5.1_Motivating_example_Mean_estimation
5.1 Motivating example: Mean estimation
We next introduce the mean estimation problem to demonstrate how to learn from data rather than a model. We will see that mean estimation can be achieved based on Monte Carlo methods, which refer to a broad class of techniques that use stochastic samples to solve estimation problems. The reader may wonder why we care about the mean estimation problem. It is simply because state and action values are both defined as the means of returns. Estimating a state or action value is actually a mean estimation problem.
Consider a random variable that can take values from a finite set of real numbers denoted as . Suppose that our task is to calculate the mean or expected value of : . Two approaches can be used to calculate .
The first approach is model-based. Here, the model refers to the probability distribution of . If the model is known, then the mean can be directly calculated based on the definition of the expected value:
In this book, we use the terms expected value, mean, and average interchangeably.
The second approach is model-free. When the probability distribution (i.e., the model) of is unknown, suppose that we have some samples of . Then, the mean can be approximated as
When is small, this approximation may not be accurate. However, as increases, the approximation becomes increasingly accurate. When , we have .
This is guaranteed by the law of large numbers: the average of a large number of samples is close to the expected value. The law of large numbers is introduced in Box 5.1.
The following example illustrates the two approaches described above. Consider a coin flipping game. Let random variable denote which side is showing when the coin lands. has two possible values: when the head is showing, and when the tail is showing. Suppose that the true probability distribution (i.e., the model) of is
If the probability distribution is known in advance, we can directly calculate the mean as
If the probability distribution is unknown, then we can flip the coin many times and record the sampling results . By calculating the average of the samples, we can obtain an estimate of the mean. As shown in Figure 5.2, the estimated mean becomes increasingly accurate as the number of samples increases.
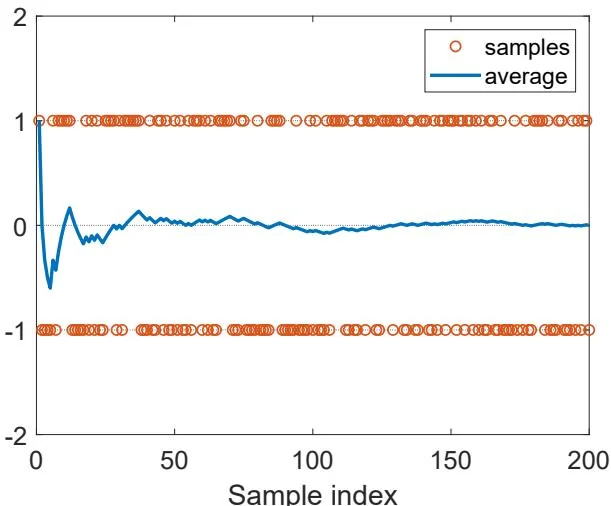
Figure 5.2: An example for demonstrating the law of large numbers. Here, the samples are drawn from following a uniform distribution. The average of the samples gradually converges to zero, which is the true expected value, as the number of samples increases.
It is worth mentioning that the samples used for mean estimation must be independent and identically distributed (i.i.d. or iid). Otherwise, if the sampling values correlate, it may be impossible to correctly estimate the expected value. An extreme case is that all the sampling values are the same as the first one, whatever the first one is. In this case, the average of the samples is always equal to the first sample, no matter how many samples we use.
Box 5.1: Law of large numbers
For a random variable , suppose that are some i.i.d. samples. Let be the average of the samples. Then,
The above two equations indicate that is an unbiased estimate of , and its variance decreases to zero as increases to infinity.
The proof is given below.
First, , where the last equability is due to the fact that the samples are identically distributed (that is, ).
Second, , where the second equality is due to the fact that the samples are independent, and the third equability is a result of the samples being identically distributed (that is, ).