4.2_参数附加方法
4.2 参数附加方法
参数附加方法(Additional Parameter Methods)通过增加并训练新的附加参数或模块对大语言模型进行微调。参数附加方法按照附加位置可以分为三类:加在输入、加在模型以及加在输出。本节将对三类方法的各自代表性工作进行具体介绍。
4.2.1 加在输入
加在输入的方法将额外参数附加到模型的输入嵌入(Embedding)中,其中最经典的方法是 Prompt-tuning [23]。Prompt-tuning 在模型的输入中引入可微分的连续张量,通常也被称为软提示(Soft prompt)。软提示作为输入的一部分,与实际的文本数据一起被送入模型。在微调过程中,仅软提示的参数会被更新,其他参数保持不变,因此能达到参数高效微调的目的。
具体地,给定一个包含 个 token 的输入文本序列 ,首先通过嵌入层将其转化为输入嵌入矩阵 ,其中 是嵌入空间的维度。新加入的软提示参数被表示为软提示嵌入矩阵 ,其中 是软提示长度。然后,将软提示嵌入拼接上输入嵌入矩阵,形成一个新矩阵 ,最后输入 Transformer 模型。通过反向传播最大化输出概率似然进行模型训练。训练过程仅软提示参数 被更新。图 4.3 给出了 Prompt-tuning 的示意图。
在实际使用中,软提示的长度范围是1到200,并且通常在20以上就能有一定的性能保证。此外,软提示的初始化对最终的性能也会有影响,使用词表中的token或者在分类任务中使用类名进行初始化会优于随机初始化。值得一提的是,Prompt-tuning原本被提出的动机不是为了实现参数高效微调,而是自动学习提示词。在第三章我们提到,利用大语言模型的常见方式是通过提示工程,也被称为是硬提示(Hard prompt),这是因为我们使用的离散prompt是不可微分的。问题在于
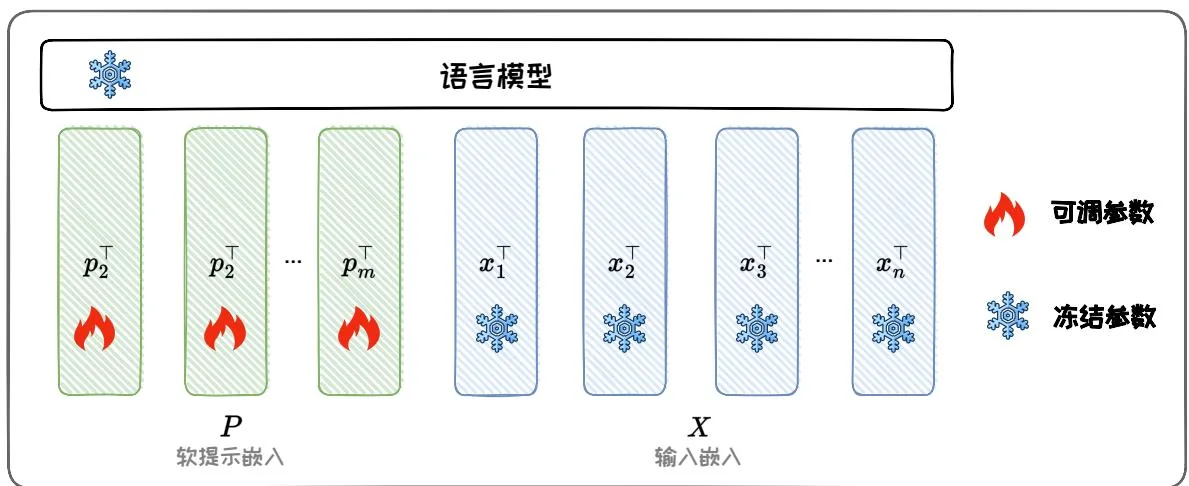
图4.3: Prompt-tuning示意图。
大语言模型的输出质量高度依赖于提示词的构建,要找到正确的“咒语”使得我们的大语言模型表现最佳,需要花费大量时间。因此,采用可微分的方式,通过反向传播自动优化提示词成为一种有效的方法。
总的来说,Prompt-tuning有以下优势:(1)内存效率高:Prompt-tuning显著降低了内存需求。例如,T5-XXL模型对于特定任务的模型需要11B参数,但经过Prompt-tuning的模型只需要20480个参数(假设软提示长度为5);(2)多任务能力:可以使用单一冻结模型进行多任务适应。传统的模型微调需要为每个下游任务学习并保存任务特定的完整预训练模型副本,并且推理必须在单独的批次中执行。Prompt-tuning只需要为每个任务存储一个特定的小的任务提示模块,并且可以使用原始预训练模型进行混合任务推理(在每个任务提示词前加上学到的softprompt)。(3)缩放特性:随着模型参数量的增加,Prompt-tuning的性能会逐渐增强,并且在10B参数量下的性能接近(多任务)全参数微调的性能。
4.2.2 加在模型
加在模型的方法将额外的参数或模型添加到预训练模型的隐藏层中,其中经典的方法有 Prefix-tuning [24]、Adapter-tuning [18] 和 AdapterFusion [35]。
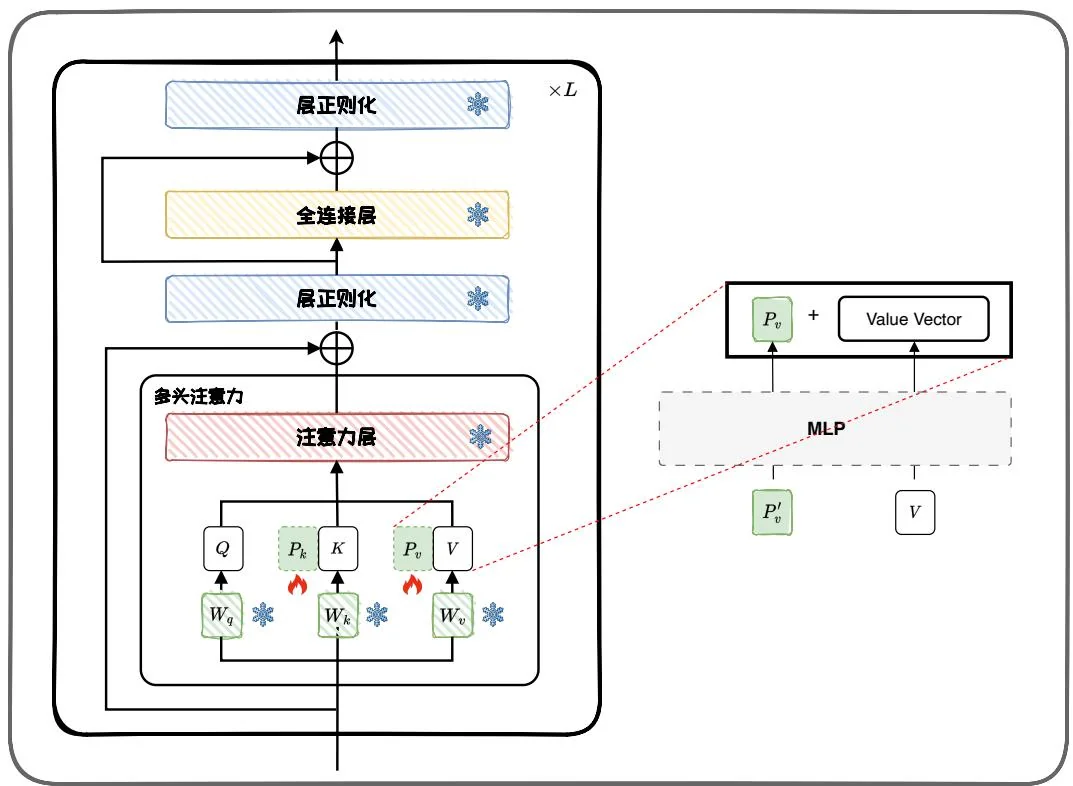
图4.4: Prefix-tuning示意图。
1. Prefix-tuning
Prefix-tuning 和上一节介绍的 Prompt-tuning 十分类似,区别在于 Prompt-tuning 仅将软提示添加到输入嵌入中,而 Prefix-tuning 将一系列连续的可训练前缀(Prefixes,即 Soft-prompt)插入到输入嵌入以及 Transformer 注意力模块中,如图 4.4 所示, 和 是插入到 Transformer block 中的前缀。相比 Prompt-tuning, Prefix-tuning 大幅增加了可学习的参数量。
具体而言,Prefix-tuning引入了一组可学习的向量 和 ,这些向量被添加到所有Transformer注意力模块中的键 和值 之前。类似于Prompt-tuning,Prefix-tuning也会面临前缀参数更新不稳定的问题,从而导致优化过程难以收敛。因此,在实际应用中,通常需要在输入Transformer模型前,先通过一个多层感知机(MLP)进行重参数化。这意味着需要训练的参数包括MLP和前缀矩阵两部分。训练完成后,MLP的参数会被丢弃,仅保留前缀参数。总的来说,Prefix-tuning有
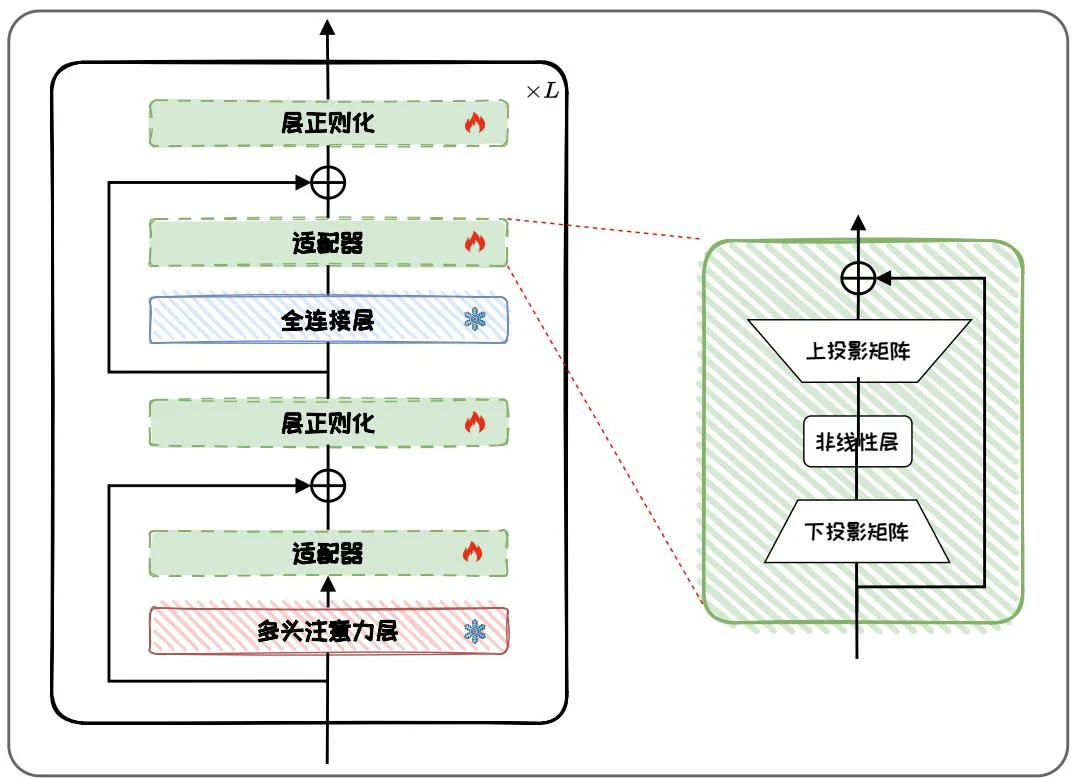
图4.5:Adapter-tuning示意图。
以下优势:(1)参数效率:只有前缀参数在微调过程中被更新,这显著减少了训练参数量;(2)任务适应性:前缀参数可以针对不同的下游任务进行定制,微调方式灵活;(3)保持预训练知识:由于预训练模型的原始参数保持不变,Prefix-tuning能够保留预训练过程中学到的知识。
2. Adapter-tuning
Adapter-tuning [18] 向预训练语言模型中插入新的可学习的神经网络模块,称为适配器(Adapter)。适配器模块通常采用瓶颈(Bottomneck)结构,即一个上投影层、一个非线性映射和一个下投影层组成的全连接模块。其中,下投影层将信息压缩到一个低维的表示,经过非线性映射后再通过上投影层扩展回原始维度。如图 4.5 所示,Adapter-tuning 在 Transformer 的每一个多头注意力层(Multi-head Attention Layer,图中红色块)和全连接层(Feed-forward Network Layer,图中蓝色块)之后添加适配器。与 Transformer 的全连接层不同,由于采用了瓶颈结构,适
配器的隐藏维度通常比输入维度小。和其他PEFT方法类似,在训练时,通过固定原始模型参数,仅对适配器、层正则化(图中绿色框)以及最后的分类层参数(图中未标注)进行微调,可以大幅缩减微调参数量和计算量,从而实现参数高效微调。适配器模块的具体结构如图4.5右边所示,适配器模块通常由一个下投影矩阵 和一个上投影矩阵 以及残差连接组成,其中
其中, 是激活函数,如ReLU或Sigmoid。 是适配器的输出, 是第 层的隐藏状态。
在适配器中,下投影矩阵将输入的 维特征压缩到低维 ,再用上投影矩阵投影回 维。因此,每一层中的总参数量为 ,其中包括投影矩阵及其偏置项参数。通过设置 ,可以大幅限制每个任务所需的参数量。进一步地,适配器模块的结构还可以被设计得更为复杂,例如使用多个投影层,或使用不同的激活函数和参数初始化策略。此外,Adapter-tuning 还有许多变体,例如通过调整适配器模块的位置 [14, 56]、剪枝 [15] 等策略来减少可训练参数的数量。
3. AdapterFusion
由于Adapter-tuning无需更新预训练模型,而是通过适配器参数来学习单个任务,每个适配器参数都保存了解决该任务所需的知识。因此,如果想要结合多个任务的知识,可以考虑将多个任务的适配器参数结合在一起。基于该思路,AdapterFusion提出一种两阶段学习的方法,先学习多个任务,对每个任务进行知识提取;再“融合”(Fusion)来自多个任务的知识。具体的两阶段步骤如下:
第一阶段:知识提取。给定 个任务,首先对每个任务分别训练适配器模块,用于学习特定任务的知识。该阶段有两种训练方式,分别如下:
Single-Task Adapters(ST-A): 对于 个任务, 模型都分别独立进行优化, 各个任务之间互不干扰, 互不影响。
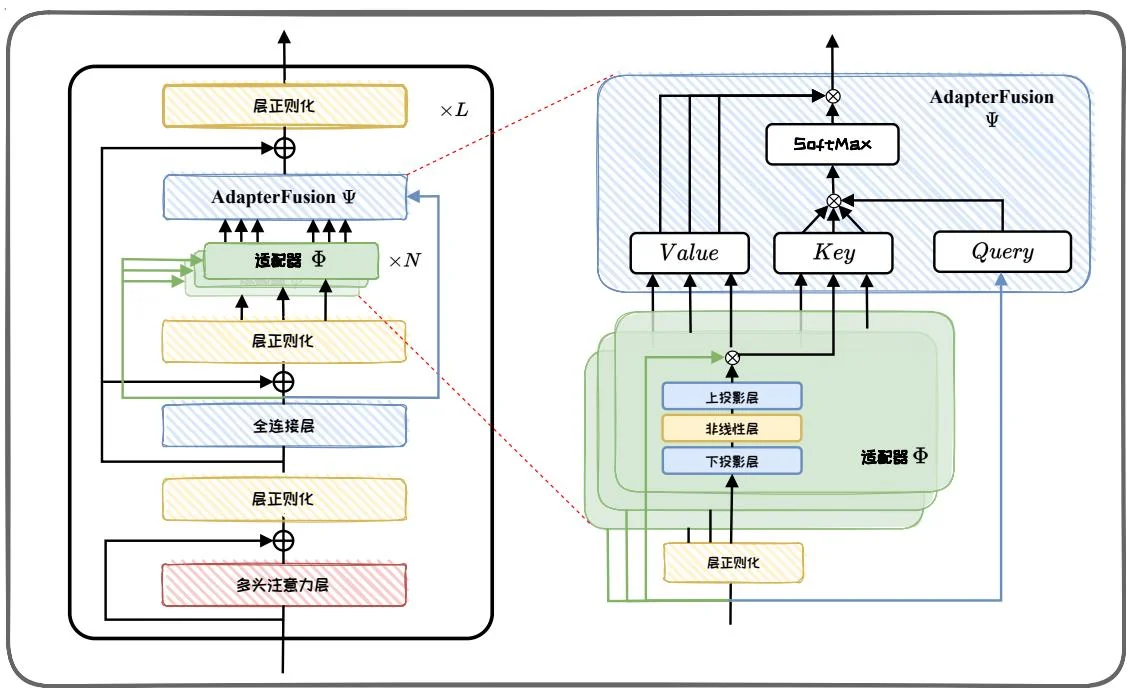
图4.6: AdapterFusion示意图。
Multi-Task Adapters(MT-A): 通过多任务学习对 个任务进行联合优化。
第二阶段:知识组合。单个任务的适配器模块训练完成后,AdapterFusion将不同适配器模块进行融合(Fusion),以实现知识组合。该阶段引入一个新的融合模块,该模块旨在搜索多个任务适配器模块的最优组合,实现任务泛化。在该阶段,语言模型的参数以及 个适配器的参数被固定,仅微调AdapterFusion模块的参数,并优化以下损失:
其中, 是第 个任务的训练数据, 是第 个任务的损失函数, 表示预训练模型参数, 表示第 个任务的适配器模块参数, 是融合模块参数。图4.6给出AdapterFusion的示意图。每层的AdapterFusion模块包括可学习的Key(键)、Value(值)和Query(查询)等对应的投影矩阵。全连接层的输出当作Query,适配器的输出当作Key和Value,计算注意力得到联合多个适配器的输出结果。此外,在不同的适配器模块间参数共享融合模块,可以进一步减少参数数量。
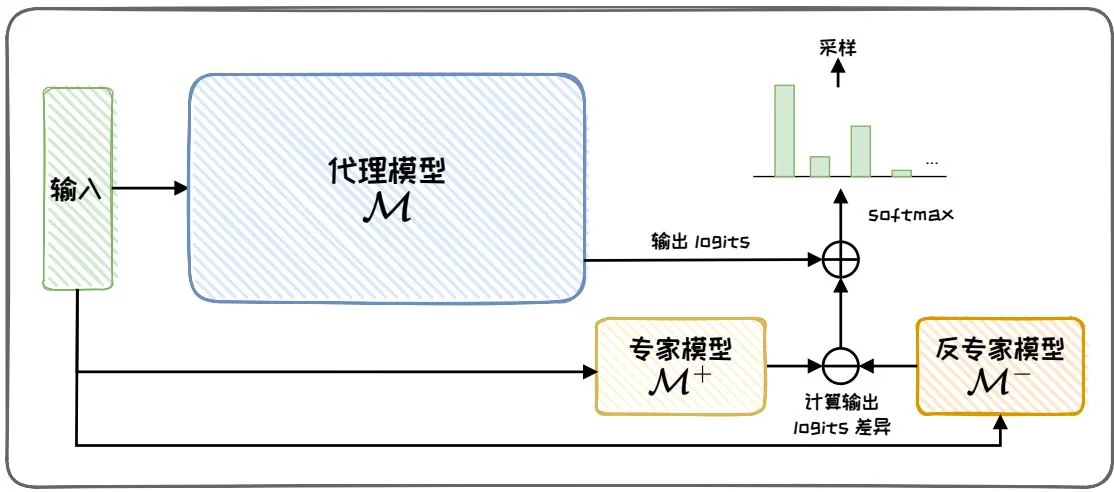
图4.7: Proxy-tuning示意图。
4.2.3 加在输出
在微调大语言模型时,通常会面临以下问题:首先,大语言模型的参数数量可能会非常庞大,例如LLaMA系列最大的模型拥有70B参数,即使采用了PEFT技术,也难以在普通消费级GPU上完成下游任务适应;其次,用户可能无法直接访问大语言模型的权重(黑盒模型),这为微调设置了障碍。
为了应对这些问题,代理微调(Proxy-tuning)[27]提供了一种轻量级的解码时(Decoding-time)算法,允许我们在不直接修改大语言模型权重的前提下,通过仅访问模型输出词汇表预测分布,来实现对大语言模型的进一步定制化调整。
如图4.7所示,给定待微调的代理模型 以及较小的反专家模型(Anti-expert model) ,这两个模型需要相同的词汇表。我们对 进行微调,得到微调后的专家模型(Expert model) 。在每一个自回归生成的时间步中,代理微调首先计算专家模型 和反专家模型 之间的logits分布差异,然后将其加到代理模型 下一个词预测的logits分布中。具体来说,在代理微调的计算阶段,针对每一时间步 的输入序列 ,从代理模型 、专家模型 和反专家模型
中获取相应的输出分数 。通过下式调整目标模型的输出分数
然后,使用softmax(·)对其进行归一化,得到输出概率分布,
最后,在该分布中采样得到下一个词的预测结果。
在实际使用中,通常专家模型是较小的模型(例如,LLaMA-7B),而代理模型则是更大的模型(例如,LLaMA-13B或LLaMA-70B)。通过代理微调,我们将较小模型中学习到的知识,以一种解码时约束的方式迁移到比其大得多的模型中,大幅节省了计算成本。同时,由于仅需要获取模型的输出分布,而不需要原始的模型权重,因此该方法对于黑盒模型同样适用。
本节介绍了三种主要的参数附加方法,分别通过加在输入、加在模型以及加在输出三种方式实现。总的来说,这几类方法都是提升预训练语言模型性能的有效手段,它们各有优势。加在输入的方法通过在输入序列中添加可学习的张量,对模型本身的结构修改较小,有更好的灵活性。加在模型的方法保持了原始预训练模型的参数,在泛化能力上表现更佳。加在输出的方法则能够以更小的代价驱动更大参数量的黑盒模型,带来更实际的应用前景。