0x67_Tarjan算法与有向图连通性
0x67 Tarjan 算法与有向图连通性
给定有向图 ,若存在 ,满足从 出发能够到达 中所有的点,则称 是一个“流图”(Flow Graph),记为 ,其中 称为流图的源点。
与无向图的深度优先遍历类似,我们也可以定义“流图”的搜索树和时间戳的概念:
在一个流图 上从 出发进行深度优先遍历,每个点只访问一次。所有发生递归的边 (换言之,从 到 是对 的第一次访问)构成一棵以 为根的树,我们把它称为流图 的搜索树。
同时,在深度优先遍历的过程中,按照每个节点第一次被访问的时间顺序,依次给予流图中 个节点 的整数标记,该标记被称为时间戳,记为 。
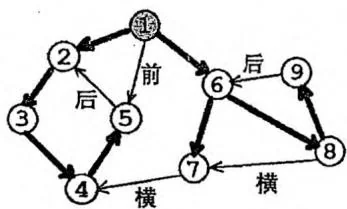
流图中的每条有向边 必然是以下四种之一:
1.树枝边,指搜索树中的边,即 是 的父节点。
2. 前向边,指搜索树中 是 的祖先节点。
3.后向边,指搜索树中 是 的祖先节点。
4. 横叉边,指除了以上三种情况之外的边,它一定满足 。
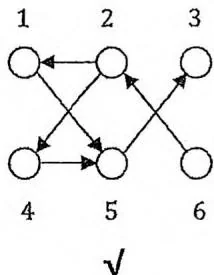
下图画出了一个“流图”以及它的搜索树、时间戳、边的分类。圆圈中的数字是时间戳。粗边是树枝边,并构成一棵搜索树。前向边、后向边与横叉边用第一个汉字标注。
有向图的强连通分量
给定一张有向图。若对于图中任意两个节点 ,既存在从 到 的路径,也存在从 到 的路径,则称该有向图是“强连通图”。
有向图的极大强连通子图被称为“强连通分量”,简记为 。此处“极大”的
含义与双连通分量“极大”的含义类似。
Tarjan 算法基于有向图的深度优先遍历,能够在线性时间内求出一张有向图的各个强连通分量。
一个“环”一定是强连通图。如果既存在从 到 的路径,也存在从 到 的路径,那么 显然在一个环中。因此,Tarjan 算法的基本思路就是对于每个点,尽量找到与它一起能构成环的所有节点。
容易发现,“前向边” 没有什么用处,因为搜索树上本来就存在从 到 的路径。“后向边” 非常有用,因为它可以和搜索树上从 到 的路径一起构成环。“横叉边” 视情况而定,如果从 出发能找到一条路径回到 的祖先节点,那么 就是有用的。
为了找到通过“后向边”和“横叉边”构成的环,Tarjan算法在深度优先遍历的同时维护了一个栈。当访问到节点 时,栈中需要保存以下两类节点:
1.搜索树上 的祖先节点,记为集合anc(x)。
设 。若存在后向边 ,则 与 到 的路径一起形成环。
已经访问过,并且存在一条路径到达 的节点。
设 是一个这样的点,从 出发存在一条路径到达 。若存在横叉边 ,则 、 到 的路径、 到 的路径形成一个环。
综上所述,栈中的节点就是能与从 出发的“后向边”和“横叉边”形成环的节点。进而可以引入“追溯值”的概念。
追溯值
设 表示流图的搜索树中以 为根的子树。 的追溯值 定义为满足以下条件的节点的最小时间戳:
该点在栈中。
2.存在一条从subtree 出发的有向边,以该点为终点。
根据定义,Tarjan算法按照以下步骤计算“追溯值”:
当节点 第一次被访问时,把 入栈,初始化 。
扫描从 出发的每条边 。
(1) 若 没被访问过,则说明 是树枝边,递归访问 ,从 回溯之后,令 。
(2) 若 被访问过并且 在栈中,则令 。
从 回溯之前,判断是否有 。若成立,则不断从栈中弹出节点,直至 出栈。
下页图中的中括号[]里的数值标注了每个节点的“追溯值”low。读者可以尝试在图中模拟low的计算过程。
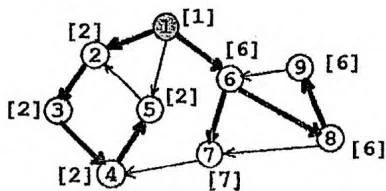
强连通分量判定法则
在追溯值的计算过程中,若从 回溯前,有 成立,则栈中从 到栈顶的所有节点构成一个强连通分量。
我们不再详细证明。大致来说,在计算追溯值的第3步,如果 ,那么说明 subtree(x) 中的节点不能与栈中其他节点一起构成环。另外,因为横叉边的终点时间戳必定小于起点时间戳,所以 subtree(x) 中的节点也不可能直接到达尚未访问的节点(时间戳更大)。综上所述,栈中从 到栈顶的所有节点不能与其他节点一起构成环。
又因为我们及时进行了判定和出栈操作,所以从 到栈顶的所有节点独立构成一个强连通分量。
下面的程序实现了Tarjan算法,求出数组 ,其中 表示 所在的强连通分量的编号。另外,它还求出了vector数组 , 记录了编号为 的强连通分量中的所有节点。整张图共有cnt个强连通分量。
const int N = 100010, M = 1000010;
int ver[M], Next[M], head[N], dfn[N], low[N];
int stack[N], ins[N], c[N];
vector<int> scc[N];
int n, m, tot, num, top, cnt;
void add(int x, int y) {
ver[++tot] = y, Next[tot] = head[x], head[x] = tot;
}
void tarjan(int x) {
dfn[x] = low[x] = ++num;
stack[++top] = x, ins[x] = 1;
for (int i = head[x]; i; i = Next[i])
if (!dfn[ver[i]]) {
tarjan(very[i]);
low[x] = min(low[x], low[ver[i]]);
}
return (x);
}} else if (ins[ver[i]]) low[x] $=$ min(low[x],low[ver[i]]); if (dfn[x] $\equiv$ low[x]) { cnt++; int y; do { y $=$ stack[top--],ins[y] $= 0$ . c[y] $=$ cnt, scc[cnt].push_back(y); } while $(x! = y)$ 1
}
int main() { cin >> n >> m; for (int i $= 1$ ;i $< =$ m;i++) { int x,y; scanf("%d%d",&x,&y); add(x,y); } for (int i $= 1$ ;i $< =$ n;i++) if (!dfn[i]) tarjan(i);与无向图 e-DCC 的“缩点”类似,我们也可以把每个 SCC 缩成一个点。对原图中的每条有向边 ,若 ,则在编号为 与编号为 的 SCC 之间连边。最后,我们会得到一张有向无环图。下面的程序对 SCC 执行缩点过程,并把新得到的有向无环图保存在另一个邻接表中。
void add_c(int x, int y) {
vc[++tc] = y, nc[tc] = hc[x], hc[x] = tc;
}
// 在 main 函数中
for (int x = 1; x <= n; x++)
for (int i = head[x]; i; i = Next[i]) {
int y = ver[i];
if (c[x] == c[y]) continue;
add_c(c[x], c[y]);
}
}【例题】Network of Schools POJ1236
一些学校连接在一个计算机网络上,学校之间存在软件支援协议,每个学校都有它应支援的学校名单(学校 支援学校 ,并不表示学校 一定支援学校 。当某校获得一个新软件时,无论是直接获得还是通过网络获得,该校都应立即将这个软件通过网络传送给它应支援的学校。因此,一个新软件若想让所有学校都能使用,只需将其提供给一些学校即可。
最少需要将一个新软件直接提供给多少个学校,才能使软件能够通过网络被传送到所有学校?
最少需要添加几条新的支援关系,使得将一个新软件提供给任何一个学校,其他所有学校就都可以通过网络获得该软件?
把学校看作节点,若学校 能支援学校 ,则从 到 连一条有向边,得到一张有向图。在图中的一个强连通分量内,任意两个点都是互相可达的。因此,只要其中任何一个学校获得新软件,该强连通分量内的其他所有学校都可以通过网络获得这个新软件。
可以用 Tarjan 算法求出所有强连通分量,并执行“缩点”过程,得到一张有向无环图。首先,“零入度点”无法被其他学校支援。其次,若同时向所有“零入度点”提供新软件,则新软件从这些点出发沿着网络显然能遍历到整个有向无环图。综上所述,第一问的答案就是有向无环图中“零入度点”的个数。
第二问就是问最少添加几条有向边,可以把一张任意有向图变成强连通图。设缩点后的有向无环图中有 个“零入度点”, 个“零出度点”,那么答案就是 。请读者自己思考该结论的正确性。特别地,如果整张图本身就是一个强连通图(缩点后仅剩一个点),那么答案为0。
【例题】银河 BZOJ2330
银河中的恒星浩如烟海,但是我们只关注那些最亮的恒星。我们用一个正整数来表示恒星的亮度,数值越大则恒星就越亮,恒星的亮度最暗是1。现在对于 颗我们关注的恒星,有 对亮度之间的相对关系已经判明。你的任务就是求出这 颗恒星的亮度值总和至少有多大。
输入数据的第一行给出两个整数 和 。 。之后 行,每行三个整数 ,表示一对恒星 之间的亮度关系。恒星的编号从1开始。
如果 ,说明 和 亮度相等。
如果 ,说明 的亮度小于 的亮度。
如果 ,说明 的亮度不小于 的亮度。
如果 ,说明 的亮度大于 的亮度。
如果 ,说明 的亮度不大于 的亮度。
输出一个整数表示答案。若无解,则输出-1。
设 表示 的亮度 。把五种关系的形式进行统一:
关系 可以转化为 并且 。
关系 可以转化成 。
关系 可以转化成 。
关系 可以转化成 。
关系 可以转化成 。
另外,题目明确指出恒星的亮度最暗是1,可以设 ,然后把这个条件写作
根据 节“差分约束”的知识,对于每个形如 的不等式,从节点 到节点 连长度为 的有向边,然后从0号节点出发,求单源最长路。若图中有正环,则无解。否则,从0到每个节点的最长路的长度就是对应恒星的最小合法亮度。
然而,本题数据范围达到了 级别,并且数据较强,直接用SPFA算法求最长路并判断是否存在正环会超时。我们需要一个效率更高的算法。
仔细观察,我们根据差分约束系统建立的有向图中,边权只有0和1两种。如果图中存在一个环,那么环上的边长度必须都是0,不然一定无解。因此,我们可以用Tarjan算法求出有向图中所有的强连通分量,只要强连通分量内部存在长度为1的边,就直接判定无解。
如果有解,那么每个强连通分量内部各个恒星的亮度是相等的,可以执行“缩点”,得到一张边权为0或1的有向无环图。从节点0所在的SCC出发,按照拓扑序执行动态规划,即可在 的时间内求出到达每个SCC的最长路,即该SCC内所有恒星的最小亮度。
有向图的必经点与必经边
给定一张有向图,起点为 ,终点为 。若从 到 的每条路径都经过一个点 则称点 是有向图中从 到 的必经点。
若从 到 的每条路径都经过一条边 ,则称这条边是有向图中从 到 的必经边或“桥”。
有向图的必经点与必经边是一个较难的问题。因为环上的点也可能是必经点,所以不能简单地把强连通分量缩点后按照有向无环图来处理。Lenguar-Tarjan 算法通过计算支配树(Dominator-Tree),能够在 的时间内求出从有向图的指定起点出发,
走到每个点的必经点集。这超出了我们的讨论范围,感兴趣的读者可以阅读本书作者在全国信息学奥林匹克竞赛冬令营上的讲义《图连通性若干拓展问题探讨》,本书配套光盘提供了该讲义的最新修订版本。
不过,值得一提的是,我们有很简单的方法计算有向无环图的必经点与必经边:
在原图中按照拓扑序进行动态规划,求出起点 到图中每个点 的路径条数 。
在反图上再次按照拓扑序进行动态规划,求出每个点 到终点 的路径条数 。
显然, 表示从 到 的路径总条数。根据乘法原理:
对于一条有向边 ,若 ,则 是有向无环图从 到 的必经边。
对于一个点 ,若 ,则 是有向无环图从 到 的必经点。
路径条数是一个指数级别的整数,通常超过了32位或64位整数的表示范围。受Hash思想的启发,我们可以把路径条数对一个大质数取模后再保存到 与 数组中。这样带来的后果是有较小的概率会产生误判。保险起见,若题目时限宽松,我们可以多选取几个质数,分别作为模数进行计算。
【例题】PKU ACM Team's Excursion
给定一张 个点 条边的有向无环图,每条边都有一个长度。给定一个起点 和一个终点 。若从 到 的每条路径都经过某条边,则称这条边是有向图的必经边或桥。
PKU ACM 队要从 点到 点。他们在路上可以搭乘两次车。每次可以从任意位置(甚至是一条边上的任意位置)上车,从任意位置下车,但连续乘坐的长度不能超过 米。除去这两次乘车外,剩下的路段步行。定义从 到 的路径的危险程度等于步行经过的桥上路段的长度之和。求从 到 的最小危险程度是多少。
数据范围:
首先,用前面提到的计算路径条数(并取模)的方法,求出从 到 的所有“桥”。根据贪心策略,因为“桥”是从 到 的任意一条路径都包含的边,所以我们应该让路径上除了“桥”以外的部分尽量短。并且我们只关心长度,不关心“桥”以外的部分到底是哪些边。所以我们可以求出从 到 的任意一条最短路,考虑在这条最短路径的什么地方搭车,能使危险程度最小。
一条最短路其实就是一条“链”,我们要用两个区间覆盖链上两段长度不超过 的部分,使未被覆盖的桥的长度之和最小。
如果只有一个区间,那么是非常好做的。可以正着扫描一遍这条最短路,用动态规划算法求出 ,表示从 到最短路上的第 个节点,只搭一次车的最小危险程度。请读者自己写出该DP算法的详细过程。
类似地,还可以倒着扫描一遍,用动态规划算法求出 ,表示从最短路上的第 个节点到 ,只搭一次车的最小危险程度。
最后,我们枚举“切点” ,用 更新答案即可。
2-SAT 问题
有 个变量,每个变量只有两种可能的取值。再给定 个条件,每个条件都是对两个变量的取值限制。求是否存在对 个变量的合法赋值,使 个条件均得到满足。这个问题被称为2-SAT问题。SAT是英文satisfiability的缩写,所以2-SAT也可翻译为“2-可满足性”问题。
设一个变量 的两种可能取值分别是 和 。在2-SAT问题中, 个条件都可以转化为统一的形式——“若变量 赋值为 ,则变量 必须赋值为 ”,其中 。
2-SAT问题的判定方法如下:
建立 个节点的有向图,每个变量 对应2个节点,一般设为 和 。
考虑每个条件,形如“若变量 赋值为 ,则变量 必须赋值为 ”, 。从 到 连一条有向边。
注意,上述条件蕴含着它的逆否命题“若变量 必须赋值为 ,则变量 必须赋值为 ”。如果在给出的 个限制条件中,原命题和逆否命题不一定成对出现,应该从 到 也连一条有向边。
总而言之,根据原命题和逆否命题的对称性,2-SAT建出的有向图一定能画成“一侧是节点 ,另一侧是节点 ”。当把图中的边看作无向边时,这两侧连边的情况是对称的。
用 Tarjan 算法求出有向图中所有的强连通分量。
若存在 ,满足 和 属于同一个强连通分量,则表明:若变量 赋值为 ,则变量 必须赋值为 。这显然是矛盾的,说明问题无解。若不存在这样的 ,则问题一定有解,我们后面会探讨如何给出一种合法的赋值方案。
时间复杂度为 。
我们在0x41节讲解了利用并查集处理二元关系的一类模型,前提是关系具有传递性,并且关系是“无向”的。无向关系可以理解为:从原命题“若 则 ”能推出逆
命题“若 则 ”、逆否命题“若非 则非 ”、否命题“若非 则非 ”。在扩展了一倍域的并查集中,对于每条关系我们会添加两条无向边,其实就等价于上述2-SAT的四个命题对应的四条有向边。
而在2-SAT模型中,关系是“有向”的。有向关系就是一般的关系,从原命题“若 则 ”一定能推出逆否命题“若非 则非 ”,但不一定能推出逆命题“若 则 ”、否命题“若非 则非 ”。我们也不用强调关系的传递性,因为“若 则 ”和“若 则 ”两个命题自然能推出命题“若 则 ”。总而言之,2-SAT模型符合二元关系的一般逻辑,能处理更多、更复杂的问题。
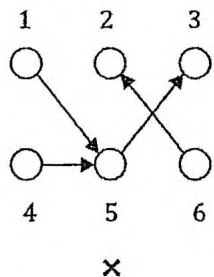
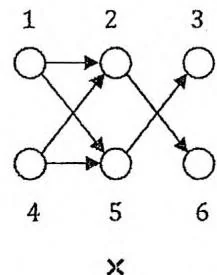
如下图所示,设变量数 ,13三个点代表三个变量的第一种赋值,46三个点代表变量的第二种赋值。前两种情况都不可能是2-SAT问题对应的有向图,因为命题“若1则5”的逆否命题“若2则4”未在图中体现。第三种情况可能是某个2-SAT问题对应的有向图,其中一组解是选择1,3,5三个点代表的赋值。
【例题】Katu Puzzle POJ3678
有 个变量 , 每个变量的可能取值是 0 或 1。给定 个算式, 每个算式形如 , 其中 是两个变量的编号, 是数字 0 或 1, op 是 and, or, xor 三个位运算之一。求是否存在对每个变量的合法赋值, 使所有算式都成立。
数据范围: 。
如果只有 xor 运算,那么可以用扩展域的并查集来解决本题。现在有 and, or, xor 三种运算,我们先尝试把它们转化成 2-SAT 能接受的统一的形式。
设节点 表示变量 赋值为 0,节点 表示 赋值为 1。
and
这表示 其中一个赋值为 1 时,另一个必须赋值为 0。
若 ,则必须 。从 到 连有向边。
若 ,则必须 。从 到 连有向边。
and
这表示 两个变量都必须赋值为1。该关系可由2条有向边描述——若赋值
为0,让它直接产生矛盾即可。
若 ,则必须 。从 到 连有向边。
若 ,则必须 。从 到 连有向边。
or
与第1种情况类似,连边 , 。
or
与第2种情况类似,连边 , 。
xor
连边 , , , 。
xor
连边 , , , 。
可以发现,在我们添加的有向边中,“原命题”和“逆否命题”是成对出现的。用Tarjan算法求出有向图中所有的强连通分量,检查是否存在 和 属于同一个SCC即可。
【例题】Priest John's Busiest Day POJ3683
在一个城镇流传着一个古老的传说,在9月1日那天结婚的情侣将收到上帝的祝福和保佑。因此,城镇的牧师John在每年的9月1日都很忙碌。今年的9月1日,有N对情侣准备结婚 ,每对情侣都预先计划好了婚礼举办的时间,其中第 对情侣的婚礼从时刻 开始,到时刻 结束(精确到分钟)。
婚礼有一个必需的仪式:站在牧师面前聆听上帝的祝福。这个仪式要么在婚礼开始时举行,要么在结束前举行。第 对情侣需要 分钟完成这个仪式,即必须选择 和 两个时间段之一。牧师想知道他能否满足每场婚礼的要求,即给每对情侣安排 或 ,使得这些仪式的时间段不重叠。若能满足,还需要帮牧师求出任意一种具体方案。
在本题中,每场婚礼是一个变量,有“开始时举行仪式”和“结束前举行仪式”两种取值,分别记为 和 ,并看作节点 和 。
枚举每两场婚礼 ,若婚礼 的 时间段与婚礼 的 时间段重叠,则说明二者不能同时被选为最终赋值。转化成2-SAT接受的形式,应该连 和 两条有向边。二者互为逆否命题。
用 Tarjan 算法求 SCC,检查是否存在 和 在同一 SCC 即可。本题还需要输出方案。下面我们给出 2-SAT 合法方案的两种构造方法。
首先,在一个SCC中,只要确定了一个变量的赋值,该SCC内其他变量的赋值也
就直接确定了,这启发我们考虑缩点。其次,因为互为“逆否命题”的有向边在图中成对出现,所以一个“零出度点”对面的点一定有出边(例如391页图中第三种情况的点3和点6)。选择一个“有出边的点”会使得该边指向的点必须也被选择,而选择一个“零出度点”不会对其它任何点造成影响。
根据上述讨论,第一种构造方法的基本思想就是:自底向上执行拓扑排序,不断尝试选择零出度点。详细流程如下:
把 SCC 缩点。因为一般的拓扑排序是“自顶向下”根据“入度”进行的,所以我们建立一张缩点后的“反图”。具体来说:
(1) 图上每个点都对应原图的 SCC。
(2) 原图中的边 转化为新图中的边 ,其中 , 表示节点 所在的 SCC 的编号。
(3) 对于原图中每个点 , 和 就是新图中两个对称的节点。
简便起见,记 , 。
在上述“反图”上统计每个点的入度,执行拓扑排序。
设 表示原图 号 SCC 的赋值标记,初始值为 -1。
从队头每取出一个节点 ( 相当于原图中一个SCC的编号),就检查 的赋值标记。若 (尚未确定赋值),就令 , 。
拓扑排序结束之后,就得到了最终的答案。对于原图每个节点
若 ,则变量 应赋值为 。
若 ,则变量 应赋值为 。
读者在本书配套光盘中可以找到第一种构造方法的参考程序。
第二种构造方法在第一种构造方法的基础上,进一步利用了本节给出的“Tarjan求SCC的程序”对SCC编号的特殊性质,使得构造过程十分简洁。注意到Tarjan算法的本质是一次DFS,它在回溯时会先取出有向图“底部”的SCC进行标记。故Tarjan算法得到的SCC编号本身就已经满足缩点后的有向无环图中“自底向上”的拓扑序。
下面的代码无需进行缩点,直接比较节点所在的 SCC 的编号 的大小,即可确定变量的赋值 。若 ,则变量 应赋值为 。若 ,则变量 应赋值为 。本书配套光盘提供了该方法的完整参考程序。
for (int i = 1; i <= 2 * n; i++)
if (!dfn[i]) tarjan(i);
for (int i = 1; i <= n; i++) {
if (c[i] == c[n + i]) { puts("NO"); return 0;}
opp[i] = n + i, opp[n + i] = i;
}puts("YES");
for (int i = 1; i <= 2 * n; i++)
val[i] = c[i] > c[opp[i]];