3.1_软件层
3.1 软件层
图3-1展示了CUDA应用程序中的不同层次,从应用程序本身到CUDA硬件上执行的CUDA驱动程序。除了内核模式驱动程序以外的所有软件都执行在目标操作系统的非特权用户模式下。在现代多任务操作系统的安全模型中,用户模式是“不可信任的”,硬件与操作系统软件必须采取措施严格分割一个与另一个应用程序。对CUDA来说,这意味着一个CUDA应用程序使用的主机和设备内存无法被另一个CUDA程序使用,唯一的例外是这些程序申请内存共享,这只有在内核模式下才可做到。
CUDA库,例如cuBLAS,建立在CUDA运行时或驱动程序接口层之上。CUDA运行时是支持CUDA的集成C++/GPU工具的库。当nvcc编译器分割.cu文件分别发送至主机和设备,主机的部分会自动生成对CUDA运行时的调用,以方便像nvcc中用特别的3对尖括号<<>>启动内核这样的操作。
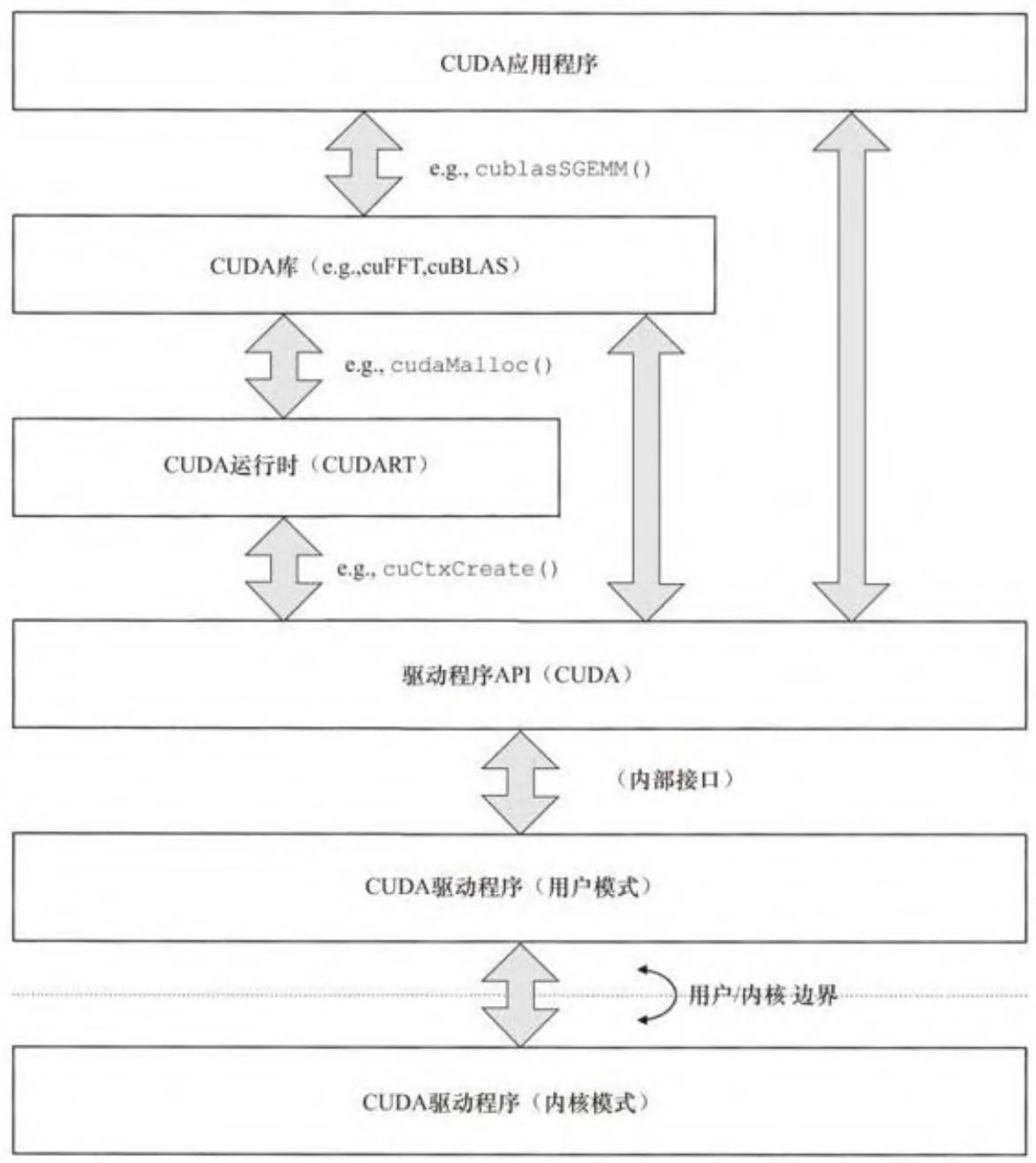
图3-1 CUDA软件层次结构
CUDA驱动程序API,由CUDA用户模式驱动程序直接导出,是CUDA应用程序可用的最底层API。驱动程序API直接调用用户模式驱动程序,之后可能会继续调用内核模式做分配内存等操作。驱动程序API和CUDA
运行时中的函数名称分别以cu*(和CUDA*)打头,许多函数,像 CUDAEventElapsedTime(),在本质上是相同的,只是在前缀上有一些区别。
3.1.1 CUDA运行时和驱动程序
CUDA运行时(经常简写为CUDA)是一个由CUDA语言集成环境使用的库。每一个版本的CUDA工具集(CUDA toolchain)都有其特定的CUDA运行时版本,应用程序会自动链接和运行时兼容的工具集,程序只有当匹配版本的CUDA在路径中可用时才能正确运行。
CUDA驱动程序是后向兼容的,支持所有同版本CUDA编写的程序和旧版本程序。它提供一个相对低层的“驱动程序API”(在CUDA.h中),使开发者能够更紧凑地整理资源和为初始化定时。驱动程序的版本可由cuDriverGetVersion()函数获取。
CResult CUDAAPI cuDriverGetVersion(int *driverVersion);
函数返回一个十进制数,给出由驱动程序支持的CUDA版本,例如,3010代表CUDA3.1,5000代表版本5.0。
表3-1总结了CUDA每个版本中的特性。在CUDA运行时应用程序中,版本信息由CUDADeviceProp结构体中的major和minor成员提供。我们会在3.3.2小节中详细审视CUDADeviceProp。
表3-1 CUDA驱动程序每版本新特性
CUDA运行时需要机器中安装的驱动程序版本高于或等于由运行时支持的CUDA版本。如果驱动程序的版本低于运行时版本,CUDA应用程序会初始化失败,弹出错误CUDAErrorInsufficientDriver(35)。CUDA 5.0引入了设备运行时(device runtime)概念,这是CUDA运行时的一个子集,可被CUDA内核直接调用。有关设备运行时的更详细描述在第7章给出。
3.1.2 驱动程序模型
除了Windows Vista和其后续版本,所有CUDA运行的操作系统(Linux、MacOS和Windows XP)通过用户模式客户端驱动程序(user mode client driver)访问硬件。这些驱动程序都不约而同地回避了一个需求,这一情况在所有现代操作系统中都普遍存在,即硬件资源
可被内核代码操纵。现代的硬件,例如GPU可以巧妙地解决这个需求——通过分配特定的寄存器(例如给硬件提交工作的硬件寄存器)进入用户模式。因为用户模式不被操作系统信任,所以对用户模式下的硬件寄存器,硬件必须包含对抗流氓写入的保护程序。这样做的目的是防止用户模式代码通过直接内存存取(DMA)修改不应该修改的代码(例如操作系统内核代码)。
硬件在用户模式和命令流之间使用一个中间层来防止内存损坏,这样DMA技术只能在之前已经被验证且已被内核代码映射的内存上使用。驱动程序开发者必须小心验证编写的内核代码,以确保代码只会访问可以使用的内存。这样的好处是程序在向硬件提交工作时不会招致多余的内核模式转换花销,我们的驱动程序可以以峰值的效率执行。
许多操作,例如内存分配,仍然需要内核模式转换,因为编辑GPU页表只能在内核模式下执行。因此,用户模式驱动程序采取了一系列步骤来减少内核模式转换的次数,例如,CUDA内存分配器尽量从内存池取出内存满足内存分配。
1. 统一虚拟寻址
在2.4.5小节中详细描述了统一虚拟寻址(unified virtual addressing,UVA),在64位Linux,64位XPDDM和MacOS操作系统上均
可使用。在这些平台上,统一虚拟寻址是内置可用的。但在本书编写时,UVA还不能够在WDDM上运行。
2. Windows显示驱动模型
在Windows Vista操作系统中,微软公司采用了新的桌面演示模型,在这个模型中,屏幕的输出由后台缓冲区与页面翻转协作完成,正如同电子游戏一样。这个新的“Windows桌面管理器”(WDM)有能力比以往Windows版本更广泛地使用GPU,所以微软公司决定修改GPU驱动模型以适应现行的桌面演示模型。新的GPU驱动模型——Windows显示驱动模型(Windows display driver model,WDDM)已经是Windows Vista及其后续版本中的默认驱动模型。而XPDDM则继续使用在Windows的以往版本中[1]。
就CUDA而言,WDDM有两个主要的改变:
1)WDDM不再允许硬件寄存器被分配进入用户模式。硬件命令——甚至是启动DMA操作的指令——必须通过内核模式来调用。用户 内核转换成本对机器来说是一个十分昂贵的行为,机器中可以使用用户模式驱动程序缓冲区来暂存指令,延迟提交。
2)WDDM的设计初衷是为了允许多应用程序同时使用同一GPU,但GPU并不支持请求式调页,WDDM中包括了在内存对象基础上模拟换页的
工具。对图形应用程序,目标包括内存对象、Z缓冲区或纹理内存;对CUDA,内存对象包括全局内存和CUDA数组。由于驱动需要在内核调用之前建立好对CUDA数组的访问,所以CUDA数组可以被WDDM交换。全局内存是驻留在一段连续的地址空间(可以存储指针的地方)里的,为了让内核成功启动,给定CUDA上下文中每一个内存对象都会驻留在这段地址空间上。
上述第一点的最主要影响:对CUDA请求的工作,例如,内核启动或异步内存复制操作,一般来说不会立即提交给硬件去操作。
提交被挂起的工作的一个惯例操作是查询默认流(NULL stream):CUDAQuery(0)或cuStreamQuery(NULL)。如果没有挂起的工作,这一调用会迅速返回;如果有工作正在挂起,这项工作将会被提交,因为这个调用是异步的,执行可能在硬件处理结束之前返回给调用者。而在非WDDM平台上,查询NULL流总是非常快的。
上述第二点的主要作用是使CUDA内存分配控制更加灵活。在用户模式客户端驱动程序中,成功的内存分配意味着:一旦内存空间被分配,那么它无法为操作系统中的其他客户端程序(例如游戏或正在运行的CUDA应用程序)再次占用。在WDDM下,如果有应用程序在相同的GPU中竞争使用时间,Windows能够交换出内存对象使每一个应用程序顺利运行。Windows操作系统会尽其所能提高这项工作的效率。当然,
对于所有的可能有换页操作的程序,尽量不让换页操作发生是最好的选择。
3. 超时检测与恢复
因为Windows使用GPU同用户交互,所以计算程序不能占用GPU过多的时间。在WDDM中,Windows设定了强制延时界限(默认为2秒),这意味着,如果出现了持续的时间超过设定延时的情况,系统会弹出带有“显示驱动程序停止响应并已恢复”(display driver stopped responding and has recovered)的对话框,随后显示驱动程序重新启动。如果这种情况发生,在所有CUDA上下文所做的工作都会丢失。查看http://bit.ly/16mG0dX获取详细内容。
4. 特斯拉计算集群驱动程序
因为计算程序不需要WDDM,英伟达提供特斯拉计算集群(TCC)驱动程序,只在特斯拉级板上可用(Tesla-class board)。特斯拉计算集群驱动程序(Tesla compute cluster driver)是一个用户模式下的客户端驱动程序,所以这并不需要内核转换(kernel thunk)去给硬件提交工作,我们可以使用nvidia-smi工具来启用或禁用它。
3.1.3 nvcc、PTX和微码
nvcc是CUDA开发者使用的编译器驱动程序,它可以使CUDA源代码转成一个可执行的CUDA应用程序。nvcc可以做很多事,如编译、链接和用一条指令执行一个示例程序(本书中很多程序鼓励使用的一种用法),编译一个只在GPU上执行的.cu文件。
图3-2展示了使用nvcc的推荐工作流程,包括CUDA运行时和驱动程序API应用程序。对于规模很大的应用程序,nvcc最好严格地编译CUDA代码并封装CUDA功能到可以被其他工具调用的代码,这是由于nvcc存在如下限制:
·nvcc只在特定的编译器上工作。许多CUDA开发者不曾注意到这一限制,因为他们只使用支持CUDA的编译器。但是在软件生产环境中,CUDA的代码量与其他代码相比简直是微不足道,所以编译器是否支持CUDA未必是决定编译器使用的因素。
·nvcc所改变的编译环境可能与其他大量应用程序的生成环境不兼容。
·nvcc会使用一些非标准内建类型(如int2)和固有名称(如__popc()“破坏”命名空间的纯洁性。只有在最近的CUDA版本中,固有的符号才变成可选项,且可以通过引入适当的sm_*_intrinsics.h头文件来使用。
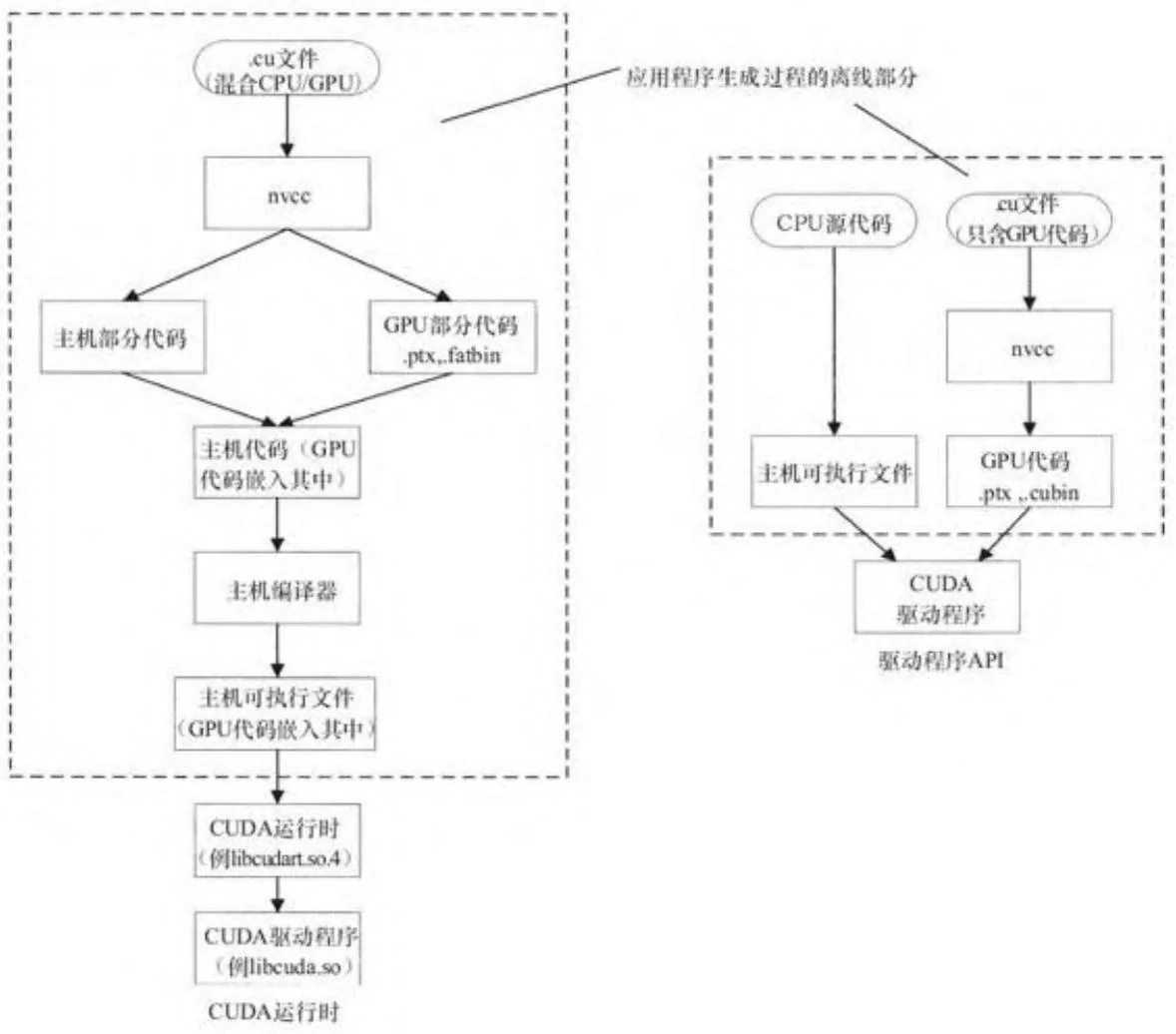
图3-2 nvcc工作流程图
对于CUDA运行时应用程序,nvcc会把GPU代码转化为字符串字面值,嵌入可执行文件。如果选用--fatbin选项,可执行文件会自动加载目标GPU的微码,如果没有微码可用,会让驱动程序自动编译PTX为微码。
nvcc与PTX
并行线程执行(Parallel Thread Execution,PTX)代码是编译后的GPU代码的一种中间形式,它可以再次编译为原生的GPU微码。这是英伟达公司为CUDA程序面向未来指令集所建立的一个创新机制,这意味着只要给定的CUDA内核的PTX是可用的,CUDA驱动程序便可将其编译为在GPU上执行的程序的微码(即使在编写代码时GPU对其并不可用)。
PTX可以离线或在线方式编译为GPU微码。离线编译指的是生成未来可在计算机上执行的程序。在图3-2中,我们圈出了CUDA编译过程中的离线编译部分。对于在线编译方式,我们可以理解为“即时”(just-in-time,JIT)编译,指的是程序可以在运行时将PTX代码在线编译为GPU微码。
nvcc可以通过调用PTX编译器ptxas离线编译PTX,这将会把PTX编译为特定GPU版本的原生微码。生成的微码存储在CUDA二进制形式的‘cubin’(发音类似“Cuban”)文件中,cubin文件可以使用cuobjdump--dump-sass命令进行反汇编,这将根据特定GPU的微码生成SASS代码[2]。
PTX同样可以通过CUDA驱动程序在线编译(JITted)。当我们运行使用--fatbin选项编译的(这是默认选项)CUDART程序时,在线编译是自动启动的。每个内核的.cubin和PTX都包含在可执行文件里,如果
硬件不支持可执行文件里的.cubin,驱动程序便会编译PTX。驱动程序将其缓存在磁盘上,因为编译PTX可能花费大量时间。
最后,PTX可以在运行时通过显式调用cuModuleLoadEx()编译。驱动程序API不会自动嵌入或加载GPU微码。.cubin和.ptx均作为参数传给cuModuleLoadEx()函数,如果.cubin不兼容机器的GPU架构,会返回一个错误。对驱动程序API开发者来说,一个合理的处理策略是编译并嵌入PTX,并且应该总调用cuModuleLoadEx()以JIT编译到GPU,依赖驱动程序来缓存编译后的微码。
[1] 特斯拉板(Tesla boards)(没有任何显示输出的能运行 CUDA 的电路板)可以在 Windows 上使用 XPDDM,称为特斯拉计算集群(Tesla compute cluster,TCC)驱动程序,可被 nvidia-smi 工具触发。
[2] 审视SASS代码是程序优化的主要策略之一。