7.2_TD_learning_of_action_values_Sarsa
7.2 TD learning of action values: Sarsa
The TD algorithm introduced in Section 7.1 can only estimate state values. This section introduces another TD algorithm called Sarsa that can directly estimate action values. Estimating action values is important because it can be combined with a policy improvement step to learn optimal policies.
7.2.1 Algorithm description
Given a policy , our goal is to estimate the action values. Suppose that we have some experience samples generated following : . We can use the following Sarsa algorithm to estimate the action values:
where and is the learning rate. Here, is the estimate of . At time , only the q-value of is updated, whereas the q-values of the others remain the same.
Some important properties of the Sarsa algorithm are discussed as follows.
Why is this algorithm called "Sarsa"? That is because each iteration of the algorithm requires . Sarsa is an abbreviation for state-action-reward-state-action. The Sarsa algorithm was first proposed in [35] and its name was coined by [3].
Why is Sarsa designed in this way? One may have noticed that Sarsa is similar to the TD algorithm in (7.1). In fact, Sarsa can be easily obtained from the TD algorithm by replacing state value estimation with action value estimation.
What does Sarsa do mathematically? Similar to the TD algorithm in (7.1), Sarsa is a stochastic approximation algorithm for solving the Bellman equation of a given policy:
Equation (7.13) is the Bellman equation expressed in terms of action values. A proof is given in Box 7.3.
Box 7.3: Showing that (7.13) is the Bellman equation
As introduced in Section 2.8.2, the Bellman equation expressed in terms of action values is
This equation establishes the relationships among the action values. Since
(7.14) can be rewritten as
By the definition of the expected value, the above equation is equivalent to (7.13). Hence, (7.13) is the Bellman equation.
Is Sarsa convergent? Since Sarsa is the action-value version of the TD algorithm in (7.1), the convergence result is similar to Theorem 7.1 and given below.
Theorem 7.2 (Convergence of Sarsa). Given a policy , by the Sarsa algorithm in (7.12), converges almost surely to the action value as for all if and for all .
The proof is similar to that of Theorem 7.1 and is omitted here. The condition of and should be valid for all . In particular, requires that every state-action pair must be visited an infinite (or sufficiently many) number of times. At time , if , then ; otherwise, .
7.2.2 Optimal policy learning via Sarsa
The Sarsa algorithm in (7.12) can only estimate the action values of a given policy. To find optimal policies, we can combine it with a policy improvement step. The combination is also often called Sarsa, and its implementation procedure is given in Algorithm 7.1.
Algorithm 7.1: Optimal policy learning by Sarsa
Initialization: for all and all . . Initial for all . Initial -greedy policy derived from .
Goal: Learn an optimal policy that can lead the agent to the target state from an initial state .
For each episode, do
Generate at following
If ( ) is not the target state, do
Collect an experience sample given : generate by interacting with the environment; generate following .
Update -value for :
Update policy for :
As shown in Algorithm 7.1, each iteration has two steps. The first step is to update the q-value of the visited state-action pair. The second step is to update the policy to an -greedy one. The q-value update step only updates the single state-action pair visited at time . Afterward, the policy of is immediately updated. Therefore, we do not evaluate a given policy sufficiently well before updating the policy. This is based on the idea of generalized policy iteration. Moreover, after the policy is updated, the policy is immediately used to generate the next experience sample. The policy here is -greedy so that it is exploratory.
A simulation example is shown in Figure 7.2 to demonstrate the Sarsa algorithm. Unlike all the tasks we have seen in this book, the task here aims to find an optimal path from a specific starting state to a target state. It does not aim to find the optimal policies for all states. This task is often encountered in practice where the starting state (e.g., home) and the target state (e.g., workplace) are fixed, and we only need to find an optimal path connecting them. This task is relatively simple because we only need to explore the states that are close to the path and do not need to explore all the states. However, if we do not explore all the states, the final path may be locally optimal rather than globally optimal.
The simulation setup and simulation results are discussed below.
Simulation setup: In this example, all the episodes start from the top-left state and terminate at the target state. The reward settings are , , and . Moreover, for all and . The initial guesses of the action values are for all . The initial policy has a

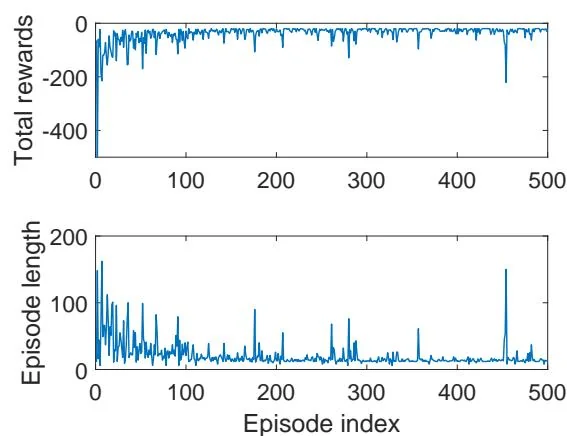
Figure 7.2: An example for demonstrating Sarsa. All the episodes start from the top-left state and terminate when reaching the target state (the blue cell). The goal is to find an optimal path from the starting state to the target state. The reward settings are , , and . The learning rate is and the value of is 0.1. The left figure shows the final policy obtained by the algorithm. The right figures show the total reward and length of every episode.
uniform distribution: for all .
Learned policy: The left figure in Figure 7.2 shows the final policy learned by Sarsa. As can be seen, this policy can successfully lead to the target state from the starting state. However, the policies of some other states may not be optimal. That is because the other states are not well explored.
Total reward of each episode: The top-right subfigure in Figure 7.2 shows the total reward of each episode. Here, the total reward is the non-discounted sum of all immediate rewards. As can be seen, the total reward of each episode increases gradually. That is because the initial policy is not good and hence negative rewards are frequently obtained. As the policy becomes better, the total reward increases.
Length of each episode: The bottom-right subfigure in Figure 7.2 shows that the length of each episode drops gradually. That is because the initial policy is not good and may take many detours before reaching the target. As the policy becomes better, the length of the trajectory becomes shorter. Notably, the length of an episode may increase abruptly (e.g., the 460th episode) and the corresponding total reward also drops sharply. That is because the policy is -greedy, and there is a chance for it to take non-optimal actions. One way to resolve this problem is to use decaying whose value converges to zero gradually.
Finally, Sarsa also has some variants such as Expected Sarsa. Interested readers may check Box 7.4.
Box 7.4: Expected Sarna
Given a policy , its action values can be evaluated by Expected Sarsa, which is a variant of Sarsa. The Expected Sarsa algorithm is
where
is the expected value of under policy . The expression of the Expected Sarsa algorithm is very similar to that of Sarsa. They are different only in terms of their TD targets. In particular, the TD target in Expected Sarsa is , while that of Sarsa is . Since the algorithm involves an expected value, it is called Expected Sarsa. Although calculating the expected value may increase the computational complexity slightly, it is beneficial in the sense that it reduces the estimation variances because it reduces the random variables in Sarsa from to .
Similar to the TD learning algorithm in (7.1), Expected Sarsa can be viewed as a stochastic approximation algorithm for solving the following equation:
The above equation may look strange at first glance. In fact, it is another expression of the Bellman equation. To see that, substituting
into (7.15) gives
which is clearly the Bellman equation.
The implementation of Expected Sarsa is similar to that of Sarsa. More details can be found in [3, 36, 37].