6.1_CPU与GPU的并发:隐藏驱动程序开销
6.1 CPU/GPU的并发:隐藏驱动程序开销
CPU/GPU的并发是指CPU在已经发送一些请求给GPU之后能够继续处理的能力。可以说,CPU/GPU并发性最重要的用处就是隐藏来自GPU的请求任务的开销。
内核启动
内核的启动一直是异步的。一系列内核启动,如果它们之间没有其他CUDA操作干扰,将导致CPU把内核启动提交到GPU,并在GPU处理完毕之前将控制权返回给调用者。
我们可以通过发射一系列用计时操作包围的空内核启动来测量驱动程序的开销。代码清单6-1展示了nullKernelAsync.cu,它是一个测量执行内核启动所需时间的小程序。
代码清单6-1 nullKernelAsync.cu.
include<stdio.h>
#include"chTimer.h"
global_
void
NullKernel()
{
int main(int argc, char \*argv[])
{ const int cIterations $=$ 1000000; printf("Launches...");fflush( stdout); chTimerTimestamp start,stop; chTimerGetTime(&start); for (int i $= 0$ ;i $< <$ cIterations; $\mathrm{i + + }$ ) { NullKernel<<1,1>>(); } CUDAThreadSynchronize(); chTimerGetTime(&stop); double microseconds $=$ le6\*chTimerElapsedTime(&start,&stop); double usPerLaunch $=$ microseconds / (float) cIterations; printf("%.2fus\n",usPerLaunch); return 0;正如在附录A中描述的,chTimerGetTime()使用主机操作系统的高分辨率计时设施,如QueryPerformanceCounter()或gettimeofday()。在第23行的CUDAThreadSynchronize()调用对于精确的计时而言是需要的。如删去它,当stop通过下面的函数调用记录时间时,GPU并没有完成对最后一个内核的调用。
chTimerGetTime(&stop);如果运行这个程序,你会看到,调用一个内核甚至一个什么都不做的内核将花费 毫秒的时间。大多数的时间花费在驱动程序上。CPU/GPU 并发性仅仅当内核运行时间比让驱动程序启动它的时间长
时才有作用。为了强调CPU/GPU并发性对于小内核启动的重要性,让我们把CUDAThreadSynchronize()调用移动到内循环中[1]。
chTimerGetTime( &start );
for ( int i = 0; i < cIterations; i++ ) { NullKernel<<l,l>>(); CUDAThreadSynchronize();
} chTimerGetTime( &stop );这里唯一的区别是,CPU等待GPU处理完每一个空内核启动才进行下一个内核启动,如图6-1所示。作为一个例子,在禁用ECC的Amazon EC2实例中,nullKernelASync在每次启动时,报告的时间为3.4毫秒,而nullKernelSync在每次启动时报告一个100毫秒的时间。因此,不考虑CPU/GPU的并发性,同步本身也应该避免。
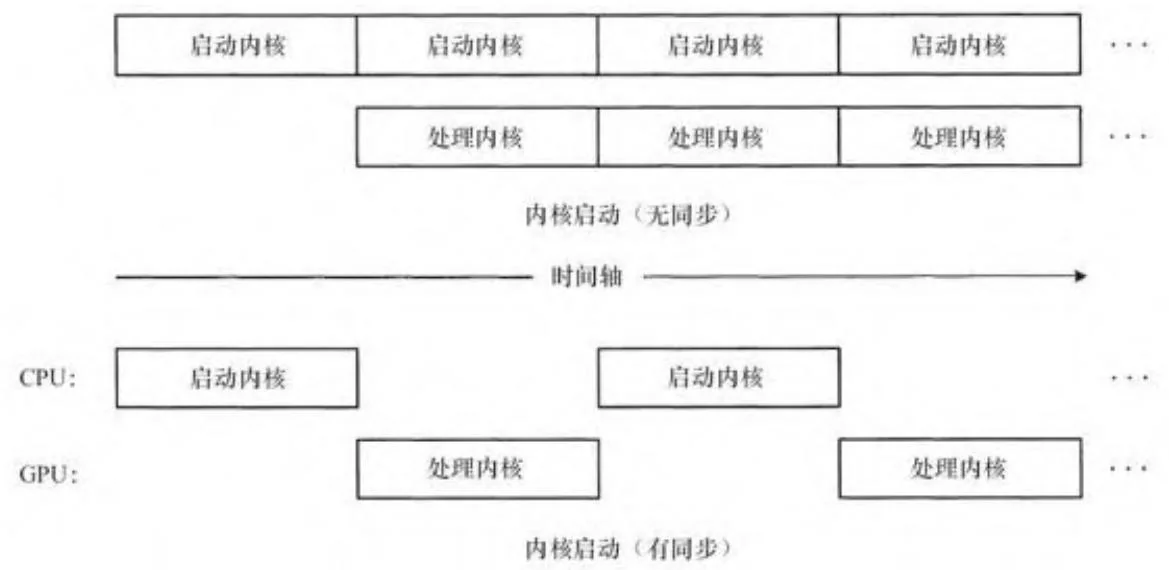
图6-1 CPU/GPU的并发性
即使不进行同步操作,如果内核运行时间不比启动内核所花的时间(3.4毫秒)长,GPU可能会在CPU提交更多工作之前闲置。为了知道
一个内核需要做多少工作才能使启动是值得的,我们切换到一个忙等待一定时钟周期(使用clock()内置函数)的内核。
__device__int deviceTime;
__global_
void
WaitKernel( int cycles, bool bWrite )
{ int start $=$ clock(); int stop; do { stop $=$ clock(); } while (stop - start < cycles); if (bWrite && threadIdx.x $\equiv$ 0 && blockIdx.x $\equiv$ 0){ deviceTime $=$ stop - start; }通过在满足条件时把结果写到deviceTime中,这个内核可以避免编译器优化掉忙等待延时。编译器不知道我们会把false作为第二个参数传递[2]。然后我们的main()函数里面的代码就会检查各种循环值的启动时间,从0~2500。
for (int cycles = 0; cycles < 2500; cycles += 100) {
printf("Cycles: %d - ", cycles); fflush(stdout);
chTimerGetTime(&start);
for (int i = 0; i < cIterations; i++) {
WaitKernel<<<1,1>>>(cycles, false);
}
CUDAThreadSynchronize();
chTimerGetTime(&stop);
double microseconds = le6*chTimerElapsedTime(&start, &stop);
double usPerLaunch = microseconds / (float) cIterations;
printf("%.2f us\n", usPerLaunch);该程序可以在waitKernelAsync.cu中找到。在我们的EC2实例中,输出正如图6-2所示。在这个主机平台上,打破势均力敌的标志(内核启动时间超过一个空内核启动时间的2倍)大约是在第4500个GPU时钟周期。
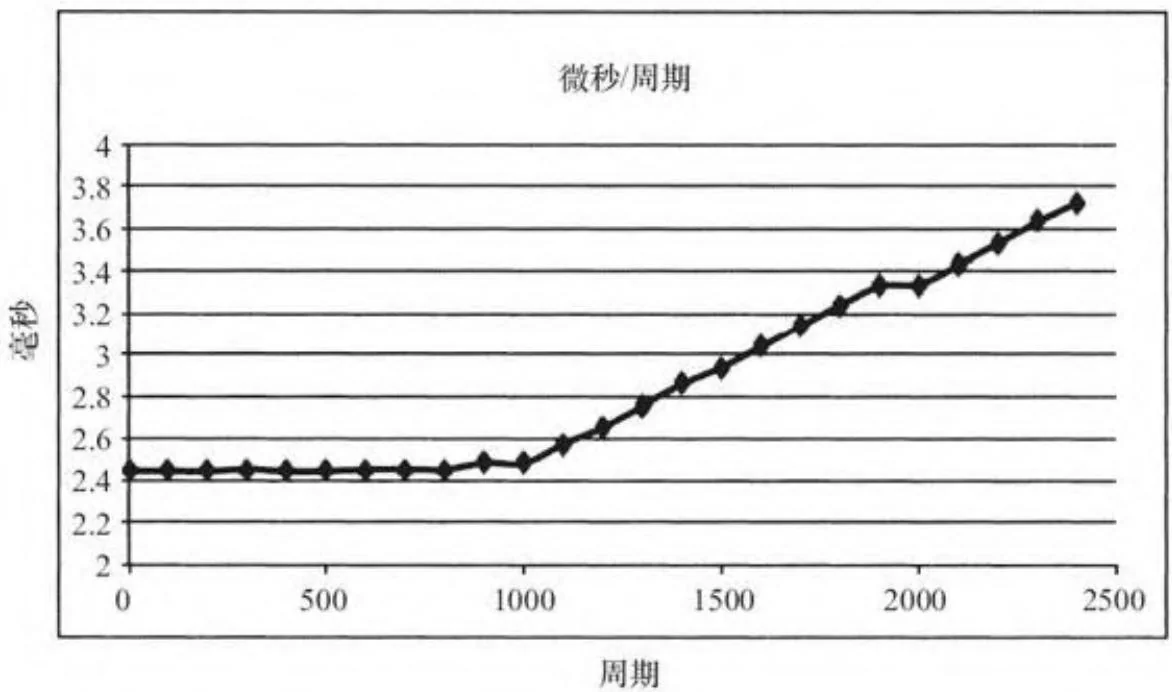
图6-2 waitKernelAsync.cu的毫秒/周期示意图
这些性能特征可能在很宽的范围内变化,并依赖于许多因素,其中包括以下几点。
主机CPU的性能
·主机操作系统
·驱动程序版本
·驱动程序模型(是TCC还是Windows上的WDDM)
·是否在GPU上启用ECC [3]
但大多数CUDA应用程序共同的主旨就是,开发人员应该尽最大努力避免破坏CPU/GPU并发。只有非常计算密集的应用程序和进行大量数据传输的应用程序能忽视这方面的开销。为了在进行内存复制和内核启动时充分利用CPU/GPU的并发性,开发人员必须使用异步的内存复制。
[1] 这个程序的源代码在nullkernel sync.cu里,这里没有详细列出是因为它与代码清单6-1几乎等同。
[2] 如果bWrite为false,编译器将通过每次循环里的条件分支,同时带来计时结果的失效。当计时结果看起来比较可疑时,我们应该使用cuobjdump检查微码以确认这一种情况是否发生。
[3] 当ECC启用时,驱动程序必须执行内核转换来检查是否发生了内存错误。最终,即使在包含用户模式客户端驱动程序的平台上,CUDA Thread Syuchrowize()函数也是代价较高的。