0x02_枚举、模拟、递推
0x02 枚举、模拟、递推
一个实际问题的各种可能情况构成的集合通常称为“状态空间”,而程序的运行则是对于状态空间的遍历,算法和数据结构则是通过划分、归纳、提取、抽象来帮助提高程序遍历状态空间的效率。递推和递归就是程序遍历状态空间的两种基本方式,枚举和模拟就是将面前的状态空间按照一定的顺序“直接地”交给程序进行遍历的算法。本节中的枚举、模拟和递推算法对于程序设计已经入门的读者来讲都非常熟悉,这里就不再赘述,而直接以几道例题帮助读者加以体会。
【例题】费解的开关 TYVJ1266
在一个5*5的01矩阵中,点击任意一个位置,该位置以及它上下左右四个相邻的位置中的数字都会变化(0变成1,1变成0),问最少需要多少次点击可以把一个给定的01矩阵变成全0矩阵。
在上述规则的01矩阵的点击游戏中,很容易发现两个性质:
每个位置至多只会被点一次。
若固定了第一行(不能再改变第一行),则满足题意的点击方案至多只有 1 种。其原因是当第 行某一位为 1 时,若前 行已被固定,只能点击第 行该位置上的数字才能使第 行的这一位变成 0。从上到下按行使用归纳法可得上述结论。
于是,我们可以枚举第一行的点击方法,共 种。完成第一行的点击后,固定第一行,按照上述性质2从第一行开始递推。若到达第 行不全为0,说明这种点击方式不合法。在所有合法的点击方式中取点击次数最少的就是答案。对第一行的32次枚举涵盖了该问题的整个状态空间,因此该做法是正确的。
对于第一行点击方法的枚举,可以采用位运算的方式,枚举 这32个5位二进制数,若二进制数的第 位为1,就点击01矩阵第1行第 列的数字。
按照状态空间的规模大小,有如下几种常见的枚举形式和遍历方式:
“多项式”型的枚举在程序设计中随处可见,而本节中的第一道例题中的枚举则是一种“指数”型的枚举。上一节中最短Hamilton路径问题的朴素做法,是一种“排列”型的枚举。关于“组合”型枚举以及递归的遍历方式,我们将在下一节继续讲解。
【例题】Strange Towers of Hanoi FOJ1958
解出 个盘子4座塔的Hanoi(汉诺塔)问题最少需要多少步?关于Hanoi问题请参阅原题的题目描述。
首先考虑 个盘子3座塔的经典Hanoi问题,设 表示求解该 盘3塔问题的最少步数,显然有 ,即把前 个盘子从A柱移动到B柱,然后把第 个盘子从A柱移动到C柱,最后把前 个盘子从B柱移动到C柱。
回到本题,设 表示求解 盘4塔问题的最少步数,则:
其中 。上式的含义是,先把 个盘子在 4 塔模式下移动到 B 柱,然后把 个盘子在 3 塔模式下移动到 D 柱,最后把 个盘子在 4 塔模式下移到 D 柱。考
虑所有可能的 取最小值,就得到了上述递推公式。
在时间复杂度可以接受的前提下,上述做法可以推广到 盘 塔的计算。
前缀和
对于一个给定的数列 ,它的前缀和数列 是通过递推能求出的基本信息之一:
一个部分和,即数列 中某个下标区间内的数的和,可以表示为前缀和相减的形式:
在二维数组(矩阵)中,也有类似的递推形式,可求出二维前缀和,进一步计算出二维部分和。
【例题】激光炸弹 BZOJ1218
一种新型的激光炸弹,可以摧毁一个边长为 的正方形内的所有的目标。现在地图上有 个目标,用整数 (其值在闭区间 之内)表示目标在地图上的位置,每个目标都有一个价值 。
激光炸弹的投放是通过卫星定位的,但其有一个缺点,就是其爆破范围,即那个边长为 的正方形的边必须和 轴平行。若目标位于爆破正方形的边上,该目标不会被摧毁。求一颗炸弹最多能炸掉地图上总价值为多少的目标。
因为 的值在 之间,所以我们可以建立一个二维数组 ,其中 就等于位置 上的所有目标的价值之和。即对于每个目标,令 。
接下来我们求出 的二维前缀和 ,即:
如下图所示,我们再观察 的关系:

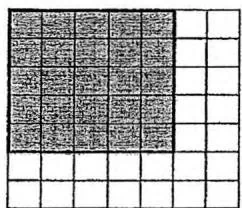


-5[i-1,j-1]
容易得到如下的递推式:
同理,对于任意一个边长为 的正方形,我们有:
因此,我们只需要 递推求出二维前缀和 ,然后 枚举边长为 的正方形的右下角坐标 ,即可通过上式 计算出该正方形内所有目标的价值之和,更新答案。上面给出的两个式子蕴含的思想其实就是“容斥原理”,0x37节会详细探讨容斥原理的应用。
值得一提的是,我们上面把 作为一个“格子”,而原题中 是一个点,并且正方形边上的目标不会被摧毁。实际上,我们不妨认为这个点就处于“格子” 的中心位置,格子的左上角坐标为 ,右下角坐标为 ,而正方形的右下角处于“格线交点”上,即一个值为“□.5”的坐标。这个转化与原问题是等价的。另外,本题内存限制较为严格,我们可以省略 数组,读入时直接向 中累加。
【例题】Tallest Cow POJ3263
有 头牛站成一行。两头牛能够相互看见,当且仅当它们中间的牛身高都比它们矮。现在,我们只知道其中最高的牛是第 头,它的身高是 ,不知道剩余 头牛的身高。但是,我们还知道 对关系,每对关系都指明了某两头牛 和 可以相互看见。求每头牛的身高最大可能是多少。 。
题目中的 对关系带给我们的信息实际上是牛之间身高的相对大小关系。具体来说,我们建立一个数组 ,数组中起初全为0。若一条关系指明 和 可以互相看见(不妨设 ),则把数组 中下标为 到 的数都减去1,意思是在 和 中间的牛,身高至少要比它们小1。因为第 头牛是最高的,所以最终 一定为0。其他的牛与第 头牛的身高差距就体现在数组 中。换言之,最后第 头牛的身高就等于 。
如果我们朴素执行把数组 中下标为 到 的数都减去1的操作,那么整个算法的时间复杂度为 ,复杂度过高。一个简单而高效的做法是,额外建立一个数组 ,对于每对 和 ,令 减去1, 加上1。其含义是:“身高减小1”的影响从 开始,持续到 ,在 结束。最后, 就等于 的前缀和,即 。如下页图所示。
上述优化后的算法把对一个区间的操作转化为左、右两个端点上的操作,再通过前缀和得到原问题的解。这种思想很常用,我们在后面还会多次遇到。该算法的时间复杂度为 。
值得提醒的是,在本题的数据中,一条关系 可能会输入多次,要注意检查,对于重复的关系,只在第一次出现时执行相关操作即可。
map<int, int>, bool> existed;
int c[10010], d[10010];
int main() {
int n, p, h, m;
cin >> n >> p >> h >> m;
for (int i = 1; i <= m; i++) {
int a, b;
scanf("%d%d", &a, &b);
if (a > b) swap(a, b);
if (existed[make_pair(a, b)]) continue;
d[a + 1]--, d[b]++;
existed[make_pair(a, b)] = true;
}
for (int i = 1; i <= n; i++) {
c[i] = c[i - 1] + d[i];
printf("%d\n", h + c[i]);
}
cout << endl;递归
递归的宏观描述
对于一个待求解的问题①,当它局限在某处边界、某个小范围或者某种特殊情形下
时,其答案往往是已知的。如果能够将该解答的应用场景扩大到原问题的状态空间,并且扩展过程的每个步骤具有相似性,就可以考虑使用递推或者递归求解。以已知的“问题边界”为起点向“原问题”正向推导的扩展方式就是递推。然而在很多时候,推导的路线难以确定,这时以“原问题”为起点尝试寻找把状态空间缩小到已知的“问题边界”的路线,再通过该路线反向回溯的遍历方式就是递归。我们通过两幅图来表示递推与递归的差别。
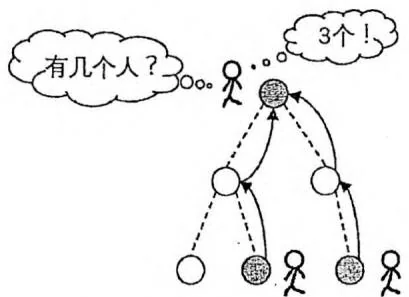

我们刚才也提到,使用递推或递归要求“原问题”与“问题边界”之间的每个变换步骤具有相似性,这样我们才能够设计一段程序实现这个步骤,将其重复作用于问题之上。换句话说,程序在每个步骤上应该面对相同种类的问题,这些问题都是原问题的一个子问题,可能仅在规模或者某些限制条件上有所区别,并且能够使用“求解原问题的程序”进行求解。有了这个前提,我们就可以让程序在每个变换步骤中执行三个操作:
缩小问题状态空间的规模。这意味着程序尝试寻找在“原问题”与“问题边界”之间的变换路线,并向正在探索的路线上迈出一步。
尝试求解规模缩小以后的问题,结果可能是成功或失败。
如果成功,即找到了规模缩小后的问题的答案,那么将答案扩展到当前问题。如果失败,那么重新回到当前问题,程序可能会继续寻找当前问题的其他变换路线,直至最终确定当前问题无法求解。
在以上三个操作中有两点颇为关键。其一是“如何尝试求解规模缩小以后的问题”。因为规模缩小以后的问题是原问题的一个子问题,所以我们可以把它视为一个新的“原问题”由相同的程序(上述三个操作)进行求解,这就是所谓的“自身调用自身”。其二是如果求解子问题失败,程序需要重新回到当前问题去寻找其他的变换路线,因此把当前问题缩小为子问题时所做的对当前问题状态产生影响的事情应该全部失效,这就是所谓的“回溯时还原现场”。上面这类程序就是“递归”的遍历方式,其整体流程如下页图所示。

问题边界
问题边界
问题边界
可以看到,递归程序的基本单元是由“缩小”“求解”“扩展”组成的一种变换步骤,只是在“求解”时因为问题的相似性,不断重复使用了这样一种变换步骤,直至在已知的问题边界上直接确定答案。对于其中任意一条从原问题到问题边界的变换路线(图中实线圈出的路径),横向来看,它的每一层是一次递归程序体的执行;纵向来看,它的左右两边分别是寻找路线和沿其推导的流程。为了保证每层的“缩小”与“扩展”能够衔接在同一形式的问题上,“求解”操作自然要保证在执行前后程序面对问题的状态是相同的,这也就是“还原现场”的必要性所在。
【例题】递归实现指数型枚举
从 这 个整数中随机选取任意多个,输出所有可能的选择方案。
这等价于每个整数可以选或者不选,所有可能的方案总数共有 种。通过前两节的学习,我们已经知道可以进行一次循环,利用位运算来列举所有的选择方案。这一次我们使用递归来求解,在每次递归中分别尝试某个数选或不选两条分支,将尚未确定的整数数量减少1,从而转化为一个规模更小的同类问题。
vector<int> chosen; // 被选择的数
void calc(int x) {
if (x == n + 1) { // 问题边界
for (int i = 0; i < chosen.size(); i++)
printf("%d ", chosen[i]);
puts("");
return;
}} //“不选 $\mathbf{x}$ ”分支 calc(x + 1); //求解子问题 //“选 $\mathbf{x}$ ”分支 chosen.push_back(x); //记录x已被选择 calc(x + 1); //求解子问题 chosen.pop_back(); //准备回溯到上一问题之前,还原现场
} int main(){ calc(1); //主函数中的调用入口【例题】递归实现组合型枚举
从 这 个整数中随机选出 个,输出所有可能的选择方案。
我们只需要在上面指数型枚举的程序的 calc 函数开头添加以下这条语句即可:
if (chosen.size() > m || chosen.size() + (n - x + 1) < m) { return; }这就是所谓的“剪枝”。寻找变换路线其实就是“搜索”的过程,如果能够及时确定当前问题一定是无解的,就不需要到达问题边界才返回结果。在本题中,如果已经选择了超过 个数,或者即使再选上剩余所有的数也不够 个,就可以提前得知当前问题无解了。这条剪枝保证我们一旦进入无解的分支就会立刻返回,所以时间复杂度就从 降低为 。关于搜索及其剪枝,我们将从第0x20节开始用一章的篇幅详细讲解。
【例题】递归实现排列型枚举
把 这 个整数排成一行后随机打乱顺序,输出所有可能的次序。
该问题也被称为全排列问题,所有可能的方案总数有 种。在这里,递归需要求解的问题是“把指定的 个整数按照任意次序排列”,在每次递归中,我们尝试把每个可用的数作为数列中的下一个数,求解“把剩余的 个整数按照任意次序排列”这个规模更小的子问题。
int order[20]; // 按顺序依次记录被选择的整数
bool chosen[20]; // 标记被选择的整数
void calc(int k) { if $(\mathrm{k} == \mathrm{n} + 1)$ { //问题边界 for (int i = 1; i <= n; i++) printf("%d ", order[i]); puts(""); return; } for (int i = 1; i <= n; i++) { if (chosen[i]) continue; order[k] = i; chosen[i] = 1; calc(k + 1); chosen[i] = 0; order[k] = 0; //这一行可以省} } int main() { calc(1); //主函数中的调用入口 }【例题】Sumdiv POJ1845
求 的所有约数之和 ( )。
把 分解质因数,表示为 。
那么 可表示为 。
的所有约数可表示为集合 ,其中 。
根据乘法分配律, 的所有约数之和就是:
我们可以把该式展开,与约数集合比较。我们在0x31节和0x32节中将会详细介绍有关分解质因数和约数的内容。
上式中的每个括号内都是等比数列,如果使用等比数列求和公式,需要做除法。而
答案还需要对9901取模,mod运算只对加、减、乘有分配率,不能直接对分子分母分别取模后再做除法。我们可以换一种思路,使用分治法进行等比数列求和。所谓分治法,就是把一个问题划分为若干个规模更小的同类子问题,对这些子问题递归求解,然后在回溯时通过它们推导出原问题的解。
问题:使用分治法求
若 为奇数:
若 为偶数,类似地:
每次分治(递归之后),问题规模均会缩小一半,配合快速幂即可在 的时间内求出等比数列的和。
【例题】Fractal Streets POJ3889
城市扩建的规划是个令人头疼的大问题。规划师设计了一个极其复杂的方案:当城市规模扩大之后,把与原来城市结构一样的区域复制或旋转90度之后建设在原来的城市周围(详细地说,将原来的城市复制一遍放在原城市上方,将顺时针旋转90度后的城市放在原城市的左上方,将逆时针旋转90度后的城市放在原城市的左方),再用道路将四部分首尾连接起来,如下图所示。
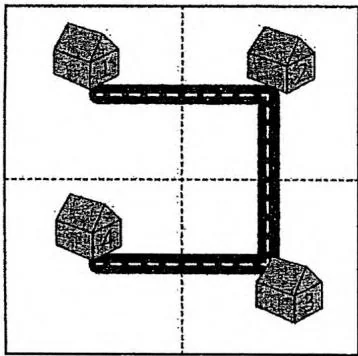
等级1
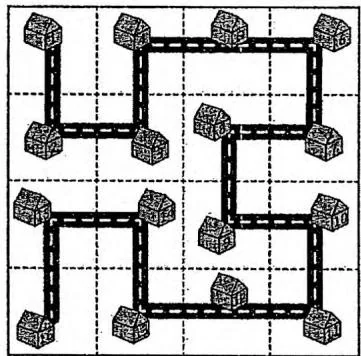
等级2

等级3
容易看出,扩建后的城市的各个房屋仍然由一条道路连接。定义 级城市为拥有
座房屋的城市。对于任意等级的城市,从左上角开始沿着唯一的道路走,依次为房屋标号,就能够得到每间房屋的编号了。住在其中两间房屋里的人们想知道,如果城市发展到了一定等级,他俩各自所处的房屋之间的直线距离是多少。你可以认为图中的每个格子都是边长为10米的正方形,房屋均位于每个格子的中心点上( 次询问,每次输入等级 ,两个编号 、 ,求 与 之间的直线距离, , )。
这就是著名的通过一定规律无限包含自身的“分形”图。关键是要解决:求编号为 的房屋在旋转 度的 级城市中的位置( 或 270,逆时针为正方向)。把该问题记为 ,本题就是求 与 的距离。
记一个旋转 度的 级城市为 。当 时,该城市由四部分组成,左上是 ,左下是 ,右上和右下是 。已知 与 后很容易算出该城市道路依次经过其四个部分的顺序,通过 在 四等分的大小位置可以确定 位于哪一部分(记为 )。把之前经过的几个部分的房屋数量从 中减去(记为 ),然后递归求解 即可。
递归的机器实现
递归在计算机中是如何实现的呢?换句话说,它最终被编译成什么样的机器语言?这就要从函数调用说起。实际上,一台典型的32位计算机采用“堆栈结构”来实现函数调用,它在汇编语言中,把函数所需的第 个,第 个,……,第1个参数依次入栈,然后执行call(address)指令。该指令把返回地址(当前语句的下一条语句的地址)入栈,然后跳转到address位置的语句。在函数返回时,它执行ret指令。该指令把返回地址出栈,并跳转到该地址继续执行。
对于函数中定义的 局部变量,在每次执行 call 与 ret 指令时,也会在“栈”中相应地保存与复原,而作用范围超过该函数的变量,以及通过 new 和 malloc 函数动态分配的空间则保存在另一块称为“堆”(注意,这个堆与我们所说的二叉堆是两个不同的概念)的结构中。栈指针、返回值、局部的运算会借助 CPU 的“寄存器”完成。
由此我们就可以理解到:
局部变量在每层递归中都占有一份空间,声明过多或递归过深就会超过“栈”所能存储的范围,造成栈溢出。
非局部变量对于各层递归都共享同一份空间,需要及时维护、还原现场,以防止在各层递归之间存储和读取的数据互相影响。
了解了递归的机器实现之后,我们就可以使用模拟的方法,把递归程序改写为非递归程序。具体来说,我们可以使用一个数组来模拟栈,使用变量来模拟栈指针和返回值,使用 switch/case 或者 goto/label 来模拟语句跳转。
【例题】非递归实现组合型枚举
把“递归实现组合型枚举”这道例题的程序通过模拟递归的方法改写为非递归版本。
vector<int> chosen;
int stack[100010], top = 0, address = 0, n, m;
void call(int x, int ret_addr) { // 模拟计算机汇编指令 call
int old_top = top;
stack[++top] = x; // 参数 x
stack[++top] = ret_addr; // 返回地址标号
stack[++top] = old_top; // 在栈顶记录以前的 top 值
}
int ret() { // 模拟计算机汇编指令 ret
int ret_addr = stack[top - 1];
top = stack[top]; // 恢复以前的 top 值
return ret_addr;
}
int main() {
cin >> n >> m;
call(1, 0); // calc(1)
while (top) {
int x = stack[top - 2]; // 获取参数
switch (address) {
case 0:
if (chosen.size() > m || chosen.size() + (n - x + 1) < m) {
address = ret(); // return continue;
}
}
if (x == n + 1) {
for (int i = 0; i < chosen.size(); i++)
puts("%d", chosen[i]);
}
}
call(x + 1, 1); // 相当于 calc(x + 1), 返回后会从 case 1 继续 address = 0;continue; //回到while循环开头,相当于开始新的递归
case 1:
chosen.push_back(x);
call(x+1, 2); //相当于calc(x+1),返回后会从case2继续
address = 0;
continue; //回到while循环开头,相当于开始新的递归
case 2:
chosen.pop_back();
address = ret(); //相当于原calc函数结尾,执行return
}
}