15.4_共享内存中的图像
15.4 共享内存中的图像
对于那些供我们的示例程序计算相关值的矩形来说,CUDA内核程序展示了同模板匹配的图像的像素是如何被大量复用的。目前为止,我们的代码仅依靠纹理缓存而不需要外部存储便可以进行大量的读取操作。然而,对于更小的模板,通过使用共享内存可以使得图像数据得到更低的延迟,从而进一步提高性能。
使用代码清单15-1和15-3的内核函数时,它会根据线程块大小将输入图像稳式地划成大小相同的图像块。代码清单15-5展示了一个在共享内存上的实现,我们使用了线程块的高度(blockDim.y),但显式指定了宽度为wTile。在我们的示例程序中,wTile的值为32。图15-4展示了内核函数是如何“过读取”(overfetch)处于图像块之外wTemplate hTemplate大小的矩形区域的,边界条件是通过纹理寻址模式处理的。一旦将图像数据复制到共享内存完毕后,内核函数通过__synchreads()同步线程块内的各个线程,计算并输出当前图像块的相关系数。
代码清单15-5 corrShared_kernel()
global _void
corrShared_kernel(
float *pCorr, size_t CorrPitch,
int wTile,
int wTemplate, int hTemplate,
float xOffset, float yOffset,
float cPixels, float fDenomExp, int SharedPitch,
float xUL, float yUL, int w, int h)
{
int uTile = blockIdx.x*wTile;
int vTile = blockIdx.y*blockDim.y;
int v = vTile + threadIdx.y;
float *pOut = (float *) (((char *) pCorr) + v*CorrPitch);
for ( int row = threadIdx.y; row < blockDim.y + hTemplate; row += blockDim.y ) {
int SharedIdx = row * SharedPitch;
for ( int col = threadIdx.x; col < wTile + wTemplate; col += blockDim.x ) {
LocalBlock[SharedIdx+col] = tex2D( texImage, (float) (uTile+col+xUL+xOffset), (float) (vTile+row+yUL+yOffset) );
}
}
__syncthreads();
for ( int col = threadIdx.x; col < wTile; col += blockDim.x ) {
int SumI = 0;
int SumISq = 0;
int SumIT = 0;
int idx = 0;
int SharedIdx = threadIdx.y * SharedPitch + col;
for ( int j = 0; j < hTemplate; j++) {
for ( int i = 0; i < wTemplate; i++) {
unsigned char I = LocalBlock[SharedIdx+i];
unsigned char T = g_Tpix{idx++};
SumI += I;
SumISq += I*I;
SumIT += I*T;
}
SharedIdx += SharedPitch;
}
if ( uTile+col < w && v < h ) {
pOut[uTile+col] =
CorrelationValue(SumI, SumISq, SumIT, g_SumT, cPixels, fDenomExp );
}
}
__syncthreads();
}为确保共享内存中相邻行之间不会发生存储片冲突(bank conflict),我们填充每行的数据量为64的倍数。
sharedPitch $\equiv$ -63&((wTile+wTemplate)+63));每个线程块所需要的共享内存的总量为步长(pitch)乘以行数(即块的高度加上模板的高度):
sharedMem = sharedPitch* (threads.y+hTemplate);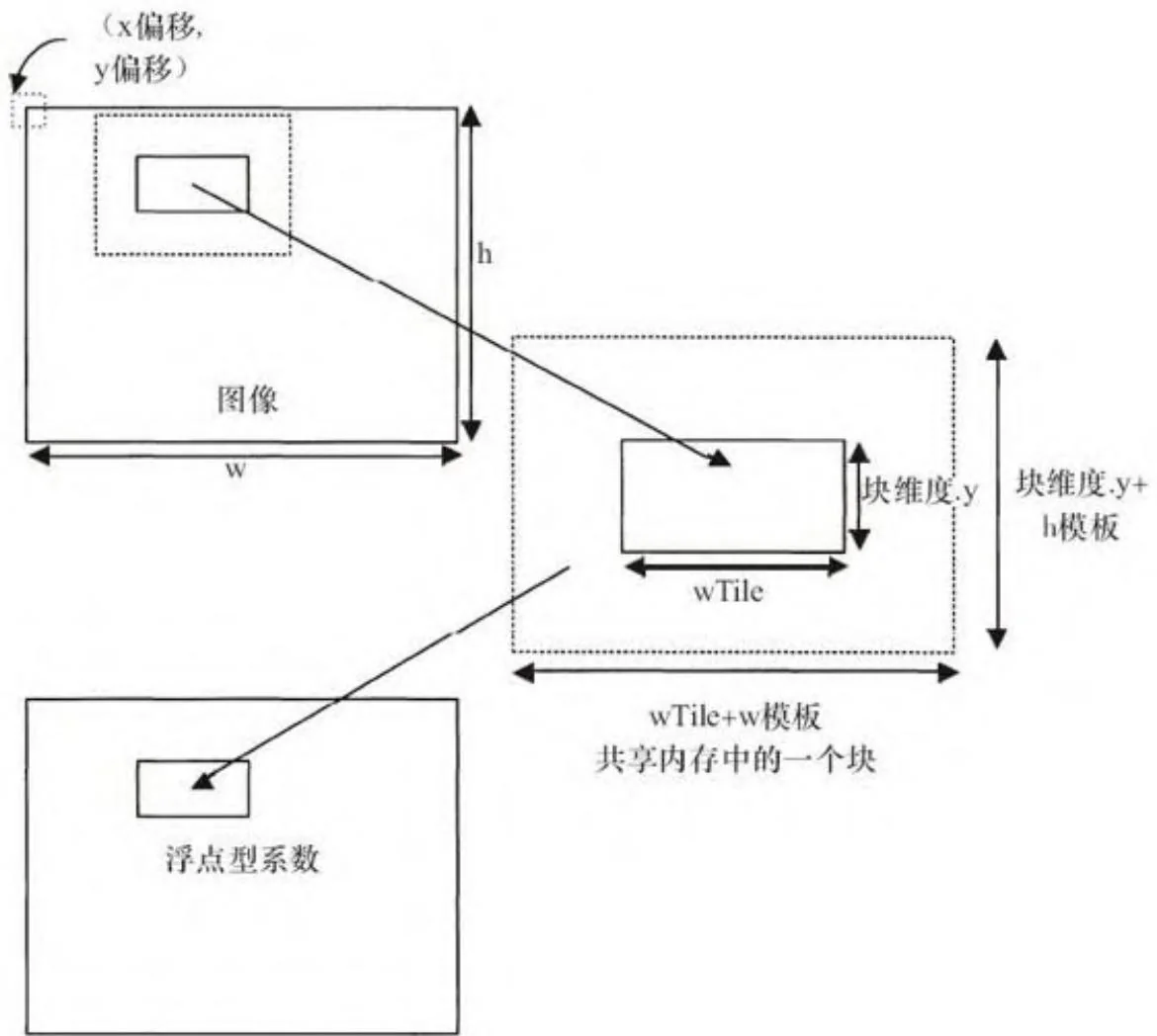
图15-4 共享内存中的图像
代码清单15-6的代码启动内核函数corrShared_kernel()的同时,检测内核是否需要比当前更多的共享内存。如果需要,它将调用
corrTexTex2D(), 这个函数适用于任意大小的模板。
代码清单15-6 corrShared()(主机端代码)
void
corrShared(
float *dCorr, int CorrPitch,
int wTile,
int wTemplate, int hTemplate,
float cPixels,
float fDenomExp,
int sharedPitch,
int xOffset, int yOffset,
int xTemplate, int yTemplate,
int xUL, int yUL, int w, int h,
dim3 threads, dim3 blocks,
int sharedMem) {
int device;
CUDADeviceProp props;
CUDAError_t status;
CUDART_CHECK(udaGetDevice(&device));
CUDART_CHECK(udaGetDeviceProperties(&props, device)
if (sharedMem > props(sharedMemPerBlock) {
dim3 threads88(8, 8, 1);
dim3 blocks88;
blocks88.x = INTCEIL(w, 8);
blocks88.y = INTCEIL(h, 8);
blocks88.z = 1;
return corrTexTex2D(
dCorr, CorrPitch,
wTile,
wTemplate, hTemplate,
cPixels,
fDenomExp,
sharedPitch,
xOffset, yOffset,
xTemplate, yTemplate,
xUL, yUL, w, h,
threads88, blocks88,
sharedMem);
}
corrShared_kernel<<blocks, threads, sharedMem>>>(dCorr, CorrPitch,
wTile,
wTemplate, hTemplate,
(float) xOffset, (float) yOffset,
cPixels, fDenomExp,
sharedPitch,
(float) xUL, (float) yUL, w, h);
Error:
return;
}