10.2_纹理内存
10.2 纹理内存
在介绍具有固定功能纹理硬件的特性之前,本章将先花一定时间介绍纹理引用将要绑定的底层内存。CUDA可以利用设备内存或CUDA数组存储纹理。
10.2.1 设备内存
在设备内存中,纹理主要按行的形式寻址。图10-1显示了一张 的纹理,其中offset是指从图像的头指针开始计算偏移(以元素为单位计数)。
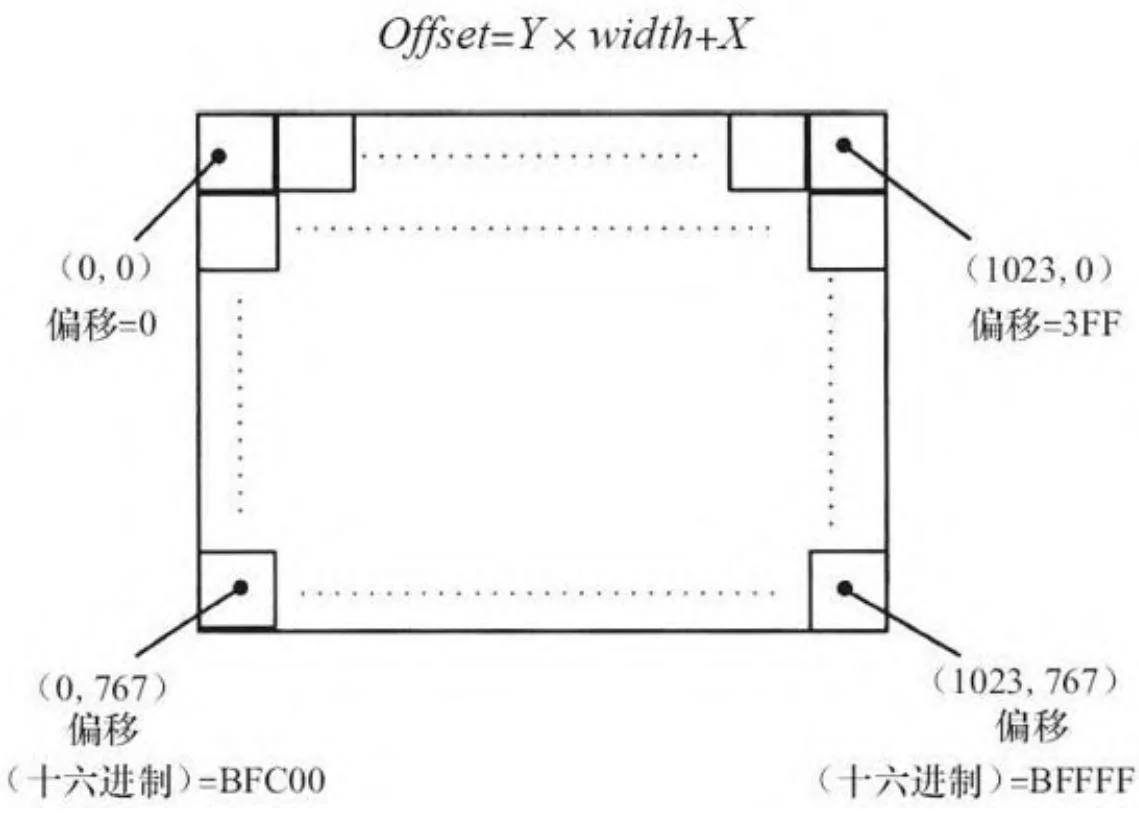
图10-1 的图像
如果要计算字节偏移,则需要乘以每个元素的字节大小。
事实上,这种地址计算只适用于多数特殊的纹理宽度,例如1024,因为1024为2的幂次,符合所有形式的对齐约束限制。为了通用化,不单单只针对特殊的纹理大小,CUDA实现了等步长线性(pitch-linear)的寻址,纹理内存的宽度与纹理的实际宽度并不相同。针对各种非特殊的宽度,硬件将强制使用对齐限制,使得在纹理内存中,每个元素的访问将不再按照实际纹理中每个元素的宽度标准进行。例如一张宽度为950的纹理,如果对齐限制是64字节,则按字节计算的宽度需要填充到960 [1](填满下一个64字节)。此纹理如图10-2所示。
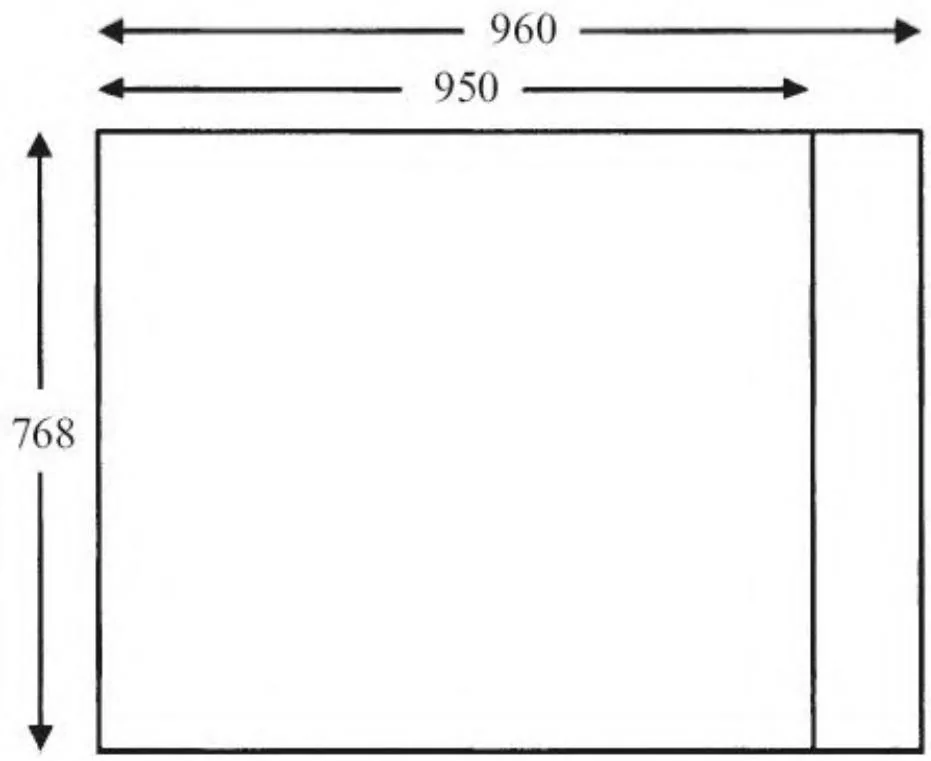
图10-2 的纹理与等步长处理
在CUDA中,通过填充得到的按字节计算的宽度叫做步长(pitch)。设备内存一共将使用 个元素的存储大小。此时,图像的偏移将以字节为单位计算,如下所示。
应用程序可以通过调用CUDAAllocPitch()或cuMemAllocPitch()委托CUDA驱动选择步长的大小[2]。在三维纹理下,Depth个二维切片数据连续分布在设备内存中,因此对应特定Depth的等步长线性图像与二维图像相似。
10.2.2 CUDA数组与块的线性寻址
CUDA数组是专为支持纹理操作而设计的,它的分配与设备内存一样来自物理内存池。CUDA数组的结构对程序员而言是不透明的且不能通过指针访问。只有通过数组句柄以及一组一维、二维或三维坐标访问CUDA数组在内存中的位置。
CUDA数组的寻址计算非常复杂,这样设计主要是为了让连续的地址能很好地显示二维或三维局部性。寻址计算是依赖于具体硬件的,不同代的硬件寻址方式有所不同。图10-1显示了其中的一种机制,在执行地址计算之前,行与列地址的低两位比特呈交错的形式。
由图10-3可以看出,比特交错能够使连续的地址拥有“维度局部性”,即一条缓存线上存储的是相邻的一整块像素值,而不是水平方向的所有像素[3]。然而,这种方式也具有一定缺点,即在使用纹理维度时需要对纹理的维度强加一些条件,很不方便,因此,比特交错只是几种所谓的“块线性”寻址计算策略中的一种。
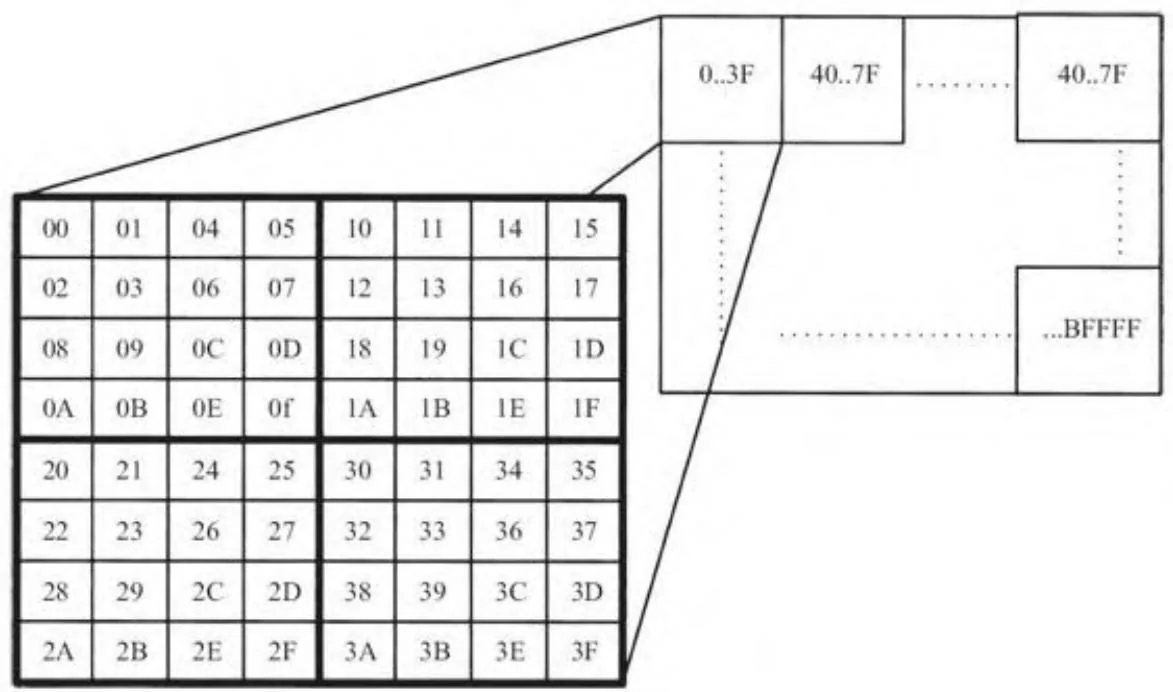
图10-3 图片中的交错比特
在设备内存中,一个图像元素的位置可以用以下几种方式表示:
·基地址指针、步长、以及元组(XInBytes,Y)或元组(XInBytes,Y,Z)。
·基地址指针以及通过公式10-1计算出的偏移。
已包含偏移的设备指针。
相反,当CUDA数组不具备设备内存地址的时候,内存地址必须以CUDA数组以及一个元组(XInBytes, Y)或元组(XInBytes, Y, Z)的形式指定。
1. 创建和销毁CUDA数组
使用CUDA运行时,调用CUDAAllocArray()可以创建CUDA数组。
cudaError_t CUDAAllocArray(struct CUDAArray **array, const struct CUDAChannelFormatDesc *desc, size_t width, size_t height _dv(0), unsigned int flags _dv(0));参数array传递回数组的句柄,desc指定了每个数组元素中成分的数目以及类型(如两个浮点数),width指定了数组采用字节计数的宽度,height是一个可选参数,其指定了数组的高度,如果height没有被指定,CUDAArray()将创建一个一维的CUDA数组。
参数flags用来表示CUDA数组的使用方式。当CUDA数组被指定用作表面读写操作时,该参数必须且只能为“CUDAArraySurfaceLoadStore”。关于表面读写操作,之后的章节将具体介绍。
关于参数height与flags后面使用的宏__dv,根据不同的语言,将发挥不同的作用。当使用C编译器编译时,其只是一个简单的参数,当如果使用C++编译器时,其表示一个具有指定默认值的参数。
结构体CUDAChannelFormatDesc描述了一个纹理的具体内容。
structudaChannelFormatDesc {
int x, y, z, w;
enumudaChannelFormatKind f;
};结构体中的成员x、y、z以及w指定了纹理元素中每个成员的比特数。例如,仅包含一个浮点元素的纹理对应的x为32,其他成员的值为0。结构体CUDAChannelFormatKind指明了该数据的类型,是带符号的整数,还是无符号整型值,或者浮点数。
enumudaChannelFormatKind
{udaChannelFormatKindSigned $\equiv$ 0,udaChannelFormatKindUnsigned $= 1$ ,udaChannelFormatKindFloat $= 2$ ,udaChannelFormatKindNone $= 3$ ;开发人员可以通过调用函数CreateChannelDesc创建CUDAChannelFormatDesc结构体。
cudaChannelFormatDesc CUDACreateChannelDesc(int x, int y, int z, int w, CUDAChannelFormatKind kind);或者,也可以调用此类函数的模板函数,如下所示:
template<class T> CUDACreateChannelDesc<T>();其中T可以是CUDA支持的任何本地格式(native format)。以下是两个使用该模板的例子。
template<> inline__host__udaChannelFormatDesc
cudaCreateChannelDesc<float>(void)
{
int e = (int)sizeof(float) * 8;
returnudaCreateChannelDesc(e, 0, 0, 0,udaChannelFormatKindFloat);
}
template<> inline__host__udaChannelFormatDesc
cudaCreateChannelDesc<uint2>(void)
{
int e = (int)sizeof(unsigned int) * 8;
returnudaCreateChannelDesc(e, e, 0, 0,udaChannelFormatKindUnsigned);
}
提醒 当使用char类型的数据时,部分编译器认定char是有符
号的,而有些编译器则认为char是无符号的。为了避免混淆,最好每次使用前加上signed关键字。
三维CUDA数组可以通过调用CUDAAlloc3DArray()分配。
cudaError_t cudaMalloc3DArray(struct CUDAArray** array, const struct cudaChannelFormatDesc* desc, struct CUDAExtent extent, unsigned int flags __dv(0));CUDAAlloc3DArray()接受一个名为CUDAExtent的结构体,该结构体包含了width、height以及depth三个成员。
structudaExtent {
size_t width;
size_t height;
size_t depth;
};参数flags与CUDA mallocArray()中的相同,当CUDA数组用来进行表面读写操作时,该参数的值必须为“CUDAArraySurfaceLoadStore”。

注意 针对数组的处理方式,CUDA运行时API与驱动程序
API是相互兼容的。通过CUDAMallocArray()传递回的指针可以强制转换成CUarray,然后传递给类似cuArrayGetDescriptor()的驱动程序API。
2. 驱动程序API
与CUDAAllocArray()以及CUDAAlloc3DArray()等价的驱动程序API分别是cuArrayCreate()与cuArray3DCreate()。
CResult cuArrayCreate(CUarray *pHandle, const CUDA_ARRAY Descriptor *pAllocateArray);
CResult cuArray3DCreate(CUarray *pHandle, const CUDA_ARRAY3D Descriptor *pAllocateArray);cuArray3DCreate()可以通过指定height或depth的值为0来相应创建一维或二维CUDA数组。结构体CUDA_ARRAY3D Descriptor的定义如下:
typedef struct CUDA_ARRAY3D Descriptor_st
{ size_t Width; size_t Height; size_t Depth; CUarray_format Format; unsigned int NumChannels; unsigned int Flags; } CUDA_ARRAY3D Descriptor;成员Format与NumChannels共同描述了CUDA数组每个元素的大小:NumChannels的值可以为1、2或4,Format指定了数组元素每个通道的类型,具体如下:
typedef enum CUarray_format_enum{ CU_AD_FORMAT_UNSIGNED_INT8 $= 0\mathrm{x}01$ CU_AD_FORMAT_UNSIGNED_INT16 $= 0\mathrm{x}02$ CU_AD_FORMAT_UNSIGNED_INT32 $= 0\mathrm{x}03$ CU_AD_FORMAT_SIGNED_INT8 $= 0\mathrm{x}08$ CU_AD_FORMAT_SIGNED_INT16 $= 0\mathrm{x}09$ CU_AD_FORMAT_SIGNED_INT32 $= 0\mathrm{x}0a$ CU_AD_FORMAT_HALF $= 0\mathrm{x}10$ CU_AD_FORMAT_FLOAT $= 0\mathrm{x}20$ } CUarray_format;
注意 CUDA_ARRAY3D Descriptor中指定的格式仅仅是
指定CUDA数组中数据个数的一种便捷方式。只要每个元素的字节数相同,绑定到CUDA数组的纹理可以指定不同的格式。例如,可以将一个texture绑定到一个包含4个分量、每个分量一个字节的CUDA数组(每个元素32位)。
有时候,CUDA数组的句柄会传递给一些子程序来查询该数组的维度或格式。cuArray3DDescribe()就提供了该功能。
CResult cuArray3DGetDescriptor(CUDA_ARRAY3D Descriptor\*pArrayDescriptor, CUarray hArray);注意!该函数可以使用一维以及二维数组调用,甚至可以使用那些由cuArrayCreate()创建的数组调用。
10.2.3 设备内存与CUDA数组对比
对于那些稀疏的访存方式,尤其是具有维度局部性的访存方式的应用程序(例如计算机视觉领域的应用),使用CUDA数组明显更加合适。而对于那些正常访存的应用程序,尤其是那些数据复用率几乎为
零,或者应用程序的数据复用可以使用共享内存来处理的情况,设备内存明显是更明智的选择。
而对于类似图像处理的部分应用程序,选择使用设备内存还是使用CUDA数组则显得并不那么一目了然。若其他条件都相同,选择设备内存可能比CUDA数组更适合。以下几条考虑因素可以帮助我们做出恰当的选择。
CUDA 3.2之前,CUDA内核无法对CUDA数组进行写操作,程序员只能通过纹理内置指令(intrinsics)从CUDA数组中读取数据。CUDA 3.2为费米架构的硬件添加了通过“表面读写”内置指令访问二维CUDA数组的能力。
CUDA数组不会消耗任何CUDA地址空间。
·在WDDM驱动程序(Windows Vista及其之后版本系统)上,系统能够自动管理CUDA数组的驻存。根据当前正在执行的CUDA内核是否需要使用CUDA数组,CUDA数组可以从设备内存中换进换出,而且该操作对程序员而言是透明的。相反,WDDM则要求所有设备内存常驻以便于任一内核执行。
· CUDA数组只能驻存在设备内存中,如果GPU具有复制引擎,通过总线传输数据时,数据会在两种表现形式间切换。对于部分程序
而言,在主机内存保持以等步长的表现形式,而在设备内存保持以CUDA数组的表现形式是最好的一种选择。
[1] 这里应为960,为64的整倍数,原文误为964。——译者注
[2] 由于根据文档对齐限制执行的存储分配操作容易产生变更,使用委托驱动程序的代码则更能适应未来硬件。
[3] 三维纹理X、Y以及Z轴的比特交错模式相似。