1.4_Policy
1.4 Policy
A policy tells the agent which actions to take at every state. Intuitively, policies can be depicted as arrows (see Figure 1.4(a)). Following a policy, the agent can generate a trajectory starting from an initial state (see Figure 1.4(b)).
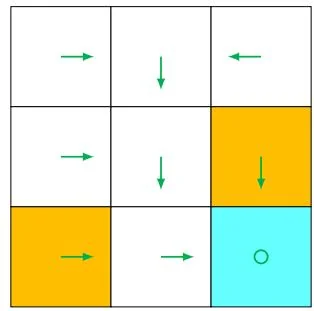
(a) A deterministic policy
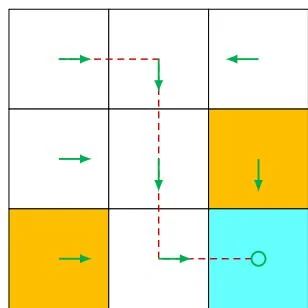
(b) Trajectories obtained from the policy
Figure 1.4: A policy represented by arrows and some trajectories obtained by starting from different initial states.
Mathematically, policies can be described by conditional probabilities. Denote the policy in Figure 1.4 as , which is a conditional probability distribution function defined for every state. For example, the policy for is
which indicates that the probability of taking action in state is one, and the probabilities of taking other actions are zero.
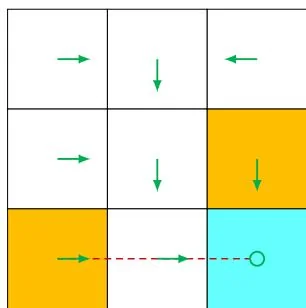
The above policy is deterministic. Policies may be stochastic in general. For example, the policy shown in Figure 1.5 is stochastic: in state , the agent may take actions to go either rightward or downward. The probabilities of taking these two actions are the
same (both are 0.5). In this case, the policy for is

Figure 1.5: A stochastic policy. In state , the agent may move rightward or downward with equal probabilities of 0.5.
Policies represented by conditional probabilities can be stored as tables. For example, Table 1.2 represents the stochastic policy depicted in Figure 1.5. The entry in the th row and th column is the probability of taking the th action at the th state. Such a representation is called a tabular representation. We will introduce another way to represent policies as parameterized functions in Chapter 8.
Table 1.2: A tabular representation of a policy. Each entry indicates the probability of taking an action at a state.