2.1_Motivating_example_1_Why_are_returns_important
2.1 Motivating example 1: Why are returns important?
The previous chapter introduced the concept of returns. In fact, returns play a fundamental role in reinforcement learning since they can evaluate whether a policy is good or not. This is demonstrated by the following examples.
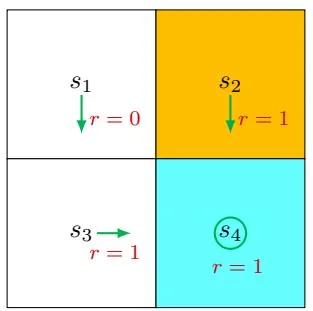
Figure 2.2: Examples for demonstrating the importance of returns. The three examples have different policies for .
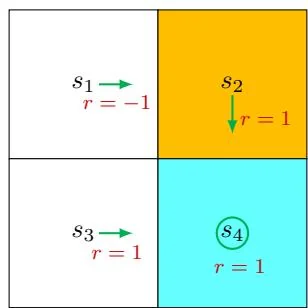
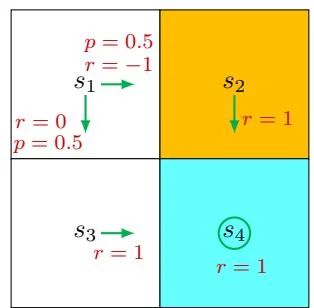
Consider the three policies shown in Figure 2.2. It can be seen that the three policies are different at . Which is the best and which is the worst? Intuitively, the leftmost policy is the best because the agent starting from can avoid the forbidden area. The middle policy is intuitively worse because the agent starting from moves to the forbidden area. The rightmost policy is in between the others because it has a probability of 0.5 to go to the forbidden area.
While the above analysis is based on intuition, a question that immediately follows is whether we can use mathematics to describe such intuition. The answer is yes and relies on the return concept. In particular, suppose that the agent starts from .
Following the first policy, the trajectory is . The corresponding discounted return is
where is the discount rate.
Following the second policy, the trajectory is . The discounted
return is
Following the third policy, two trajectories can possibly be obtained. One is , and the other is . The probability of either of the two trajectories is 0.5. Then, the average return that can be obtained starting from is
By comparing the returns of the three policies, we notice that
for any value of . Inequality (2.1) suggests that the first policy is the best because its return is the greatest, and the second policy is the worst because its return is the smallest. This mathematical conclusion is consistent with the aforementioned intuition: the first policy is the best since it can avoid entering the forbidden area, and the second policy is the worst because it leads to the forbidden area.
The above examples demonstrate that returns can be used to evaluate policies: a policy is better if the return obtained by following that policy is greater. Finally, it is notable that does not strictly comply with the definition of returns because it is more like an expected value. It will become clear later that is actually a state value.