1.5_语言模型的评测
1.5 语言模型的评测
得到一个语言模型后,我们需要对其生成能力进行评测,以判断其优劣。评测语言模型生成能力的方法可以分为两类。第一类方法不依赖具体任务,直接通过语言模型的输出来评测模型的生成能力,称之为内在评测(Intrinsic Evaluation)。第二类方法通过某些具体任务,如机器翻译、摘要生成等,来评测语言模型处理这些具体生成任务的能力,称之为外在评测(Extrinsic Evaluation)。
1.5.1 内在评测
在内在评测中,测试文本通常由与预训练中所用的文本独立同分布的文本构成,不依赖于具体任务。最为常用的内部评测指标是困惑度(Perplexity)[10]。其度量了语言模型对测试文本感到“困惑”的程度。设测试文本为 。语言模型在测试文本 上的困惑度 可由下式计算:
由上式可以看出,如果语言模型对测试文本越“肯定”(即生成测试文本的概率越高),则困惑度的值越小。而语言模型对测试文本越“不确定”(即生成测试文本的概率越低),则困惑度的值越大。由于测试文本和预训练文本同分布,预训练文本代表了我们想要让语言模型学会生成的文本,如果语言模型在这些测试文本上越不“困惑”,则说明语言模型越符合我们对其训练的初衷。因此,困惑度可以一定程度上衡量语言模型的生成能力。
对困惑度进行改写,其可以改写成如下等价形式。
其中, 可以看作是生成模型生成的词分布与测试样本真实
的词分布间的交叉熵,即 ,其中 为语言模型所采用的词典。因为 ,所以此交叉熵是生成模型生成的词分布的信息熵的上界,即
因此,困惑度减小也意味着熵减,意味着模型“胡言乱语”的可能性降低。
1.5.2 外在评测
在外在评测中,测试文本通常包括该任务上的问题和对应的标准答案,其依赖于具体任务。通过外在评测,我们可以评判语言模型处理特定任务的能力。外在评测方法通常可以分为基于统计指标的评测方法和基于语言模型的评测方法两类。以下对此两类方法中的经典方法进行介绍。
1. 基于统计指标的评测
基于统计指标的方法构造统计指标来评测语言模型的输出与标准答案间的契合程度,并以此作为评测语言模型生成能力的依据。BLEU(BiLingual Evaluation Understudy)和ROUGE(Recall-Oriented Understudy for Gisting Evaluation)是应用最为广泛的两种统计指标。其中,BLEU是精度导向的指标,而ROUGE是召回导向的指标。以下分别对这两个指标展开介绍。
BLEU 被提出用于评价模型在机器翻译 (Machine Translation, MT) 任务上的效果 [6]。其在词级别上计算生成的翻译与参考翻译间的重合程度。具体地, BLEU 计算多层次 n-gram 精度的几何平均。设生成的翻译文本的集合为 ,对应的参考翻译集合为 ,其中, 与 一一对应,且 。原始的 n-gram 精度的定义如下:
其中, 代表 n-gram。上式的分子计算了生成的翻译与参考翻译的重合的 n-gram 的个数,分母计算了生成的翻译中包含的 n-gram 的总数。例如,MT 模型将“大语言模型”翻译成英文,生成的翻译为“big language models”,而参考文本为“large language models”。当 时, 。当 时, 。
基于 n-gram 精度,BLEU 取 N 个 n-gram 精度的几何平均作为评测结果:
例如,当 时,BLEU是unigram精度,bigram精度,trigram精度的几何平均。在以上原始BLEU的基础上,我们还可以通过对不同的n-gram精度进行加权或对不同的文本长度设置惩罚项来对BLEU进行调整,从而得到更为贴近人类评测的结果。
ROUGE被提出用于评价模型在摘要生成(Summarization)任务上的效果[13]。常用的ROUGE评测包含ROUGE-N, ROUGE-L, ROUGE-W, 和ROUGE-S四种。其中,ROUGE-N是基于n-gram的召回指标,ROUGE-L是基于最长公共子序列(Longest Common Subsequence,LCS)的召回指标。ROUGE-W是在ROUGE-L的基础上,引入对LCS的加权操作后的召回指标。ROUGE-S是基于Skip-bigram的召回指标。下面给出ROUGE-N, ROUGE-L的定义。ROUGE-W和ROUGE-S的具体计算方法可在[13]中找到。
ROUGE-N 的定义如下:
ROUGE-L 的定义如下:
其中,
是模型生成的摘要 与参考摘要 间的最大公共子序列的长度, 。
基于统计指标的评测方法通过对语言模型生成的答案和标准答案间的重叠程度进行评分。这样的评分无法完全适应生成任务中表达的多样性,与人类的评测相差甚远,尤其是在生成的样本具有较强的创造性和多样性的时候。为解决此问题,可以在评测中引入一个其他语言模型作为“裁判”,利用此“裁判”在预训练阶段掌握的能力对生成的文本进行评测。下面对这种引入“裁判”语言模型的评测方法进行介绍。
2. 基于语言模型的评测
目前基于语言模型的评测方法主要分为两类:(1)基于上下文词嵌入(Contextual Embeddings)的评测方法;(2)基于生成模型的评测方法。典型的基于上下文词嵌入的评测方法是BERTScore[24]。典型的基于生成模型的评测方法是G-EVAL[14]。与BERTScore相比,G-EVAL无需人类标注的参考答案。这使其可以更好的适应到缺乏人类标注的任务中。
BERTScore在BERT的上下文词嵌入向量的基础上,计算生成文本 和参考文本 间的相似度来对生成样本进行评测。BERT将在第二章给出详细介绍。设生成文本包含 个词,即 。设参考文本包含 个词,即 。利用BERT分别得到 和 中每个词的上下文词嵌入向量,即 , 。利用生成文本和参考文本的词嵌入向量集合 和 便可计算BERTScore。BERTScore
从精度(Precision),召回(Recall)和F1量度三个方面对生成文档进行评测。其定义分别如下:
相较于统计评测指标,BERTScore更接近人类评测结果。但是,BERTScore依赖于人类给出的参考文本。这使其无法应用于缺乏人类标注样本的场景中。得益于生成式大语言模型的发展,G-EVAL利用GPT-4在没有参考文本的情况下对生成文本进行评分。G-EVAL通过提示工程(Prompt Engineering)引导GPT-4输出评测分数。Prompt Engineering将在本书第三章进行详细讲解。
如下图所示,G-EVAL的Prompt分为三部分:(1)任务描述与评分标准;(2)评测步骤;(3)输入文本与生成的文本。在第一部分中,任务描述指明需要的评测的任务式什么(如摘要生成),评分标准给出评分需要的范围,评分需要考虑的因素等内容。第二部分的评测步骤是在第一部分内容的基础上由GPT-4自己生成的思维链(Chain-of-Thoughts, CoT)。本书的第三章将对思维链进行详细讲解。第三部分的输入文本与生成的文本是源文本和待评测模型生成的文本。例如摘要生成任务中的输入文本是原文,而生成的文本就是生成摘要。将上述三部分组合在一个prompt里面然后输入给GPT-4,GPT-4便可给出对应的评分。直接将GPT-4给出的得分作为评分会出现区分度不够的问题,因此,G-EVAL还引入了对所有可能得分进行加权平均的机制来进行改进[14]。
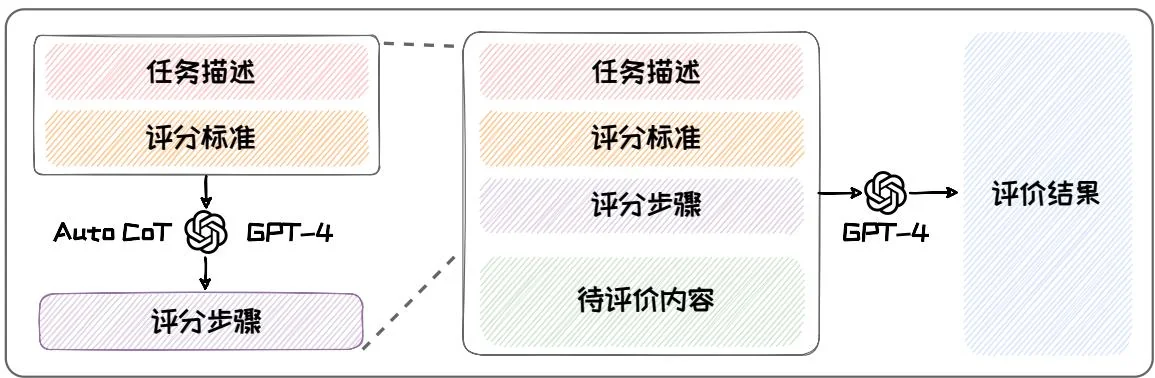
图1.10: G-EVAL评测流程。
除G-EVAL外,近期还有多种基于生成模型的评测方法被提出[12]。其中典型的有InstructScore[23],其除了给出数值的评分,还可以给出对该得分的解释。基于生成模型的评测方法相较于基于统计指标的方法和基于上下文词嵌入的评测方法而言,在准确性、灵活性、可解释性等方面都具有独到的优势。可以预见,未来基于生成模型的评测方法将得到更为广泛的关注和应用。
参考文献
[1] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer Normalization. 2016. arXiv: 1607.06450.
[2] Samy Bengio et al. “Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks”. In: NeurIPS. 2015.
[3] Tom B. Brown et al. "Language Models are Few-Shot Learners". In: NeurIPS. 2020.
[4] Junyoung Chung et al. Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling. 2014. arXiv: 1412.3555.
[5] Jacob Devlin et al. “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”. In: NAACL-HLT. 2019.
[6] Markus Freitag, David Grangier, and Isaac Caswell. "BLEU might be Guilty but References are not Innocent". In: EMNLP. 2020.
[7] Mor Geva et al. “Transformer Feed-Forward Layers Are Key-Value Memories”. In: EMNLP. 2021.
[8] Sepp Hochreiter and Jürgen Schmidhuber. “Long Short-Term Memory”. In: Neural Computing 9.8 (1997), pp. 1735–1780.
[9] Ari Holtzman et al. “The Curious Case of Neural Text Degeneration”. In: ICLR. 2020.
[10] F. Jelinek et al. “Perplexity—a measure of the difficulty of speech recognition tasks”. In: The Journal of the Acoustical Society of America 62 (1997), S63–S63.
[11] Dan Jurafsky and James H. Martin. Speech and language processing: an introduction to natural language processing, computational linguistics, and speech recognition, 2nd Edition. Prentice Hall series in artificial intelligence. Prentice Hall, Pearson Education International, 2009. ISBN: 9780135041963.
[12] Zhen Li et al. Leveraging Large Language Models for NLG Evaluation: Advances and Challenges. 2024. arXiv: 2401.07103.
[13] Chin-Yew Lin. “Rouge: A package for automatic evaluation of summaries”. In: ACL. 2004.
[14] Yang Liu et al. "Gpteval: Nlg evaluation using gpt-4 with better human alignment". In: EMNLP. 2023.
[15] Christopher D. Manning and Hinrich Schütze. Foundations of statistical natural language processing. MIT Press, 2001. ISBN: 978-0-262-13360-9.
[16] OpenAI. GPT-4 Technical Report. 2024. arXiv: 2303.08774.
[17] Razvan Pascanu, Tomás Mikolov, and Yoshua Bengio. “On the difficulty of training recurrent neural networks”. In: ICML. 2013.
[18] Colin Raffel et al. “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer”. In: Journal of Machine Learning Research 21 (2020), 140:1–140:67.
[19] Ashwin K. Vijayakumar et al. “Diverse Beam Search: Decoding Diverse Solutions from Neural Sequence Models”. In: AAAI. 2018.
[20] Joseph Weizenbaum. "ELIZA - a computer program for the study of natural language communication between man and machine". In: Communications Of The ACM 9.1 (1966), pp. 36-45.
[21] Ronald J. Williams and David Zipser. “A Learning Algorithm for Continually Running Fully Recurrent Neural Networks”. In: Neural Computing 1.2 (1989), pp. 270–280.
[22] Shufang Xie et al. Residual: Transformer with Dual Residual Connections. 2023. arXiv: 2304.14802.
[23] Wenda Xu et al. “INSTRUCTSCORE: Towards Explainable Text Generation Evaluation with Automatic Feedback”. In: EMNLP. 2023.
[24] Tianyi Zhang et al. “BERTScore: Evaluating Text Generation with BERT”. In: ICLR. 2020.

2 大语言模型架构
随着数据资源和计算能力的爆发式增长,语言模型的参数规模和性能表现实现了质的飞跃,迈入了大语言模型(Large Language Model, LLM)的新时代。凭借着庞大的参数量和丰富的训练数据,大语言模型不仅展现出了强大的泛化能力,还催生了新智能的涌现,勇立生成式人工智能(Artificial Intelligence Generated Content, AIGC)的浪潮之巅。当前,大语言模型技术蓬勃发展,各类模型层出不穷。这些模型在广泛的应用场景中已经展现出与人类比肩甚至超过人类的能力,引领着由AIGC驱动的新一轮产业革命。本章将深入探讨大语言模型的相关背景知识,并分别介绍Encoder-only、Encoder-Decoder以及Decoder-only三种主流模型架构。通过列举每种架构的代表性模型,深入分析它们在网络结构、训练方法等方面的主要创新之处。最后,本章还将简单介绍一些非Transformer架构的模型,以展现当前大语言模型研究百花齐放的发展现状。