2.5 Examples for illustrating the Bellman equation
We next use two examples to demonstrate how to write out the Bellman equation and calculate the state values step by step. Readers are advised to carefully go through the examples to gain a better understanding of the Bellman equation.
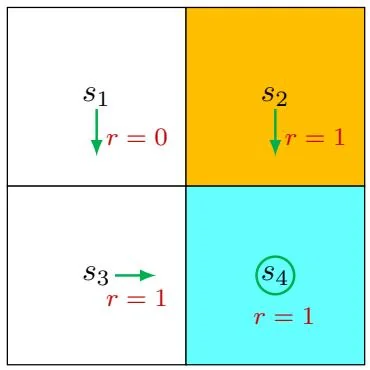
Figure 2.4: An example for demonstrating the Bellman equation. The policy in this example is deterministic.
⋄ Consider the first example shown in Figure 2.4, where the policy is deterministic. We next write out the Bellman equation and then solve the state values from it.
First, consider state s1 . Under the policy, the probabilities of taking the actions are π(a=a3∣s1)=1 and π(a=a3∣s1)=0 . The state transition probabilities are p(s′=s3∣s1,a3)=1 and p(s′=s3∣s1,a3)=0 . The reward probabilities are p(r=0∣s1,a3)=1 and p(r=0∣s1,a3)=0 . Substituting these values into (2.7) gives
vπ(s1)=0+γvπ(s3). Interestingly, although the expression of the Bellman equation in (2.7) seems complex, the expression for this specific state is very simple.
Similarly, it can be obtained that
vπ(s2)=1+γvπ(s4), vπ(s3)=1+γvπ(s4), vπ(s4)=1+γvπ(s4). We can solve the state values from these equations. Since the equations are simple, we can manually solve them. More complicated equations can be solved by the algorithms presented in Section 2.7. Here, the state values can be solved as
vπ(s4)=1−γ1, vπ(s3)=1−γ1, vπ(s2)=1−γ1, vπ(s1)=1−γγ. Furthermore, if we set γ=0.9 , then
vπ(s4)=1−0.91=10, vπ(s3)=1−0.91=10, vπ(s2)=1−0.91=10, vπ(s1)=1−0.90.9=9. 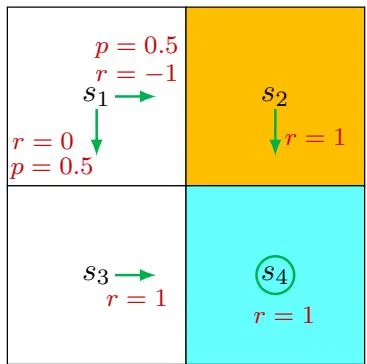
Figure 2.5: An example for demonstrating the Bellman equation. The policy in this example is stochastic.
⋄ Consider the second example shown in Figure 2.5, where the policy is stochastic. We next write out the Bellman equation and then solve the state values from it.
In state s1 , the probabilities of going right and down equal 0.5. Mathematically, we have π(a=a2∣s1)=0.5 and π(a=a3∣s1)=0.5 . The state transition probability is deterministic since p(s′=s3∣s1,a3)=1 and p(s′=s2∣s1,a2)=1 . The reward probability is also deterministic since p(r=0∣s1,a3)=1 and p(r=−1∣s1,a2)=1 . Substituting these values into (2.7) gives
vπ(s1)=0.5[0+γvπ(s3)]+0.5[−1+γvπ(s2)]. Similarly, it can be obtained that
vπ(s2)=1+γvπ(s4), vπ(s3)=1+γvπ(s4), vπ(s4)=1+γvπ(s4). The state values can be solved from the above equations. Since the equations are
simple, we can solve the state values manually and obtain
vπ(s4)=1−γ1, vπ(s3)=1−γ1, vπ(s2)=1−γ1, vπ(s1)=0.5[0+γvπ(s3)]+0.5[−1+γvπ(s2)],=−0.5+1−γγ. Furthermore, if we set γ=0.9 , then
vπ(s4)=10, vπ(s3)=10, vπ(s2)=10, vπ(s1)=−0.5+9=8.5. If we compare the state values of the two policies in the above examples, it can be seen that
vπ1(si)≥vπ2(si),i=1,2,3,4, which indicates that the policy in Figure 2.4 is better because it has greater state values. This mathematical conclusion is consistent with the intuition that the first policy is better because it can avoid entering the forbidden area when the agent starts from s1 . As a result, the above two examples demonstrate that state values can be used to evaluate policies.