按分布收敛
分布函数全面描述了随机变量的统计规律,因此讨论随机变量分布函数序列 {F(xn)} 的收敛有重要的意义。
定义 设随机变量 X,X1,X2,⋯ 的分布函数分别为 F(x),F1(x),F2(x),⋯ .若对 F(x) 的任意连续点 x ,都有
n→∞limFn(x)=F(x) 则称 {Fn(x)} 弱收敛于 F(x) ,记为 Fn(x)WF(x) 。也称 {Xn} 按分布收敛于 X ,记为 XnLX .
依概率收敛与弱收敛之间有什么关系呢?下面定理给出依概率收敛是比弱收敛更强的收敛。
定理 XnPX⇒XnLX .
证明 略。
上面定理说明了若随机变量序列 {Xn} 依概率收敛于 X ,则一定按分布收敛于 X .反之,不一定成立。那么在什么情况下,这两种收玫等价呢?下面定理给出了两种收玫等价的条件。
定理 若 c 为常数,则 XnPc 的充要条件是 XnLc .
证明 略.
按分布收敛的通俗解释
事实上, 这是最弱的一种收敛, 它蕴含在其他所有类型的收敛中.
我们来看个例子.设 Xn 是一个服从均匀分布的随机变量,其概率密度函数为
fn(x)={n10 若 x∈{0,n1,n2,⋯,nn−2,nn−1} 其他. 下标 n 是为了强调我们有 n 个非零值,这些值是均匀间隔的, 如下图(n=10)
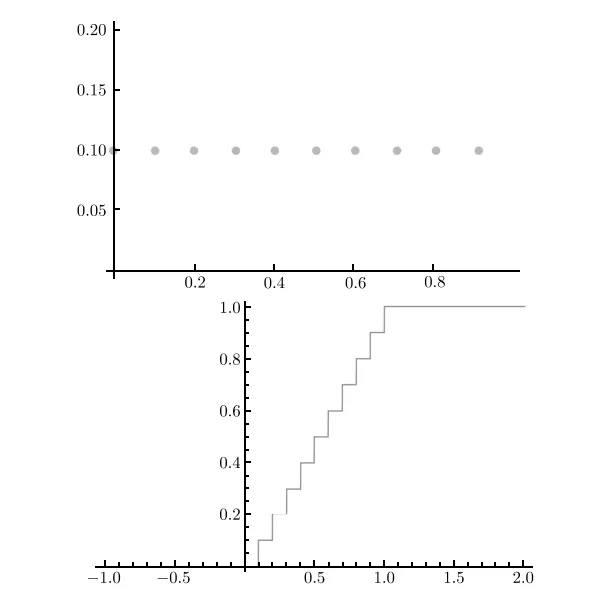
从概率密度函数中不难看出,对于任意的 x∈[0,1] ,都有 limn→∞fn(x)=0 .考察这一点最简单的方法是,除了 n 个特殊值外,fn(x)=0 对其余所有 x均成立.当 x 取任意特殊值时,fn(x) 都等于 1/n 。随着 n 的增加,这个值会减小到 0 。
分布函数的情况则截然不同.当 x∈[0,1] 时,Fn(x) 等于 n1 乘以 {0,1/n,2/n,⋯ , (n−1)/n} 中不大于 x 的值的个数。这是因为 分布函数 等于随机变量不大于 x的概率.对于任意的 x∈[0,1] ,
Fn(x)=0⩽k⩽n−1k/n⩽x∑n1=n⌊nx⌋, 其中,函数 ⌊y⌋ 表示不超过 y 的最大整数.因为 ⌊y⌋ 与 y 最多相差 1 ,所以 nx−1⩽⌊nx⌋⩽nx ,于是有
x−n1⩽Fn(x)⩽x 当取极限 n→∞ 时, limn→∞Fn(x)=x .这正是服从 [0,1] 上均匀分布的随机变量的累积分布函数。
我们看到了这种收敛被称为弱收敛的原因:概率密度函数没有收敛到均匀分布的概率密度函数。乍一看,这应该会令人感到失望,但是从很多方面来说还不算太糟。回想一下,我们可以利用分布函数来计算事件的概率.