下,加上截距为3.3微秒,并且斜率为0.000170微秒/字节。斜率对应为5.9GB/s,大约为PCIe 2.0的理论带宽。
6.2.2 异步内存复制:设备端到主机端
nullDtoHmemcpyNoSync.cu和breakevenDtoHmemcpy.cu程序对于从设备端到主机端的小内存复制表现出相同的测量结果。在我们信赖的亚马逊EC2实例上,一个内存复制的最少时间是4.00微秒(见图6-5)。
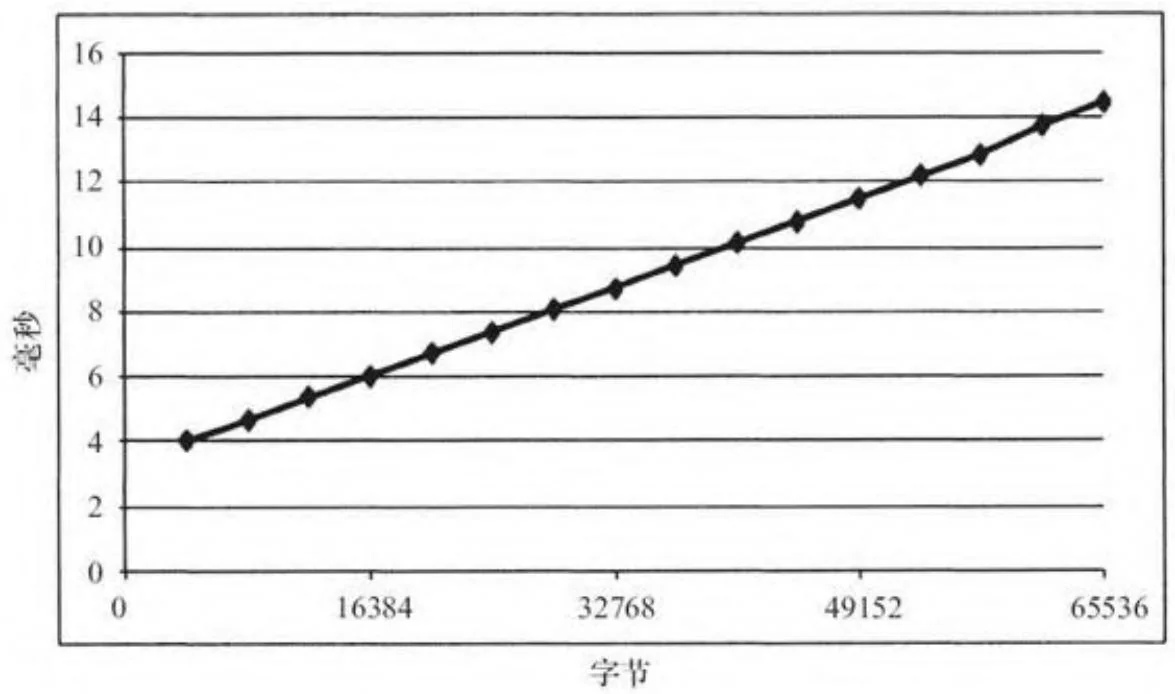
图6-4 从主机端到设备端的小内存复制的性能
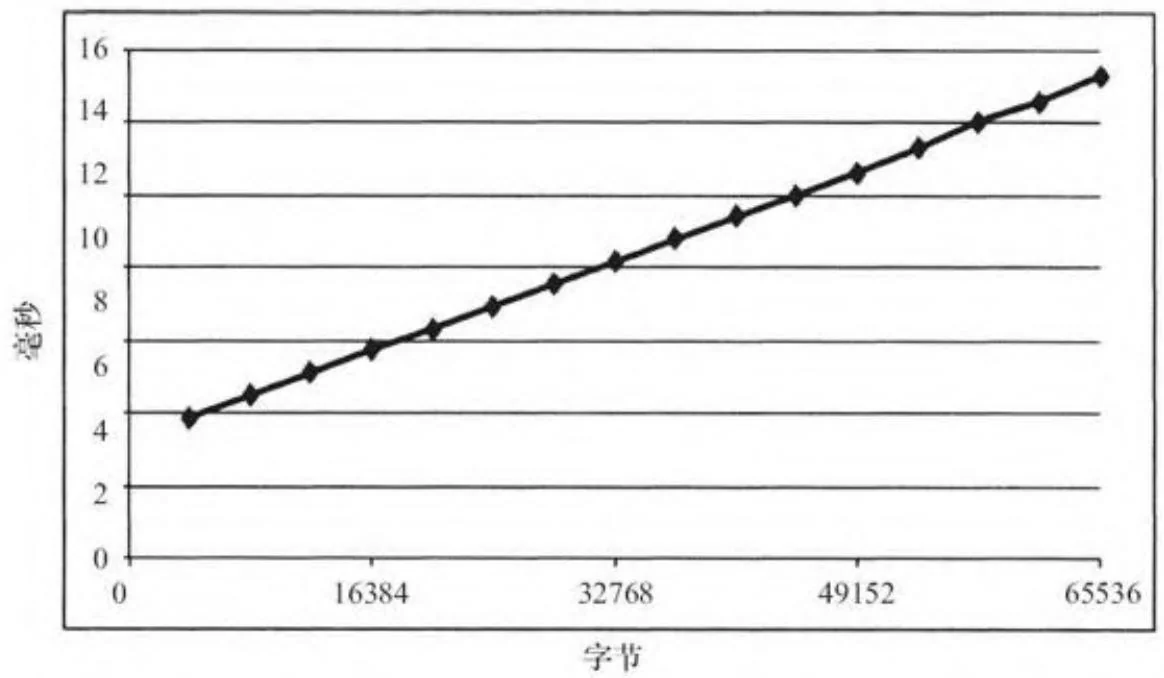
图6-5 从设备端到主机端的小内存复制的性能
6.2.3 NULL流和并发中断
任何流操作都可以输入NULL作为流参数,这些操作将等到之前的所有GPU操作完成后才会启动[1]。不需要复制引擎来让内存复制操作与内核处理重叠执行的应用程序可以使用NULL流,以利用CPU/GPU并发。
一旦一个流操作已经使用NULL流启动了,应用程序必须使用诸如cuCtxSynchronize()或CUDAThreadSynchronize()之类的同步函数来确保前面的操作在继续操作之前完成。但是应用程序可能会在进行同步之前要求很多这样的操作。例如,应用程序可能在和上下文同步之前执行一个异步的主机到设备的内存复制、一个或者多个的内核启动以
及一个异步的设备到主机的内存复制。一旦GPU已经完成了最近一次请求的操作,cuCtxSynchronize()或CUDAThreadSynchronize()调用就会返回。当执行小内存复制或启动不会长期运行的内核时,这个机制是特别有用的。CUDA驱动程序会充分利用CPU写命令到GPU的这段宝贵的时间,而且该CPU执行与GPU命令处理重叠进行可以提高性能。
注意 即使在CUDA 1.0中,内核启动也是异步的。其结果是,在没有指定流的情况下,所有内核启动隐式指定到NULL流上执行。
1. 打破并发
每当一个应用程序执行一个完整的CPU/GPU同步(让CPU等待直到GPU完全处于闲置状态),性能都会受损。我们可以通过把NULL流的内存复制调用从异步切换到同步,来测量同步操作带来的性能影响。可以通过把CUDAMemcpyAsync()调用改为CUDAMemcpy()调用来实现。这个nullDtoHMemcpySync.cu程序为设备端到主机端的内存复制专门运行上述任务。
在我们值得信赖的亚马逊cgl.4xlarge实例上,nullDtoHMemcpySync.cu报告了每个内存复制大约耗时7.9微秒。如果一个Windows驱动程序必须执行内核转换(kernel think),或者一个
启用ECC的GPU的驱动程序必须检查ECC错误,完全的GPU同步就会更昂贵。
执行此同步的显式方法包括以下几种:
· cuCtxSynchronize()/cudaDeviceSynchronize()。
NULL流上的cuStreamSynchronize()/CUDAStreamSynchronize()。
未采用流的主机和设备之间的内存复制,例如,cumemcpyHtoD()、cumemcpyDtoH()和cudamemcpy()。
其他将打破CPU/GPU并发的更微妙的方式包括以下几种:
· 运行过程是设置了CUDA-LaUNCH_BLOCKING环境变量的。
·需要重新分配本地内存的内核启动。
·执行大内存分配或主机内存分配。
销毁对象,如CUDA流和CUDA事件。
2. 非阻塞流
要创建一个不需要与NULL流同步的流(因此不太可能出现如上所述的“并发中断”),需要指定cuStreamCreate()的
CUDA_STREAM_NON_BLOCKING标志或者指定
CUDAStreamCreateWithFlags()的CUDAStreamNonBlocking标志。
[1] 当CUDA流功能添加到CUDA1.1时,设计者有两种选择:一个是把NULL流相对于其他流独立出来,在它的内部只能串行执行;另一种是让它与GPU的所有引擎同步(“汇聚”)。他们选择了后种方案,一部分原因在于CUDA还没有能够执行不同流之间同步的机制。