This section introduces the value iteration algorithm. It is exactly the algorithm suggested by the contraction mapping theorem for solving the Bellman optimality equation, as introduced in the last chapter (Theorem 3.3). In particular, the algorithm is
vk+1=π∈Πmax(rπ+γPπvk),k=0,1,2,…
It is guaranteed by Theorem 3.3 that vk and πk converge to the optimal state value and an optimal policy as k→∞ , respectively.
This algorithm is iterative and has two steps in every iteration.
The first step in every iteration is a policy update step. Mathematically, it aims to find a policy that can solve the following optimization problem:
πk+1=argπmax(rπ+γPπvk),
where vk is obtained in the previous iteration.
The second step is called a value update step. Mathematically, it calculates a new value vk+1 by
vk+1=rπk+1+γPπk+1vk,(4.1)
where vk+1 will be used in the next iteration.
The value iteration algorithm introduced above is in a matrix-vector form. To implement this algorithm, we need to further examine its elementwise form. While the matrix-vector form is useful for understanding the core idea of the algorithm, the elementwise form is necessary for explaining the implementation details.
4.1.1 Elementwise form and implementation
Consider the time step k and a state s .
⋄ First, the elementwise form of the policy update step πk+1=argmaxπ(rπ+γPπvk) is
We showed in Section 3.3.1 that the optimal policy that can solve the above optimization problem is
πk+1(a∣s)={1,0,a=ak∗(s),a=ak∗(s),(4.2)
where ak∗(s)=argmaxaqk(s,a) . If ak∗(s)=argmaxaqk(s,a) has multiple solutions, we can select any of them without affecting the convergence of the algorithm. Since the new policy πk+1 selects the action with the greatest qk(s,a) , such a policy is called greedy.
Second, the elementwise form of the value update step vk+1=rπk+1+γPπk+1vk is
The implementation details are summarized in Algorithm 4.1.
One problem that may be confusing is whether vk in (4.1) is a state value. The answer is no. Although vk eventually converges to the optimal state value, it is not ensured to satisfy the Bellman equation of any policy. For example, it does not satisfy vk=rπk+1+γPπk+1vk or vk=rπk+γPπkvk in general. It is merely an intermediate value generated by the algorithm. In addition, since vk is not a state value, qk is not an action value.
4.1.2 Illustrative examples
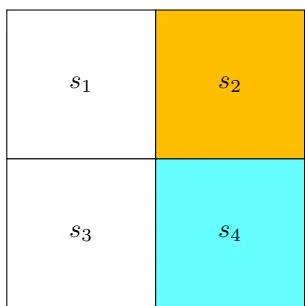
We next present an example to illustrate the step-by-step implementation of the value iteration algorithm. This example is a two-by-two grid with one forbidden area (Fig-
Algorithm 4.1: Value iteration algorithm
Initialization: The probability models p(r∣s,a) and p(s′∣s,a) for all (s,a) are known. Initial guess v0 .
Goal: Search for the optimal state value and an optimal policy for solving the Bellman optimality equation.
While vk has not converged in the sense that ∥vk−vk−1∥ is greater than a predefined small threshold, for the k th iteration, do
For every state s∈S , do
For every action a∈A(s) , do
q−v a l u e:qk(s,a)=r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vk(s′)
Maximum action value: ak∗(s)=argmaxaqk(s,a)
Policy update: πk+1(a∣s)=1 if a=ak∗ , and πk+1(a∣s)=0 otherwise.
Value update: vk+1(s)=maxaqk(s,a)
Table 4.1: The expression of q(s,a) for the example as shown in Figure 4.2.
ure 4.2). The target area is s4 . The reward settings are rboundary=rforbidden=−1 and rtarget=1 . The discount rate is γ=0.9 .
Figure 4.2: An example for demonstrating the implementation of the value iteration algorithm.
The expression of the q-value for each state-action pair is shown in Table 4.1.
⋄k=0:
Without loss of generality, select the initial values as v0(s1)=v0(s2)=v0(s3)=v0(s4)=0 .
q-value calculation: Substituting v0(si) into Table 4.1 gives the q-values shown in Table 4.2.
Table 4.2: The value of q(s,a) at k=0 .
Table 4.3: The value of q(s,a) at k=1 .
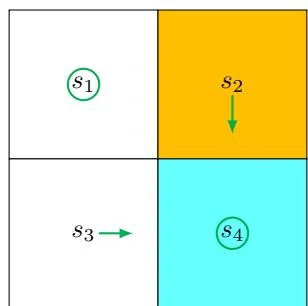
Policy update: π1 is obtained by selecting the actions with the greatest q-values for every state:
This policy is visualized in Figure 4.2 (the middle subfigure). It is clear that this policy is not optimal because it selects to stay still at s1 . Notably, the q-values for (s1,a5) and (s1,a3) are actually the same, and we can randomly select either action.
Value update: v1 is obtained by updating the v-value to the greatest q-value for each state:
v1(s1)=0,v1(s2)=1,v1(s3)=1,v1(s4)=1.
k=1
q-value calculation: Substituting v1(si) into Table 4.1 yields the q-values shown in Table 4.3.
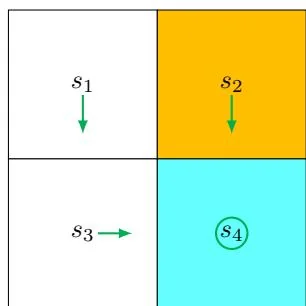
Policy update: π2 is obtained by selecting the greatest q-values:
It is notable that policy π2 , as illustrated in Figure 4.2, is already optimal. Therefore, we
4.2. Policy iteration
only need to run two iterations to obtain an optimal policy in this simple example. For more complex examples, we need to run more iterations until the value of vk converges (e.g., until ∥vk+1−vk∥ is smaller than a pre-specified threshold).