4.5_Q&A
4.5 Q&A
Q: Is the value iteration algorithm guaranteed to find optimal policies?
A: Yes. This is because value iteration is exactly the algorithm suggested by the contraction mapping theorem for solving the Bellman optimality equation in the last chapter. The convergence of this algorithm is guaranteed by the contraction mapping theorem.
Q: Are the intermediate values generated by the value iteration algorithm state values?
A: No. These values are not guaranteed to satisfy the Bellman equation of any policy.
Q: What steps are included in the policy iteration algorithm?
A: Each iteration of the policy iteration algorithm contains two steps: policy evaluation and policy improvement. In the policy evaluation step, the algorithm aims to solve the Bellman equation to obtain the state value of the current policy. In the
policy improvement step, the algorithm aims to update the policy so that the newly generated policy has greater state values.
Q: Is another iterative algorithm embedded in the policy iteration algorithm?
A: Yes. In the policy evaluation step of the policy iteration algorithm, an iterative algorithm is required to solve the Bellman equation of the current policy.
Q: Are the intermediate values generated by the policy iteration algorithm state values?
A: Yes. This is because these values are the solutions of the Bellman equation of the current policy.
Q: Is the policy iteration algorithm guaranteed to find optimal policies?
A: Yes. We have presented a rigorous proof of its convergence in this chapter.
Q: What is the relationship between the truncated policy iteration and policy iteration algorithms?
A: As its name suggests, the truncated policy iteration algorithm can be obtained from the policy iteration algorithm by simply executing a finite number of iterations during the policy evaluation step.
Q: What is the relationship between truncated policy iteration and value iteration?
A: Value iteration can be viewed as an extreme case of truncated policy iteration, where a single iteration is run during the policy evaluation step.
Q: Are the intermediate values generated by the truncated policy iteration algorithm state values?
A: No. Only if we run an infinite number of iterations in the policy evaluation step, can we obtain true state values. If we run a finite number of iterations, we can only obtain approximates of the true state values.
Q: How many iterations should we run in the policy evaluation step of the truncated policy iteration algorithm?
A: The general guideline is to run a few iterations but not too many. The use of a few iterations in the policy evaluation step can speed up the overall convergence rate, but running too many iterations would not significantly speed up the convergence rate.
Q: What is generalized policy iteration?
A: Generalized policy iteration is not a specific algorithm. Instead, it refers to the general idea of the interaction between value and policy updates. This idea is rooted in the policy iteration algorithm. Most of the reinforcement learning algorithms introduced in this book fall into the scope of generalized policy iteration.
Q: What are model-based and model-free reinforcement learning?
A: Although the algorithms introduced in this chapter can find optimal policies, they are usually called dynamic programming algorithms rather than reinforcement learning algorithms because they require the system model. Reinforcement learning algorithms can be classified into two categories: model-based and model-free. Here, "model-based" does not refer to the requirement of the system model. Instead, model-based reinforcement learning uses data to estimate the system model and uses this model during the learning process. By contrast, model-free reinforcement learning does not involve model estimation during the learning process. More information about model-based reinforcement learning can be found in [13-16].
Chapter 5
Monte Carlo Methods
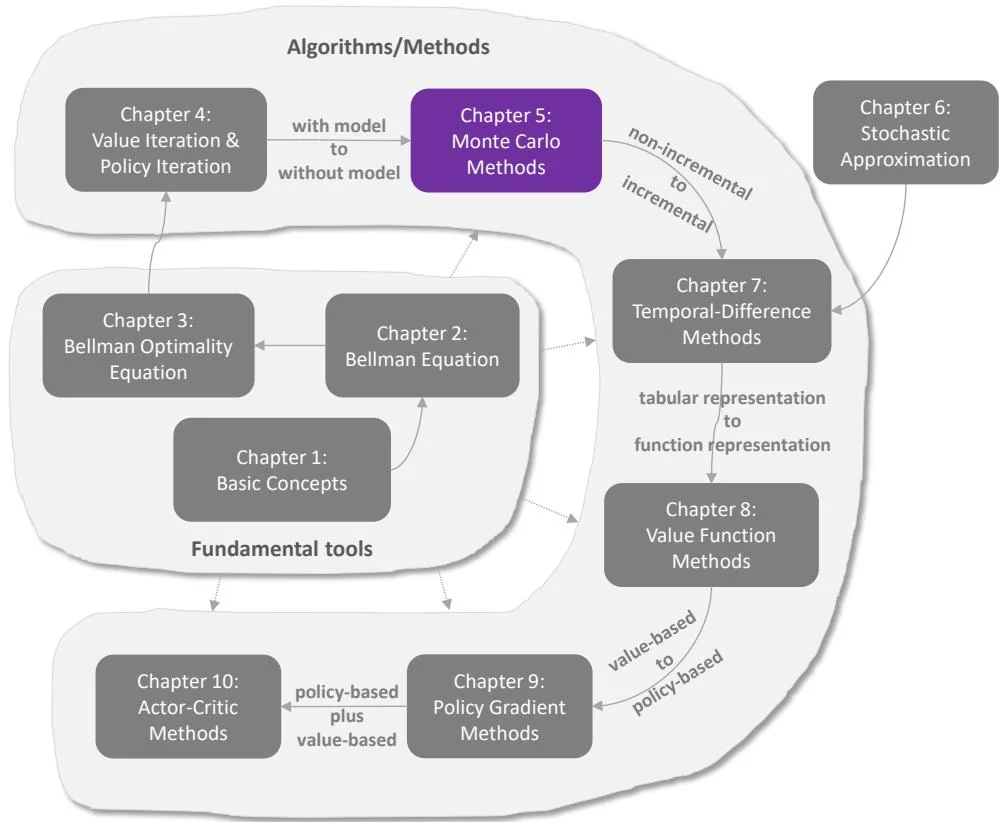
Figure 5.1: Where we are in this book.
In the previous chapter, we introduced algorithms that can find optimal policies based on the system model. In this chapter, we start introducing model-free reinforcement learning algorithms that do not presume system models.
While this is the first time we introduce model-free algorithms in this book, we must fill a knowledge gap: how can we find optimal policies without models? The philosophy is simple: If we do not have a model, we must have some data. If we do not have data, we must have a model. If we have neither, then we are not able to find optimal policies. The "data" in reinforcement learning usually refers to the agent's interaction experiences with the environment.
To demonstrate how to learn from data rather than a model, we start this chapter by introducing the mean estimation problem, where the expected value of a random variable is estimated from some samples. Understanding this problem is crucial for understanding the fundamental idea of learning from data.
Then, we introduce three algorithms based on Monte Carlo (MC) methods. These algorithms can learn optimal policies from experience samples. The first and simplest algorithm is called MC Basic, which can be readily obtained by modifying the policy iteration algorithm introduced in the last chapter. Understanding this algorithm is important for grasping the fundamental idea of MC-based reinforcement learning. By extending this algorithm, we further introduce another two algorithms that are more complicated but more efficient.