2.6_GPU架构
2.6 GPU架构
以下三种不同的GPU架构可以运行CUDA:
· 特斯拉架构(Tesla)硬件,如在2006年推出的 GeForce 8800 GTX(G80)中。
·费米架构(Fermi)硬件,如在2010年推出的GeForce GTX 480(GF100)中。
·开普勒架构(Kepler)硬件,如在2012年推出的GeForceGTX 680(GK104)中。
GF100/GK104命名来源于实现GPU的ASIC集成电路。它们之中的“F”和“K”分别代表费米架构和开普勒架构。
特斯拉和费米系列继承了英伟达的传统,他们会首先出货大型高端旗舰级芯片来赢取基准测试。这些芯片是昂贵的,因为英伟达的制造成本与制造ASIC时所需要的晶体管数量(进而影响芯片面积大小)密切相关。通过大型芯片的基准测试之后,会出货更小的芯片:中端的尺寸为大型的1/2,低端的为1/4,诸如此类。
与这一传统不同的是,英伟达的第一个开普勒级芯片定位于中端层次。上述大型芯片出货几个月后,第一个开普勒级芯片成功完成。
GK104拥有35亿个晶体管,而GK110则拥有71亿晶体管。
2.6.1 综述
从CUDA看来,GPU可以作如下简化:
一个连接GPU与PCIe总线的主机接口;
0~2个复制引擎;
一个连接GPU与其设备内存的DRAM接口;
一定数目的TPC或GPC(纹理处理集群或图形处理集群),每个包含一定的缓存和一些流处理器簇(SMs)。
在本章结尾引用的有关架构的论文将对支持CUDA的GPU的功能进行更为完整的叙述,其中包括支持抗锯齿渲染等特定图形功能。
1. 主机接口
主机接口实现了上一节中已经描述的功能。读取GPU命令(如内存复制和内核启动命令),并将其分派给相应的硬件单元,而且还具备了CPU和GPU之间、GPU上不同引擎之间和不同GPU之间同步的设施。在
CUDA中,通过流和事件API(见第6章),主机接口的基本功能得以体现。
2. 复制引擎
复制引擎可以在流处理器簇做计算时执行主机与设备之间的内存传输。最早的CUDA硬件并没有任何复制引擎,后来版本的硬件则包括了一个复制引擎,可以传输线性设备内存(CUDA数组除外),而最新的CUDA硬件则包括了两个复制引擎,可以使PCIe总线饱和并可以在CUDA数组和线性内存之间转换。[1]
3. DRAM接口
GPU的DRAM接口包含了用于合并内存请求的硬件,可以支持超过100GB/s的带宽。越是新的CUDA硬件所含的DRAM接口越高级。最早的硬件(SM 1.x)有复杂的合并要求,其要求地址要连续且64、128或256字节对齐(根据操作数大小而定)。从SM 1.2(GT200或GeForce GTX280)开始,无地址对齐要求,地址可以依据数据局部性被合并起来。费米架构硬件(SM 2.0和更高版本)有一个直写模式的二级缓存,可以提供和SM 1.2合并硬件一样的好处,并在数据重用时带来额外性能提升。
4. TPC和GPC
TPC和GPC是介于整个GPU和流处理器簇之间的硬件单元,用于执行CUDA计算。特斯拉架构硬件将SM组合成TPC(纹理处理集群),其中,TPC包含有纹理硬件支持(特别包含一个纹理缓存)和2个或3个SM,后面会有详细描述。费米架构硬件组则将SM组合为GPC(图形处理器集群),其中,每个GPU包含有一个光栅单元和4个SM。
在大多数情况下,CUDA开发人员并不需要关心TPC或GPC,因为对于计算硬件来说,SM才是计算硬件的最重要的抽象单元。
5. 特斯拉架构和费米架构对比
第一代支持CUDA的GPU的代号为特斯拉,而第二代为费米。在开发过程中,它们属于机密代码,但英伟达决定将它们作为外部产品的名称来描述前两代支持CUDA的GPU。为了制造悬念,英伟达选择使用“特斯拉”这一名称来形容使用CUDA机器构建计算集群的服务器级别的GPU板。[2]为了区分昂贵的服务器级别特斯拉板和架构族,本书指的架构族是“特斯拉架构硬件”、“费米架构硬件”和“开普勒架构硬件。”
注意 特斯拉架构硬件与费米架构硬件之间的差异也适用于开普勒架构。
在执行非合并的内存事务的代码时,早期的特斯拉架构硬件存在严重的性能损失(高达6倍)。后来随着特斯拉架构硬件的实现,从 GeForce GTX 280开始,将非合并事务的损失减少了约2倍。特斯拉架构硬件也有性能计数器,使开发人员能够测量有多少内存事务是非合并的。
特斯拉架构硬件只包括了一个24位整数乘法器,因此开发人员必须使用__mul24()等内建函数,以获得最佳性能。完整的32位乘法(即CUDA中原生的操作符*)通过小型指令序列进行模拟。
特斯拉架构硬件对共享内存初始化为零,而费米架构硬件并不进行初始化。对于使用驱动程序API的应用程序而言,这种变化的一个细微副作用是:在费米架构下使用cuParamSeti()来传递指针参数到64位平台上的应用程序,并不能正常工作。由于参数是在特斯拉架构硬件的共享内存中传递的,参数未初始化的上半部分将成为64位指针中最重要的32位。
SM 1.3中的GT200引入双精度支持。而GT200属于特斯拉架构第二代“赢取基准测试的”芯片。[3]在当时,该特性被认为是有风险的,因此它以节省面积的方式实现,可以按照英伟达期望的双精与单精比率来增删硬件(如对于GT200,这一比率为 )。费米架构更彻底的集成双精度支持且性能更好。[4]最后,对于图形应用程序,特斯拉架构硬件是第一款支持 DirectX 10的硬件。
费米架构硬件的功能比特斯拉架构硬件更强大。它支持64位寻址,增加了一级和二级缓存,加入了一个完整的32位整数乘法指令和一些专门用于扫描算法的新指令,它增加了表面加载/存储操作,以便CUDA内核可以在不使用纹理硬件的情况下就能读取和写入CUDA数组,它是第一个以多复制引擎为特色的GPU系列,改善了虚函数等C++代码支持。
费米架构硬件并不包括跟踪非合并内存传输所需的性能计数器。此外,因为它不包括有24位乘法器,费米架构硬件在运行要使用24位内建乘法函数时可能会出现一些小的性能损失。在费米架构中,使用乘法运算符*是最快速的方式。
对于图形应用程序,费米架构硬件可以运行DirectX 11。表2-1总结了特斯拉架构和费米架构硬件之间的差异。
表2-1 特斯拉架构和费米架构硬件之间的差异
(1): 对于Tesla 硬件, 高达 2 倍。
(2): 启用ECC时, 高达2倍。
6. 纹理操作的细微差别
特斯拉架构和费米架构硬件之间的一个细微差异是这样的:在特斯拉架构的硬件中,执行纹理操作的指令,其输出会覆盖输入寄存器向量。在费米架构硬件中,输入和输出寄存器向量可以是不同的。其结果是,特斯拉架构硬件可能要使用额外的指令来移动纹理坐标到输入寄存器,以恢复原始输入向量。
特斯拉架构和费米架构硬件的另一个微小的区别是,当对一维CUDA数组进行纹理操作时,费米架构硬件通过使用二维纹理并设置0.0为第二个坐标来模拟相应功能。由于这个模拟的成本只需一个额外的寄存器和少数额外指令,所以应用程序很少会注意到这一差异。
2.6.2 流处理器簇
GPU的力量之源是流处理器簇(也称为SM)。就像上一节所提到的,每个SM 1.X硬件中的TPC包含2个或3个SM,而每个SM 2.X硬件中的GPC则包含4个SM。最先支持CUDA的GPU——G80或 GeForce 8800 GTX,包含8个TPC,而每一个TPC中有2个SM,所以一共有16个SM。接下来的
一个支持CUDA的大GPU是GT200或GeForce GTX 280,它增加了TPC中的SM数量,包含10个TPC并且每个TPC含有3个SM,总共30个SM。
每一个支持CUDA的GPU中SM的数量可能从二到几十个,并且每一个SM包含:
执行单位,用以执行32位整数和单、双精度浮点数运算;
·特殊函数单元(SFU),用以计算log/exp,sin/cos,rcp/rsqrt的单精度近似值;一个线程束调度器,用以协调把指令分发到执行单元;
一个常量缓存,用于广播式传送数据给SM;
·共享内存,用于线程之间的数据交换;
·纹理映射的专用硬件。
图2-29展现了特斯拉架构流处理器簇(SM 1.X)。它包含了8个流处理器,支持32位整数和单精度浮点数运算。第一个CUDA硬件根本不能支持双精度浮点数运算,但是自从GT200开始,SM就包含了双精度浮点数运算的单元。[5]
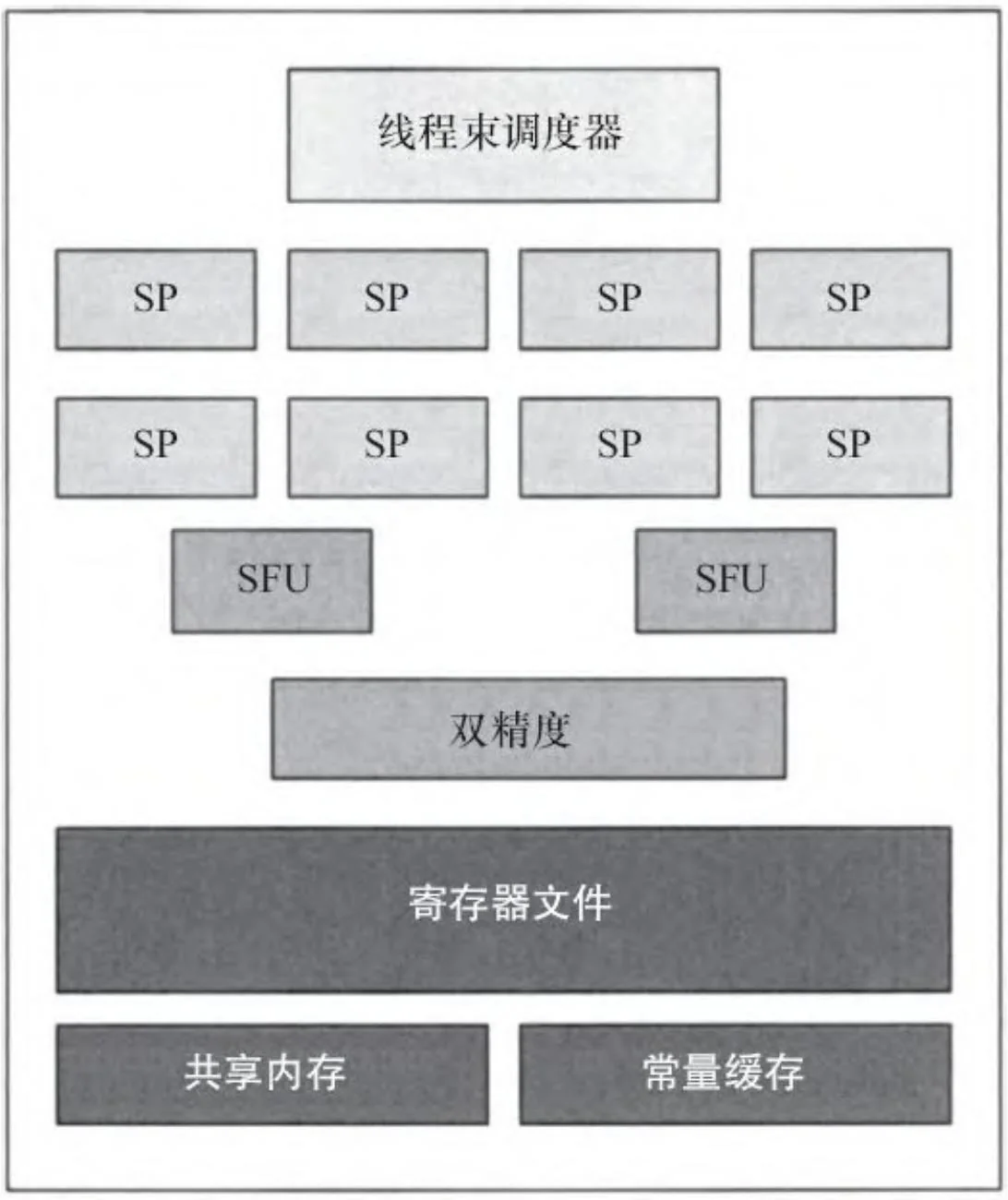
图2-29 SM1.x
图2-30展示了费米架构流处理器簇(SM 2.0)。不同于特斯拉架构的分离方式实现的双精度浮点数支持,费米架构的每一个SM 2.0拥有完整的双精度支持。虽然双精度执行速度比单精度慢,但由于SM
2.0的单-双精比率比特斯拉架构的8:1小得多,所以整体双精度性能要高很多。 [6]
图2-31显示的是更新过后的费米架构流处理器簇(SM 2.1),可以在诸如GF104芯片上找到。为了获得更高的性能,英伟达选择增加流处理器的数量到48个。SFU同SM的比率从1:8增加到1:6。
图2-32显示了最近的(截止到本文写作时)流处理器簇的设计,它们为我们展现了英伟达最新开普勒架构硬件的特色。这种设计与前几代的设计完全不同,被英伟达称为SMX(下一代SM)。其中,核心的数量增加了6倍,到了192个,并且每个SMX都远大于以往GPU中类似的SM。最大的费米架构GPU——GF110有大约30亿晶体管,共16个SM;而GK104有35亿个晶体管和更高的性能,却只有8个SMX。为了节省面积和提高能耗效率,英伟达为每一个SM增加了许多共享内存/一级缓存资源。就像费米架构的SM一样,每个开普勒架构SMX拥有64KB缓存,它可以分割成48KB一级缓存与16KB共享内存,或者是48KB共享内存与16KB一级缓存。对于CUDA开发者来说,开普勒架构相比之前的架构,更鼓励将数据存储在寄存器中(而不是一级缓存,或者共享内存)。
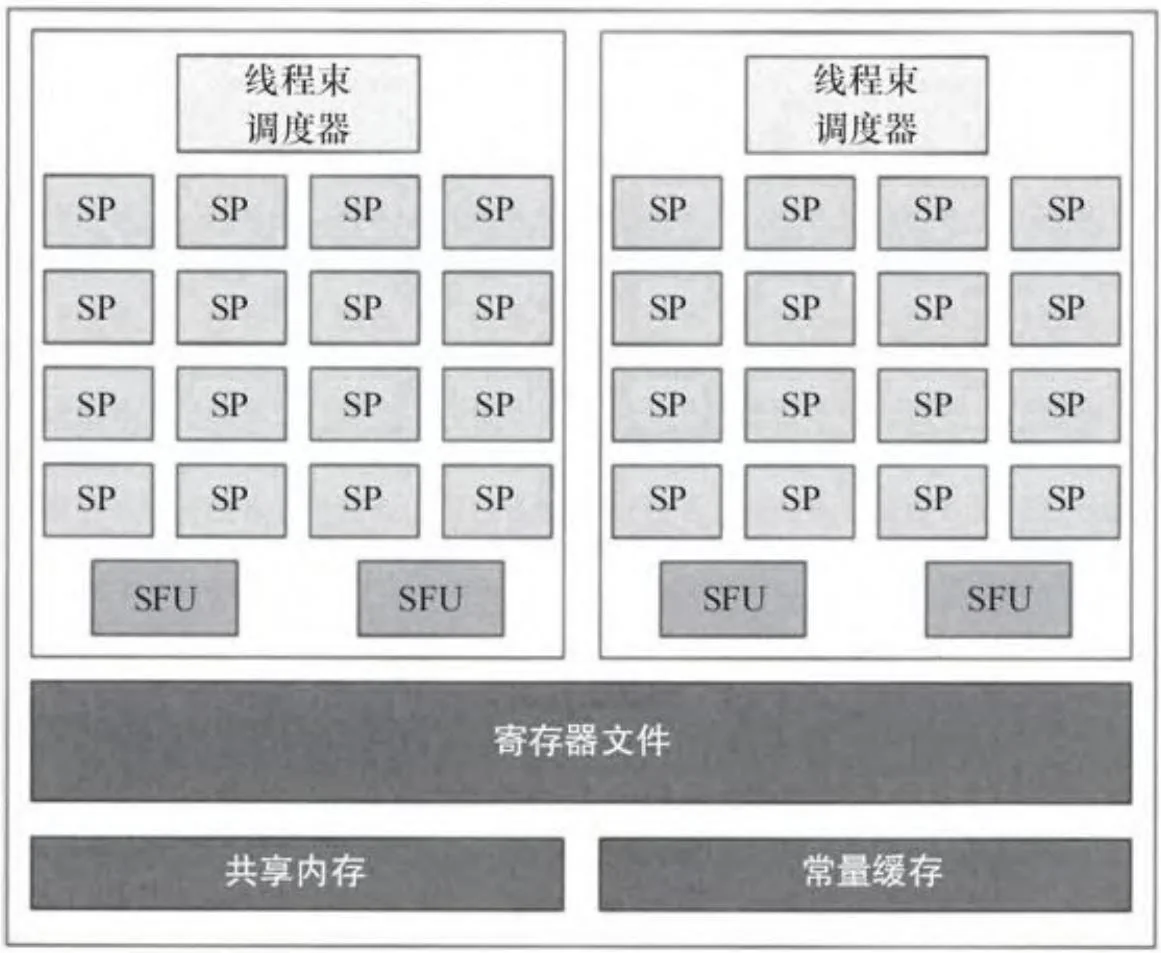
图2-30 SM2.0(费米架构)
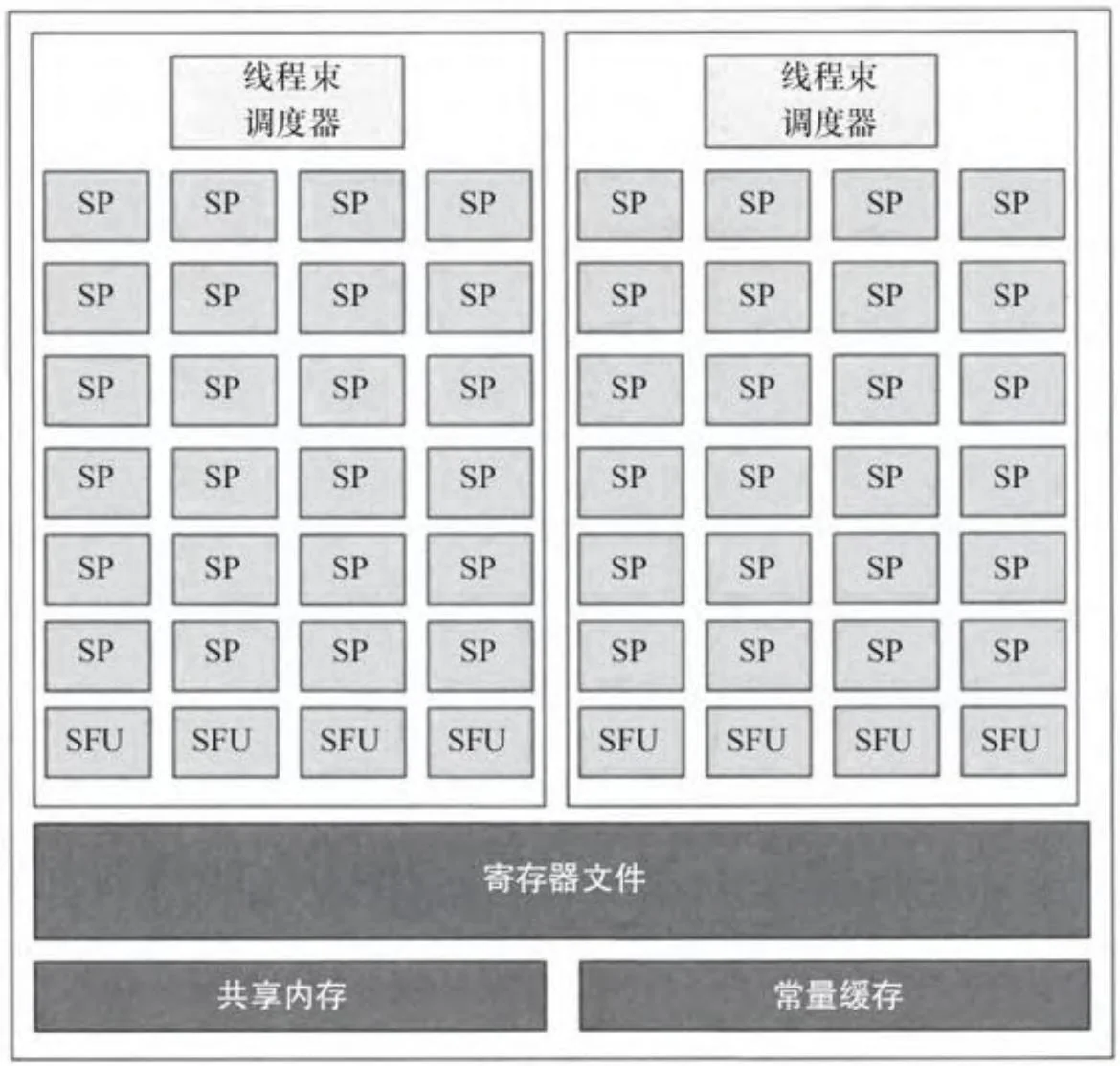
图2-31 SM2.1(费米架构)

图2-32 SM3.0(SMX)
[1] 两个以上的复制引擎并没有多大的意义,因为每个引擎都能使PCIe的两个方向之一饱和。
[2] 当然,特斯拉品牌刚出现时,费米架构硬件还没出现。营销部门的工程师告诉我们,体系架构代号和品牌名称都是“特斯拉”只是一个巧合。
[3] 事实上,SM1.2与SM1.3唯一的不同是SM1.3支持双精度。
[4] 在SM 3.x中,英伟达不再把双精度浮点性能当做影响SM版本的因素,因此,GK104的双精度浮点运算性能较差,而GK110的较好。
[5] GT200添加了一些指令集和双精度支持(如共享内存的原子操作),因此GT200的指令集中没有双精度的属于SM 1.2,有双精度的属于SM 1.3。
[6] 对于开普勒架构的硬件,英伟达可以根据GPU的目标市场不同将浮点性能进行调整。