10.5_使用多个CUDA流
10.5 使用多个CUDA流
我们将10.4节中的示例改为使用两个不同的流。在前面示例的开始时,我们检查了这个设备确实支持重叠功能,并将计算分解为多个块。改进这个程序的思想很简单,包括两个方面:“分块”计算以及内存复制和核函数执行的重叠。我们将实现,在第0个流执行核函数的同时,第1个流将输入缓冲区复制到GPU。然后,在第0个流将计算结果复制回主机的同时,第1个流将执行核函数。接着,第1个流将计算结果复制回主机,同时第0个流开始在下一块数据上执行核函数。假设内存复制操作和核函数执行的时间大致相同,那么应用程序的执行时间将如图10.1所示。这张图假设,GPU可以同时执行一个内存复制操作和一个核函数,因此空的方框表示一个流正在等待执行某个操作的时刻,这个操作不能与其他流的操作相互重叠。还需要注意的是,在本章的剩余图片中,函数调用CUDAMemcpyAsync()被简写为复制。
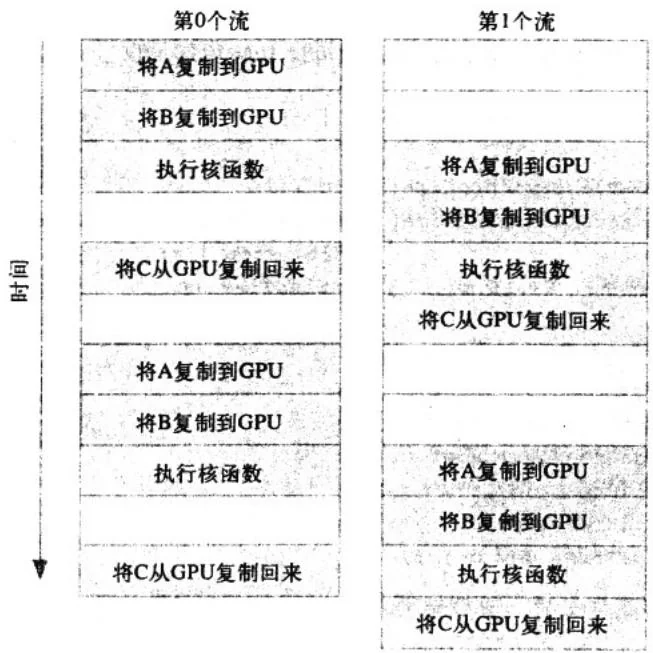
图10.1 应用程序在使用两个不同流时的执行时间线
事实上,实际的执行时间线可能比图中给出的更好看,在一些新的NVIDIA GPU中同时支持核函数和两次内存复制操作,一次是从主机到设备,另一次是从设备到主机。在任何支持内存复制和核函数的执行相互重叠的设备上,当使用多个流时,应用程序的整体性能都会提升。
尽管能够获得对应用程序的加速,但核函数将保持不变。
include"../common/book.h"
#define N (1024\*1024)
#define FULL_DATA_SIZE $(N^{*}20)$
__global__void kernel(int \*a,int \*b,int \*c){ intidx $=$ threadIdx.x $^+$ blockIdx.x \*blockDim.x; if(idx< N){ int idx1 $=$ (idx+1)%256; intidx2 $=$ (idx+2)%256; float as $=$ (a[idx] $^+$ a[idx1] $^+$ a[idx2])/3.0f; float bs $=$ (b[idx] $^+$ b[idx1] $^+$ b[idx2])/3.0f; c[idx] $=$ (as $^+$ bs)/2
}与使用单个流的版本一样,我们将判断设备是否支持计算与内存复制操作的重叠。如果设备支持重叠,那么就像前面一样创建CUDA事件并对应用程序计时。
int main(void){ CUDADeviceProp prop; int whichDevice; HANDLE_ERROR( CUDAGetDevice( &whichDevice ) ); HANDLE_ERROR( CUDAGetDeviceProperties( &prop,whichDevice ) ); if(!prop_deviceOverlap) { printf("Device will not handle overlaps,so no " "speed up from streams\n"); return 0; } CUDAEvent_t start,stop; float elapsedTime; //启动计时器 HANDLE_ERROR( CUDAEventCreate( &start ) ); HANDLE_ERROR( CUDAEventCreate( &stop ) ); HANDLE_ERROR( CUDAEventRecord( start,0 ) );接下来创建两个流,创建方式与在前面代码中创建单个流的方式完全一样。
//初始化流
cudaStream_t stream0, stream1;
HANDLE_ERROR(udaStreamCreate(&stream0));
HANDLE_ERROR(udaStreamCreate(&stream1));假设在主机上仍然是两个输入缓冲区和一个输出缓冲区。输入缓冲区中填充的是随机数据,与使用单个流的应用程序采用的方式一样。然而,现在我们将使用两个流来处理数据,分配两组相同的GPU缓冲区,这样每个流都可以独立地在输入数据块上执行工作。
int *host_a, *host_b, *host_c;
int *dev_a0, *dev_b0, *dev_c0; //为第0个流分配的GPU内存
int *dev_al, *dev_bl, *dev_cl; //为第1个流分配的GPU内存//在GPU上分配内存
HANDLE_ERROR(udaMalloc((void**)&dev_a0, N * sizeof(int) );
HANDLE_ERROR(udaMalloc((void**)&dev_b0, N * sizeof(int) );
HANDLE_ERROR(udaMalloc((void**)&dev_c0, N * sizeof(int) ) );
HANDLE_ERROR(udaMalloc((void**)&dev_al, N * sizeof(int) ) );
HANDLE_ERROR(udaMalloc((void**)&dev_b1, N * sizeof(int) ) );
HANDLE_ERROR(udaMalloc((void**)&dev_cl, N * sizeof(int) ) );//分配在流中使用的页锁定内存
HANDLE_ERROR(纵深HostAlloc((void**)&host_a, FULL_DATA_SIZE * sizeof(int),纵深HostAllocDefault));
HANDLE_ERROR(纵深HostAlloc((void**)&host_b, FULL_DATA_SIZE * sizeof(int),纵深HostAllocDefault));
HANDLE_ERROR(纵深HostAlloc((void**)&host_c, FULL_DATA_SIZE * sizeof(int),纵深HostAllocDefault));
for (int i=0; i<FULL_DATA_SIZE; i++) { host_a[i] = rand(); host_b[i] = rand(); }然后,程序在输入数据块上循环。然而,由于现在使用了两个流,因此在for()循环的迭代
中需要处理的数据量也是原来的两倍。在stream()中,我们首先将a和b的异步复制操作放入GPU的队列,然后将一个核函数执行放入队列,接下来再将一个复制回c的操作放入队列:
//在整体数据上循环,每个数据块的大小为N
for (int i=0; i<FULL_DATA_SIZE; i+=N*2) {
//将锁定内存以异步方式复制到设备上
HANDLE_ERROR(udaMemcpyAsync( dev_a0, host_a+i, N * sizeof(int),udaMemcpyHostToDevice, stream0));
HANDLE_ERROR(udaMemcpyAsync( dev_b0, host_b+i, N * sizeof(int),udaMemcpyHostToDevice, stream0));kernel<<N/256,256,0, stream0>>>(dev_a0, dev_b0, dev_c0);//将数据从设备复制回锁定内存
HANDLE_ERROR(udaMemcpyAsync(host_c+i,dev_c0,N\*sizeof(int),udaMempyDeviceToHost,streamO));在将这些操作放入stream0的队列后,再把下一个数据块上的相同操作放入steam1的队列中。
//将锁定内存以异步方式复制到设备上
HANDLE_ERROR(udaMemcpyAsync( dev_al, host_a+i+N, N * sizeof(int),udaMemcpyHostToDevice, stream1));
HANDLE_ERROR(udaMemcpyAsync( dev_bl, host_b+i+N, N * sizeof(int),udaMemcpyHostToDevice, stream1));
kernel<<N/256,256,0,stream1>>(dev_al,dev_bl,dev_cl);//将数据从设备复制回到锁定内存
HANDLE_ERROR(udaMemcpyAsync(host_c+i+N,dev_cl,N\*sizeof(int),udaMempyDeviceToHost,stream1));}
这样,在for()循环的迭代过程中,将交替地把每个数据块放入这两个流的队列,直到所有
待处理的输入数据都被放入队列。在结束了for()循环后,在停止应用程序的计时器之前,首先将GPU与GPU进行同步。由于使用了两个流,因此需要对二者都进行同步。
HANDLE_ERROR(udaStreamSynchronize( stream0 ) );
HANDLE_ERROR(udaStreamSynchronize( stream1 ) );我们采用了与单个流版本中相同的方式将main()包装起来。停止计时器,显示经历的时间,并且执行清理工作。当然,我们要记住,现在需要销毁两个流,并且需要释放两倍的GPU内存,除此之外,这段代码与之前看到的代码是相同的:
HANDLE_ERROR(udaEventRecord(stop,0));
HANDLE_ERROR(udaEventSynchronize(stop));
HANDLE_ERROR(udaEventElapsedTime(& elapsedTime, start,stop));
printf(“Time taken: $\text{忍} 3 . 1 f$ ms\n”, elapsedTime);// 释放流和内存
HANDLE_ERROR(udaFreeHost(host_a) );
HANDLE_ERROR(udaFreeHost(host_b) );
HANDLE_ERROR(udaFreeHost(host_c) );
HANDLE_ERROR(udaFree(dev_a0) );
HANDLE_ERROR(udaFree(dev_b0) );
HANDLE_ERROR(udaFree(dev_c0) );
HANDLE_ERROR(udaFree(dev_al) );
HANDLE_ERROR(udaFree(dev_b1) );
HANDLE_ERROR(udaFree(dev_cl) );
HANDLE_ERROR(udaStreamDestroy stream0) );
HANDLE_ERROR(udaStreamDestroy stream1) ;
return 0;我们在GeForce GTX 285上分别测试了10.3节中的使用单个流的版本,以及改进后使用两个流的版本。在修改为使用两个流后,程序的执行时间为61ms。
非常棒!
这正是我们对程序进行计时的原因。有时候,我们自认为的性能“增强”实际上除了使代码变得更复杂外,不会起到任何作用。
这个程序能不能变得更快?确实,程序还能变得更快!因为我们实际上是通过第二个流来加速仅使用单个流的应用程序,但要想进一步加快程序的执行速度,我们需要首先理解CUDA驱动程序对流的处理方式,才能从设备重叠中获得好处。要理解流在幕后是如何工作的,我们
需要理解CUDA驱动程序和CUDA硬件架构的工作原理。