52.5_在GPU上训练MNIST
52.5 在GPU上训练MNIST
经过这些修改之后,我们可以在GPU上运行DeZero了。这里尝试在GPU上运行MNIST的训练代码。代码如下所示。
steps/step52.py
import time
importdezero
importdezero-functions as F
fromdezero import optimizers
fromdezero import DataLoader
fromdezero.models import MLP
max_epoch $= 5$
batch_size $= 100$
train_set $\equiv$ dezero.datasets.MNIST(train=True)
trainloader $\equiv$ DataLoader(train_set,batch_size)
model $=$ MLP((1000,10))
optimizer $=$ optimizers.SGD().setup(model)# GPU mode
ifdezero.cudagpu_enable:
trainloader.togpu()
model.togpu()
for epoch in range(max_epoch):
start = time.time()
sum_loss = 0
for x, t in trainloader:
y = model(x)
loss = F softmax.Cross_entropy(y, t)
model.cleargrads()
loss.backward()
optimizer.update()
sum_loss += float(loss.data) * len(t)
elapsed_time = time.time() - start
print('epoch: {}, loss: {}.4f', time: {}.4f)[sec].format( epoch + 1, sum_loss / len(train_set), elapsed_time))在GPU可用的环境下,上面的代码会将DataLoader和模型的数据传输到GPU。这样后续处理就会使用CuPy的函数了。
下面在GPU上实际运行上面的代码。结果显示损失像以前一样顺利减少,而且运行速度也比在CPU上要快。作为参考,图52-1展示了在Google Colaboratory中运行上面代码的结果。
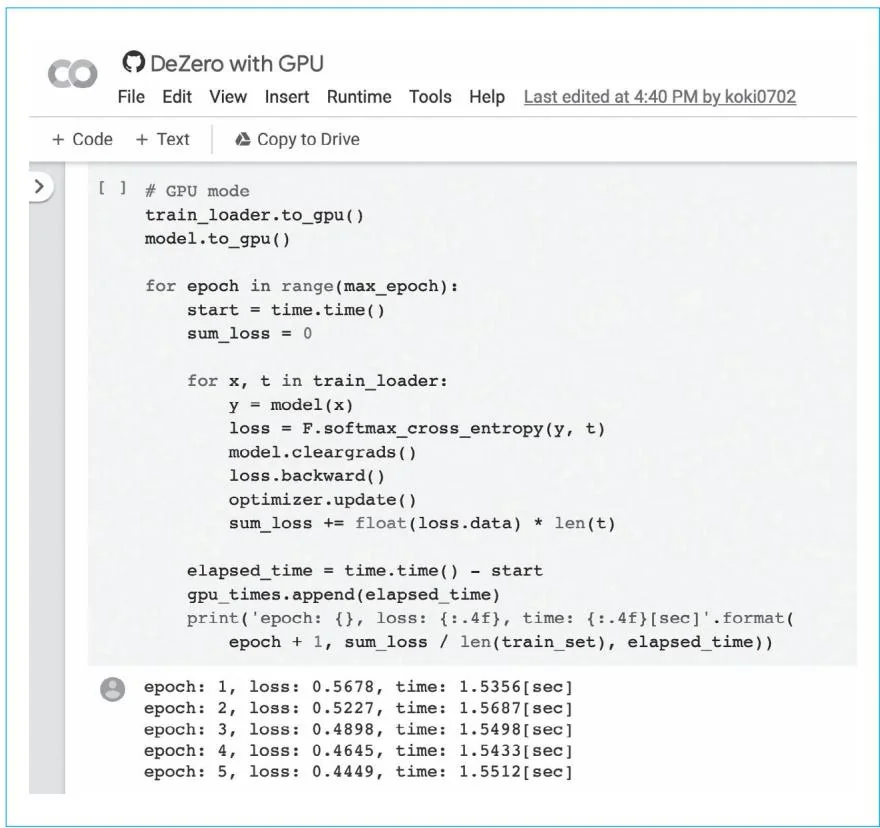
图52-1 在Google Colaboratory中的运行结果
如图52-1所示,在使用GPU时,每轮计算可以在1.5秒左右完成。这个结果取决于Google Colaboratory的执行环境(如分配的GPU)。而在使用CPU时,每轮计算大约需要8秒,所用时间是使用GPU的5倍左右。到这里,DeZero就支持GPU了。
步骤53
模型的保存和加载
在本步骤中,我们会实现将模型的参数保存到外部文件的功能,还会实现加载已保存的参数的功能。有了这些功能,我们就可以将训练过程中的模型保存为“快照”,也可以加载训练好的参数,只进行推理。
DeZero 的参数实现为 Parameter 类(它继承自 Variable)。Parameter 的数据则作为 ndarray 实例被保存在实例变量 data 中,所以,这里我们要把 ndarray 实例保存到外部文件。正好 NumPy 提供了一些用于保存(和加载)ndarray 的函数。我们首先看一下这些函数的用法。

如果在GPU上运行DeZero,我们需要使用CuPy的ndarray(cupy. ndarray)来代替NumPy的ndarray。此时要把CuPy的张量换成NumPy的张量,然后把它们保存到外部文件。因此,在将数据保存到外部文件时,我们只考虑NumPy的情况。