A.3_DeZero的反向传播
A.3 DeZero的反向传播
在DeZero的反向传播中,导数是作为ndarray实例传播的。这里我们思考一下将第2次及之后的反向传播的导数的代码以in-place运算的方式改为x.grad += gx的情况。将step/step14.py中的代码以in-place运算的方式进行替换后运行以下代码。
$\mathbf{x} =$ Variable(np.array(3))
y $=$ add(x,x)
y.backup()
print('y_grad:{}\{({})'.format(y_grad,id(y_grad)))
print('x_grad:{}\{({})'.format(x_grad,id(x_grad)))运行结果
y.grad: 2 (4427494384)
x.grad: 2 (4427494384)上面代码的运行结果是x的导数和y的导数都是2,ndarray的ID相同。也就是说,二者引用的是同一个ndarray。这里的问题是y的导数不正确,y的导数应该是1。
这个问题发生的原因是in-place运算覆盖了这个值。由于y.gradle和x.gradle引用的是同一个值,所以y.gradle变为了错误的结果。我们把代码改为x.gradle = x.gradle + gx。再次运行这段代码,结果如下所示。
运行结果
y.grad: 1 (4755624944)
x.grad: 2 (4755710960)这次y和x引用的是不同的ndarray,而且引用的值是正确的值,这就解决了前面所说的问题。以上就是步骤14没有使用+=(in-place运算)的原因。
附录B
实现get_item函数(步骤47的补充内容)
步骤47只介绍了DeZero的函数get_item的使用方法,这里笔者将介绍其实现。首先看一下ListItem类和get_item函数的代码。
dezero/functions.py
class GetItem(Function): def __init__(self, slices): self.slices = slices def forward(self, x): y = x[self.slices] return y def backward(self, gy): x, = self.inputs f = GetItemGrad(self.slices, x.shape) return f(gy) def get_item(x, slices): return GetItem(slices)(x)上面的代码在初始化阶段接受进行切片操作的参数slices。之后的forward(x)方法只是通过x[self.slices]取出元素。

DeZero的forward(x)中的x是ndarray实例,而backward(gy)中的gy是Variable实例。在实现反向传播的过程中,需要使用DeZero的函数对Variable实例进行计算。
另外,DeZero中没有与切片操作相对应的反向传播的计算。为此,笔者另外准备了名为GetItemGrad的新的DeZero函数类。换言之,我们要通过GetItemGrad的正向传播来实现GetItem的反向传播的处理。
接下来是GetItemGrad类的代码,如下所示。
dezero/functions.py
class GetItemGrad(Function): def __init__(self, slices, in_shape): self.slices = slices self.in_shape = in_shape def forward(self, gy): $\mathrm{gx} =$ np.zeros(self.in_shape) np.add.at(gx, self.slices, gy) return gx def backward(self, ggx): return get_item(ggx, self.slices)首先在初始化阶段接收执行切片操作的参数(slices)和输入数据的形状(in_shape)。然后,在主计算(forward)中准备元素为零的多维数组作为输入的梯度,之后执行np.add.at(gx, self.slices, gy)。这行代码针对gx在self.slices指定的位置上加上了gy。我们可以从下面的代码示例清楚地了解到np.add.at函数的用法。
>>> import numpy as np
>>> a = np.zeros((2, 3))
>>> a
array([[0., 0., 0.],
[0., 0., 0.]])
>>> b = np.ones((3))
>>> b
array([1., 1., 1])
>>> slices = 1
>>> np.add.at(a, slices, b)
>>> a
array([[0., 0., 0.],
[1., 1., 1.]])
如果通过多维数组的切片操作一次提取出多个元素,那么在反向传播中就需要加上相应的梯度。因此,上面的代码通过np.add.at函数进行了加法计算。
接着需要实现与np.add.at函数对应的反向传播,有趣的是,我们刚刚实现的get_item函数就是。到这里,get_item函数就全部完成了。
附录C
在 Google Colaboratory 上运行
Google Colaboratory(以下简称“Google Colab”)是一个在云端运行的Jupyter Notebook环境。只要有浏览器,任何人都可以使用它。它不仅支持CPU,还支持GPU。
本附录将介绍如何使用Google Colab运行DeZero。作为示例,这里运行步骤52中的代码(MNIST的训练代码)。首先访问以下链接。
在浏览器中打开上面的链接,会显示图C-1中的界面。图C-1中Notebook的内容被分为一个个单元格。单元格可以是文本,也可以是用Python或用其他语言编写的代码。在运行单元格中的代码时,要先点击单元格来选择它,然后点击代码左边的播放按钮。我们也可以使用键盘快捷键“command+return”或“Ctrl+Enter”来运行代码。

图C-1中显示的数据是本书GitHub仓库中的examples/mnist_colab_gpu.ipynb。GitHub上的ipynb文件可以从Google Colab打开。
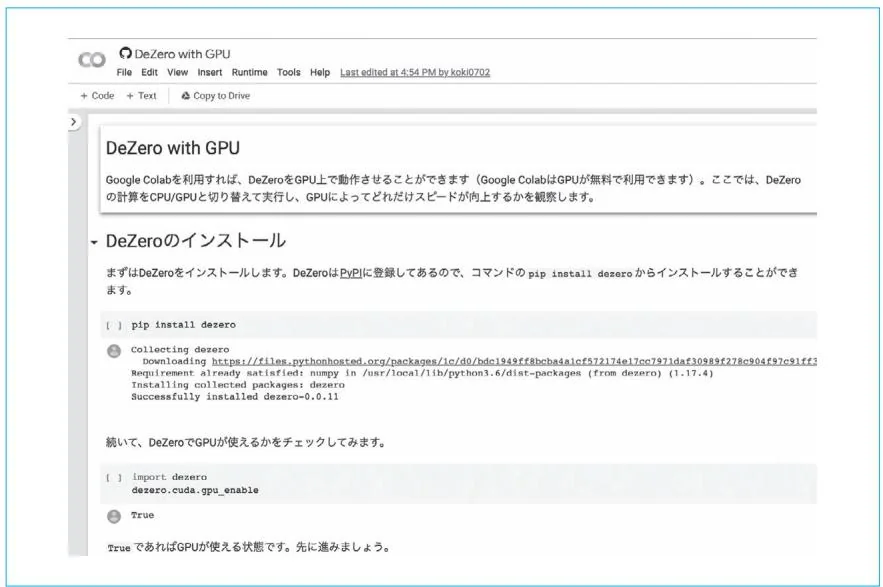
图C-1 Google Colab的界面

下面的内容以图C-1的Notebook为基础。建议读者一边在Google Colab上运行单元格一边阅读本部分的内容。另外,在首次运行单元格时,会看到警告。选择“直接运行”,单元格就会继续运行下去。
这个Notebook首先会安装DeZero。由于DeZero已发布到PyPI中,所以我们可以通过pip installdezero命令来安装它。
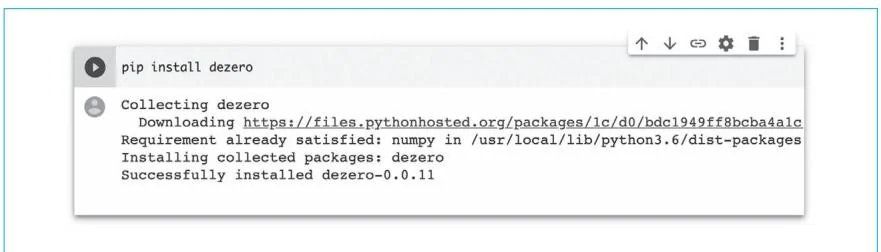
安装完成后,使用GPU运行DeZero。
[ ] import doit \
doit.cuda.gpu_enable
True如果是True,则说明GPU处于可用的状态;如果是False,则说明我们需要在Google Colab中对GPU进行设置。设置方法如下所示。
从菜单的“运行时”中选择“改变运行时类型”
从“硬件加速器”下拉菜单选择“GPU”
下面使用DeZero训练MNIST。首先在CPU上运行
[ ] import time
importdezero
importdezero-functions as F
fromdezero import optimizers
fromdezero import Dataloader
fromdezero.models import MLP
max_epoch $= 5$
batch_size $= 100$
cpu-times $= \square$
train_set $=$ dezero.datasets.MNIST(train=True)
trainloader $=$ Dataloader(train_set,batch_size)
model $=$ MLP((1000,10))
optimizer $=$ optimizers.SGD().setup(model)
for epoch in range(max_epoch):
start $=$ time.time()
sum_loss $= 0$
for x,t in trainloader:
y $=$ model(x)
loss $=$ F.softmaxcross_entropy(y,t)
model.cleargrads()
loss/backward()
optimizer.update()
sum_loss $+=$ float(loss.data)*len(t)
elapsed_time $=$ time.time()-start
cpu-times.append(Elapsed_time)
print('epoch:{},loss:{:.4f},time:{:.4f}[sec].format(
epoch + 1,sum_loss/len(train_set), elapsed_time))
epoch: 1, loss: 1.9140, time: 7.8949[sec]
epoch: 2, loss: 1.2791, time: 7.8918[sec]
epoch: 3, loss: 0.9211, time: 7.9565[sec]
epoch: 4, loss: 0.7381, time: 7.8198[sec]
epoch: 5, loss: 0.6339, time: 7.9302[sec]接下来使用GPU进行计算。
[ ]gpu-times $= \square$ #GPU mode trainloader.to_gpu() model.to_gpu() for epoch in range(max_epoch): start $=$ time.time() sum_loss $= 0$ forx,tintrainloader: y $=$ model(x) loss $=$ F散热maxcross_entropy(y,t) model.cleargrads() loss.backup() optimizer.update() sum_loss += float(loss.data)\*len(t) elapsed_time $=$ time.time() - startgpu-times.append(elapsed_time) print('epoch:{},loss:{:.4f},time:{:.4f} [sec]'.format( epoch $+1$ ,sum_loss / len(train_set), elapsed_time))$\bullet$ epoch: 1, loss: 0.5678, time: 1.5356[sec]
$\bullet$ epoch: 2, loss: 0.5227, time: 1.5687[sec]
$\bullet$ epoch: 3, loss: 0.4898, time: 1.5498[sec]
$\bullet$ epoch: 4, loss: 0.4645, time: 1.5433[sec]
$\bullet$ epoch: 5, loss: 0.4449, time: 1.5512[sec]作为参考,比较一下DeZero在CPU和GPU上的速度。结果如下所示。
[ ] cpu_avg_time = sum.cpu-times) / len.cpu-times)
gpu_avg_time = sumgpu-times) / lengpu-times)
print('CPU: {:.2f}[sec].format(cpu_avg_time))
print('GPU: {:.2f}[sec].formatgpu_avg_time))
print('GPU speedup over CPU: {:.1f}x'.format(cpu_avg_time/gpu_avg_time))CPU: 7.90[sec]
GPU: 1.55[sec]
GPU speedup over CPU: 5.1x以上就是对 Google Colab 的介绍。除了本附录中展示的例子,它还可以运行 DeZero 的其他示例代码。当然,我们也可以运行自己用 DeZero 编写的原创代码。大家不妨将 Google Colab 灵活用在各个地方。