2.1_CPU配置
2.1 CPU配置
本节及随后的两节介绍各种CPU/GPU架构,并对CUDA开发者如何编程方面给出了一些意见和建议。我们研究了CPU配置、集成GPU和多GPU配置。现在,让我们从图2-1开始谈起。
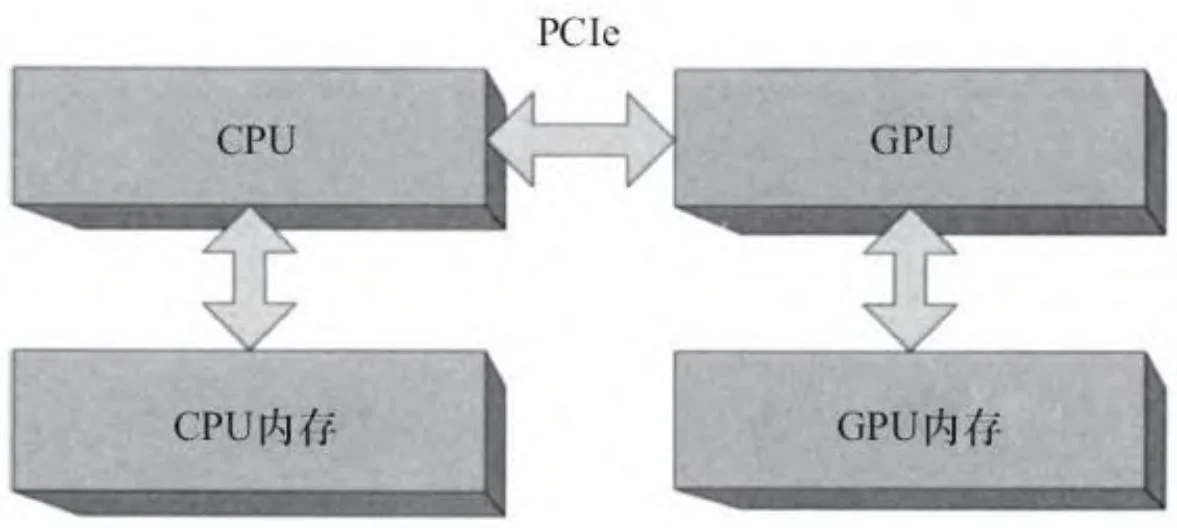
图2-1 CPU/GPU架构简略图
图2-1中省略了一个重要元素,那就是连接CPU与外界的“芯片组”(“核心逻辑”)。系统每一比特的输入与输出,包括磁盘、网络控制器、键盘、鼠标、USB设备以及GPU的输入输出,都要通过芯片组。直到最近,芯片组被一分为二:一个是连接大多外围设备和系统的“南桥”[1],另一个是包含图形总线(加速图形端口,后被PCIe接口取代)和内存控制器(通过前端总线与内存相连)的“北桥”。
每一个PCIe(peripheral communications interconnect express)2.0的“通道”(lane)理论上可以提供500MB/s的带宽。对于一个给定的外设,其通道数可以是1、4、8或16个。GPU需要平台上所有外设的最大带宽,所以它们一般被插入由16通道构成的PCIe插槽。考虑到数据包的附加消耗,该连接的8G/s带宽实际上能达到6G/s。[2]
2.1.1 前端总线
图2-2是将北桥和内存控制器添加到图2-1后的简化图。为了完整起见,图2-2还显示了GPU的集成内存控制器,它是在一个与CPU内存控制器完全不同的约束集下设计的。GPU必须调解所谓的同步客户端,例如视频显示,其带宽要求是固定的。GPU内存控制器在设计时还考虑了GPU对延迟的容忍度以及大量内存带宽方面的内在需求。在写作本书时,高端GPU通常所提供的本地显存带宽大大超过100G/s。GPU内存控制器总是和GPU集成,因此本章其余部分的图示中省略了它们。
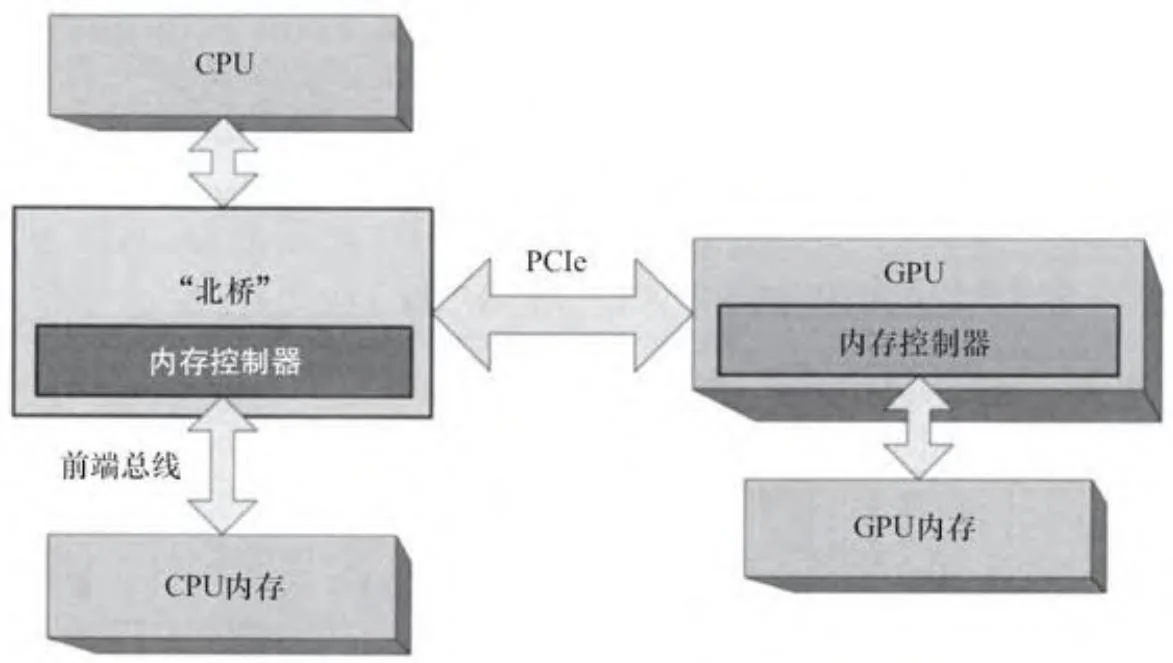
图2-2 CPU/GPU架构(带北桥)
2.1.2 对称处理器簇
图2-3显示的是一个传统北桥配置上的多CPU系统。[3] 多核处理器之前,应用程序必须使用多线程以便充分利用多CPU的额外运算能力。即使每个CPU和北桥本身都包含有缓存,北桥也必须确保每个CPU看到相同的、一致的内存视图。由于这些所谓的“对称处理器簇”(SMP)系统共享同一个通往CPU内存的路径,不同CPU的内存访问性能相对一致。
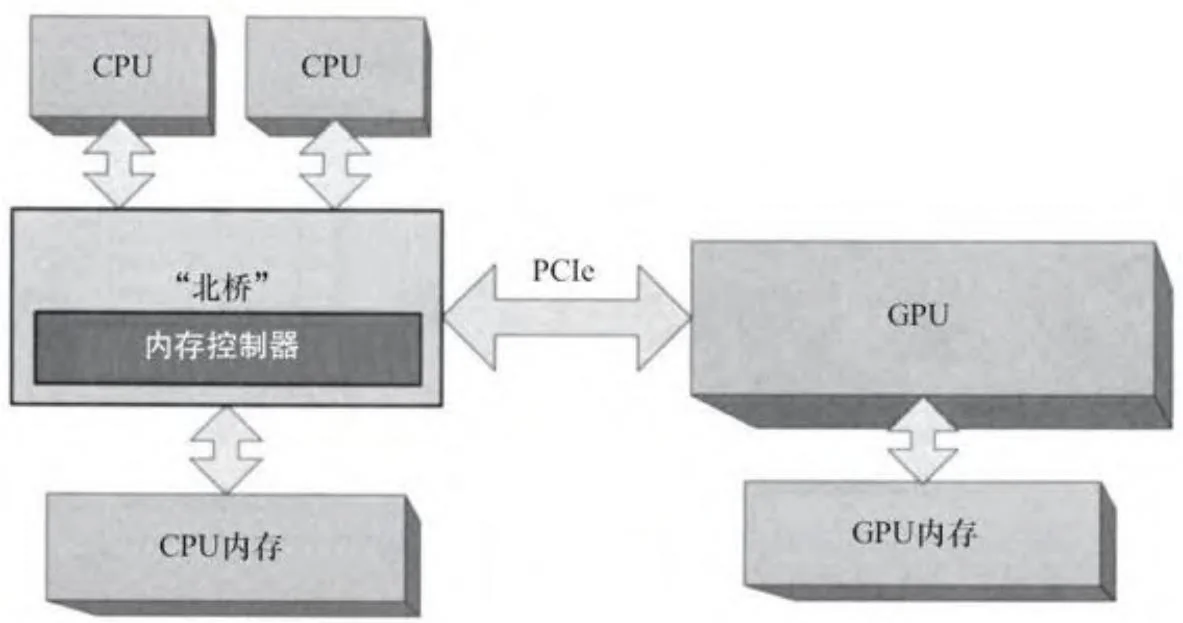
图2-3 多CPU(SMP配置下)
2.1.3 非一致内存访问(NUMA)
从AMD的Opteron处理器和Intel的Nehalem(酷睿i7)处理器谈起,北桥的内存控制器直接集成到CPU中,如图2-4所示。这种结构的变化,提高了CPU的内存性能。
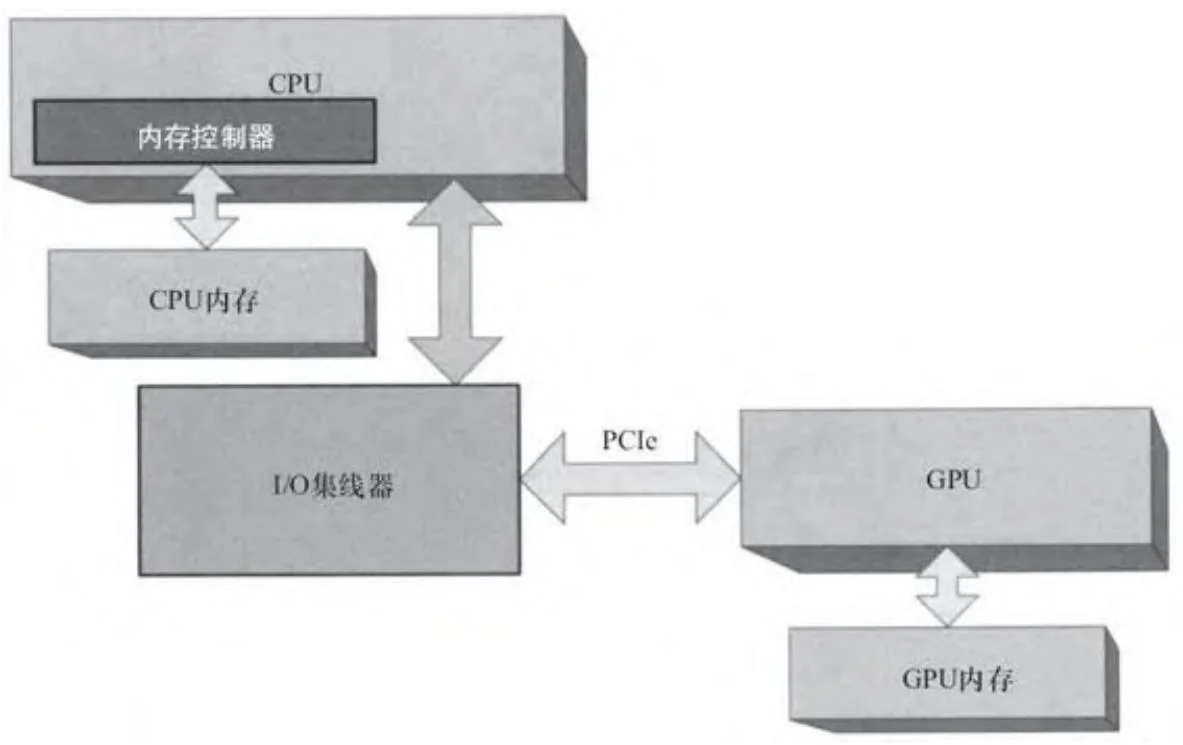
图2-4 带有集成内存控制器的CPU
对于开发人员,图2-4中的系统和我们讨论过的只是略有不同。而对于包含多个CPU的系统而言,如图2-5所示,那就变得很不一样了。
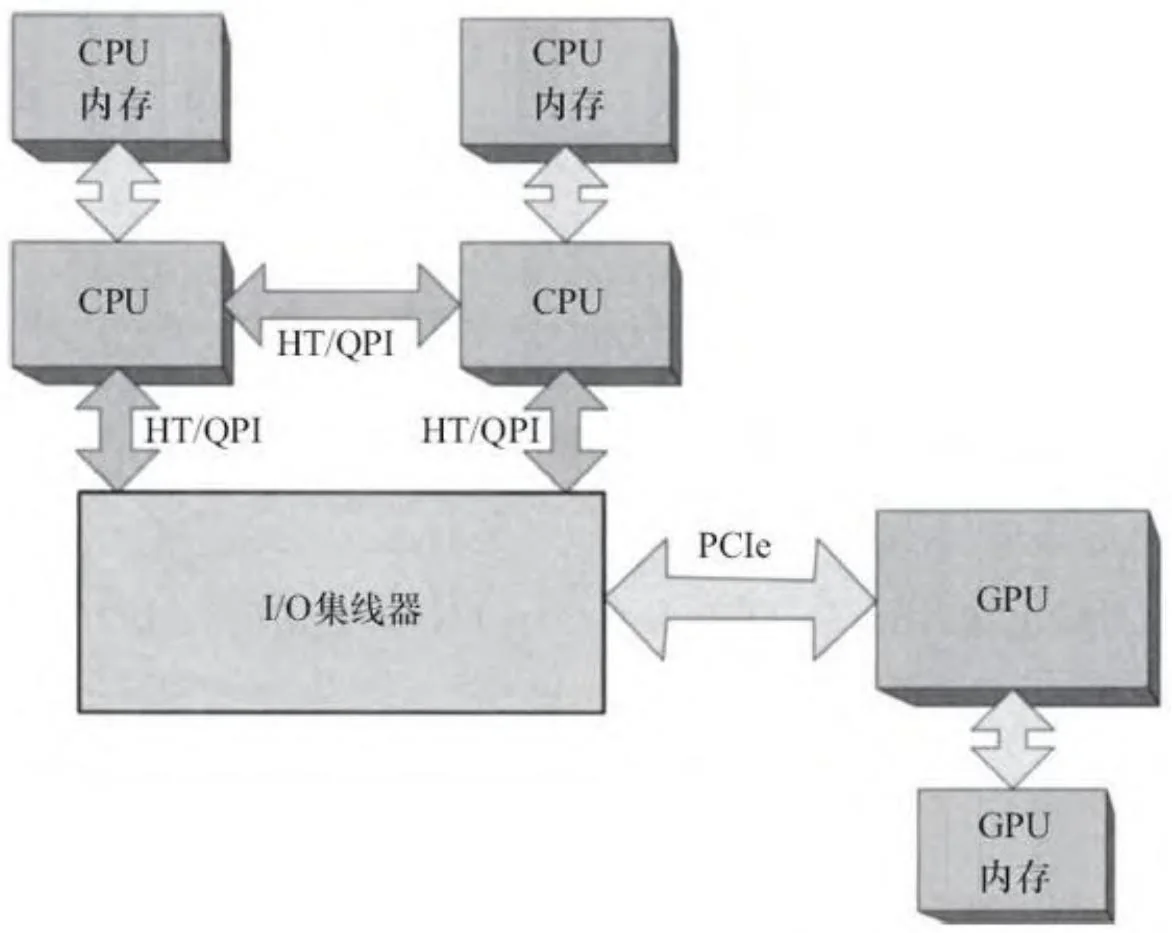
图2-5 多GPU(NUMA)
对于配置有多个CPU的机器 [4],这种架构意味着,每个CPU都有自己的内存带宽池。与此同时,由于多线程操作系统和应用程序依赖于前文中CPU和北桥配置下缓存的一致性,Opteron和Nehalem架构分别推出了超传输(HT)和快速通道互联(Quick Path Interconnect, QPI)。
HT和QPI是CPU之间、CPU与I/O集线器的点对点连接。在采用HT/QPI的系统中,每个CPU都可以访问任何内存存储单元。但是对内存的物理地址直接附属于CPU的本地内存单元的访问会更快。“非本地访
问”的执行有赖于HT/QPI检查其他CPU的缓存,清除所请求数据的缓存副本,然后传递数据到发出请求的CPU。通常,这些CPU的大型片上缓存降低了非本地内存访问的成本。而且,发出请求的CPU可以在自身缓存层次上保留该数据,直到另一个CPU向内存提出申请为止。
为了帮助开发者解决这些性能陷阱,Windows和Linux系统引入API。这样应用程序能够使用特定CPU以及设置“线程亲和的”(thread affinity)CPU。因此,当操作系统把线程调度到CPU时,可以保证大部分甚至是全部的内存都是本地访问的。
一个爱钻研的程序员可以使用这些API来精心设计代码以暴露NUMA的性能缺陷。但更常见(和隐性)的问题是,由于运行在不同CPU上的两个线程的“伪共享”,导致过多的HT/QPI事务在同一缓存行上访问内存存储单元。因此,NUMA API必须慎用。它们虽然给程序员提供了提高性能的工具,但也容易因开发者误用而带来性能问题。
减轻访问非本地内存对性能影响的方法之一,是以缓存行边界为准,在CPU间均匀划分物理内存,也就是所谓的内存重叠[5]。对于CUDA而言,这种方法在如图2-5所示的系统中非常有效(其为一个NUMA模式配置,多CPU和GPU通过一个共享的I/O集线器连接)。由于PCIe带宽往往是整体应用性能的瓶颈,许多系统将使用独立的I/O集线器去服务更多的PCIe总线,如图2-6所示。
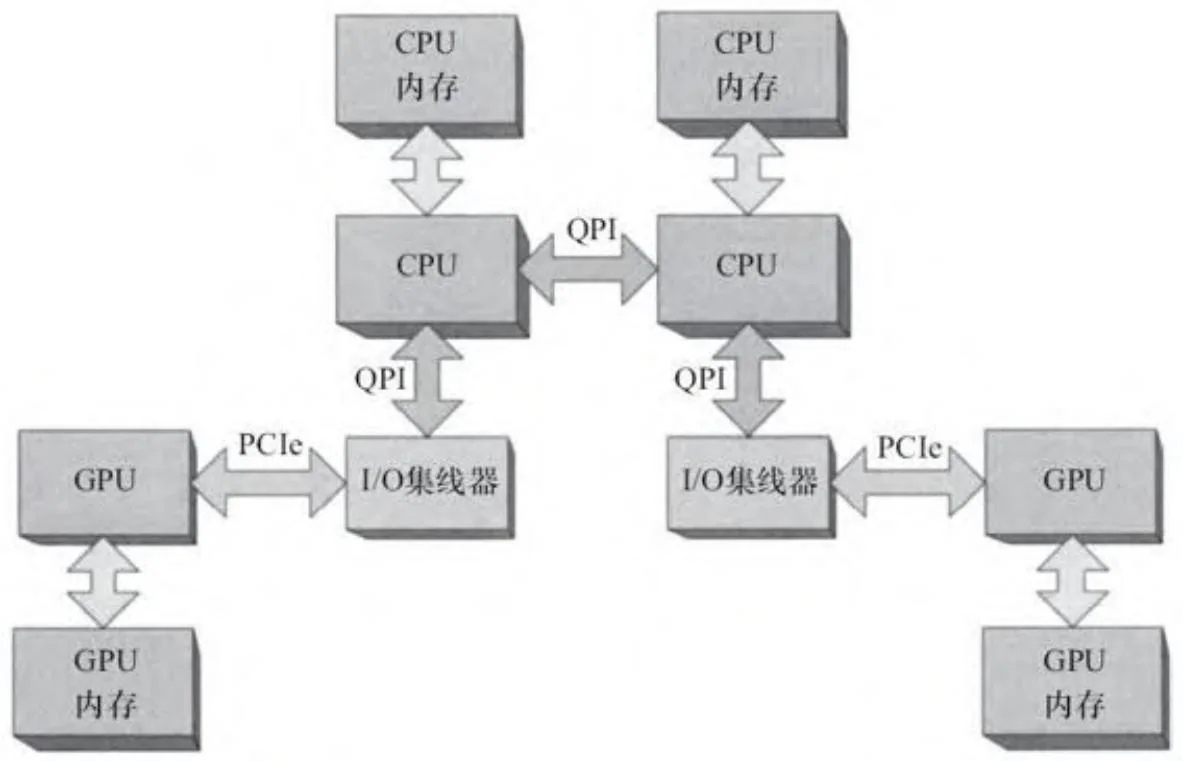
图2-6 带多个总线的多CPU(NUMA配置)
为了很好地运行在这样一个“亲和”系统上,CUDA应用程序必须注意NUMA API的使用,以便为连接到给定GPU的PCIe总线执行本地的内存分配和线程亲和的调度。否则,由GPU发起的内存复制将是非本地的,内存事务将在HT/QPI互连结构中需要额外的“跳跃”。由于GPU需要巨大的带宽,这些DMA操作会降低HT/QPI为其主要对象服务的能力。和伪共享相比,对于CUDA应用程序而言,GPU的非本地内存复制操作对性能的影响有可能更为要命。
2.1.4 集成的PCIe
如图2-7所示,通过将I/O集线器集成到CPU中,英特尔的沙桥(Sandy Bridge)系列处理器是迈向全面的系统集成的又一步。单个沙桥CPU的PCIe接口有多达40个通道(请记住,一个GPU最多可使用16个通道,所以40个通道足够支持两个完整的GPU)。
对于CUDA开发者,集成的PCIe有利有弊。弊端是,PCIe通路始终是亲和的。设计师不能建立单一I/O集线器服务于多个CPU的系统(即图2-5所示的系统);所有的多CPU系统都类似于图2-6。其导致的结果是,不同CPU上的GPU之间无法执行点对点操作。而优点是,CPU缓存可以直接参与PCIe总线通信:DMA读请求可以直接读取缓存,并且GPU写入的数据会放入缓存中。
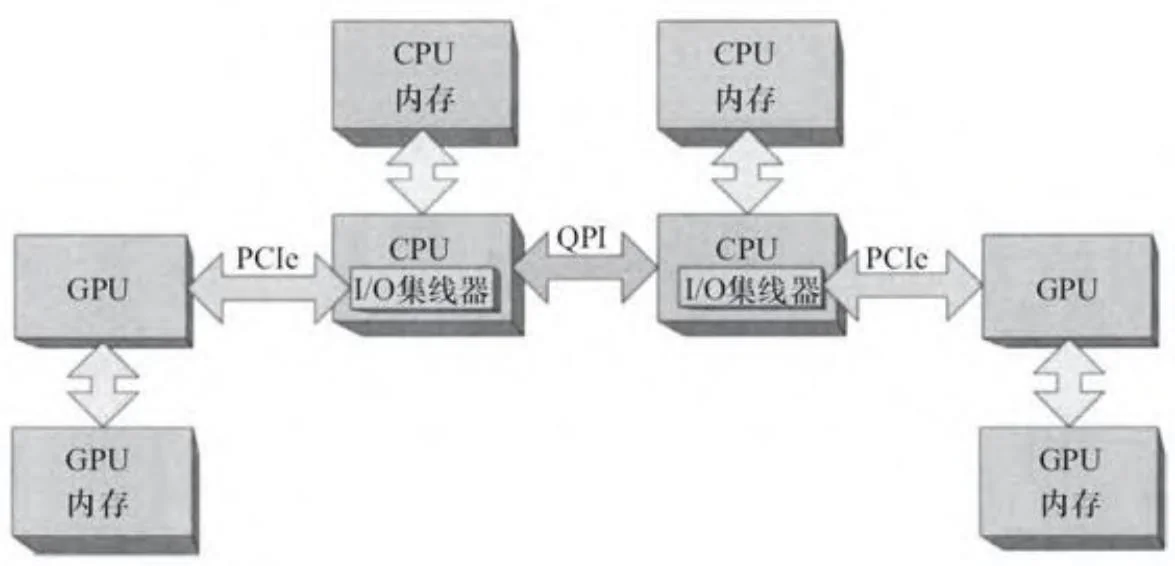
图2-7 带集成PCIe的多CPU
[1] 为简单起见,本节的所有图中均略去南桥。
[2] PCI 3.0所能提供的带宽相当于PCIe 2.0的两倍。
[3] 我们之所以提供图2-3,不只是因为该配置是支持CUDA的计算机,更是作为历史资料参照。
[4] 在这样的系统中,CPU也可以被称为“节点”或“CPU插槽”。
[5] 也有相反的说法,说这使得所有的内存访问“同样糟糕”。