6.5_并发复制和内核处理
6.5 并发复制和内核处理
由于为了让GPU操作数据,CUDA应用程序必须通过PCIe总线传输数据。另一个提升性能的机会是以并发形式执行那些主机与设备间的传输和内核处理。根据阿姆达尔法则 [1],使用多个处理器的最大加速比是
其中 ,N 是处理器的数量。在并发执行复制和内核处理的情况下,“处理器的数量”就是GPU中自主硬件单元的数量:1个或者2个复制引擎,加上执行内核的流处理簇。对于 N=2,图6-6展示了随着 和 变化的理想化的加速曲线。
所以在理论上,一个2倍的性能提高在有一个复制引擎的GPU上是可能的,但是仅当程序在流处理簇和复制引擎之间得到完美的重叠,并且仅当程序在传输和处理数据上花费相同的时间的时候是如此。
在进行这种努力之前,你应该仔细看看这是否有利于你的应用程序。极端传输受限型(即它们把大多数时间花费在与GPU交换数据上)或者极端计算受限型(即它们花费大多数时间处理GPU上的数据)的应用程序只能从重叠传输和计算中少量受益。
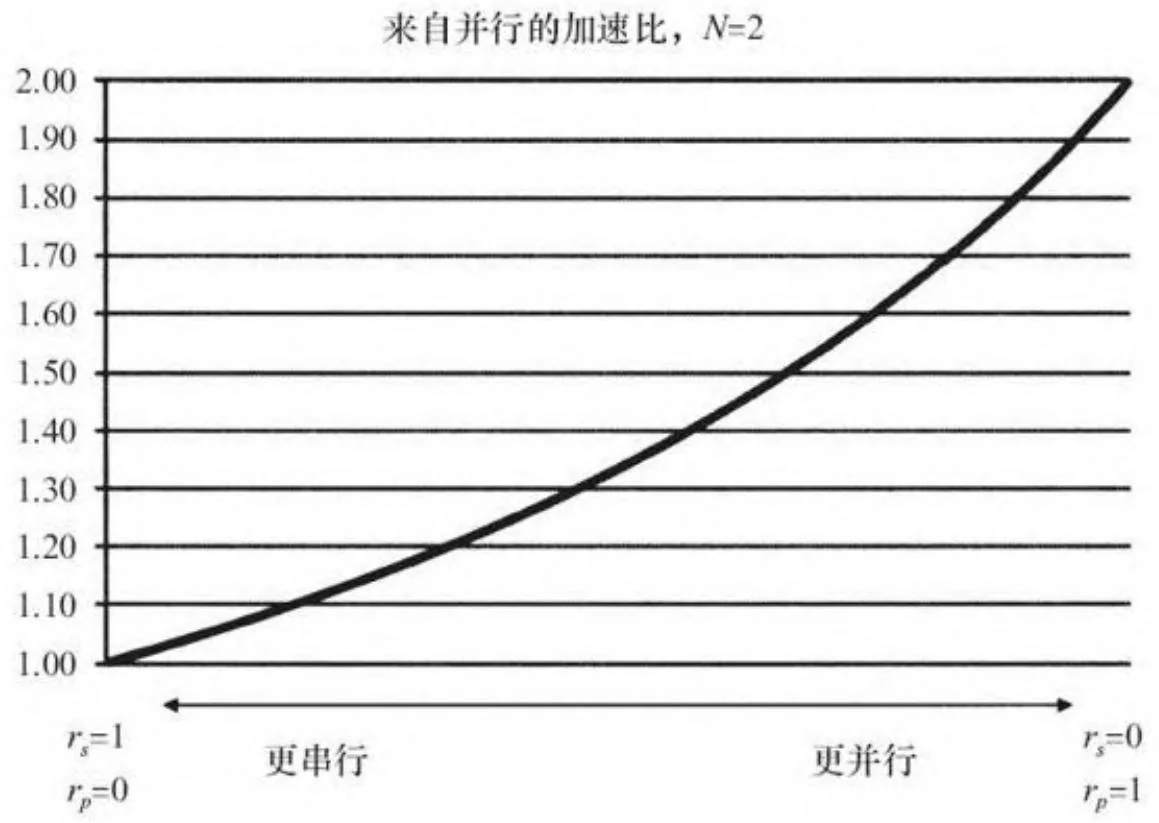
图6-6 理想的阿姆达尔法则曲线
6.5.1 concurrencyMemcpyKernel.cu
concurrencyMemcpyKernel.cu程序旨在说明的不仅有怎样实现并发的内存复制和内核执行,还有怎样确定这样做是否值得。代码清单6-3给出了AddKernel()——一个“花哨”的内核,使用一个参数cycles来控制它的运行时间。
代码清单6-3 AddKernel(),一个带有计算密度参数的花哨内核
global void AddKernel( int \*out, const int \*in, size_t N, int addValue, int cycles) for (size_t i $=$ blockIdx.x\*blockDim.x+threadIdx.x; i $< \mathbb{N}$ . i $+ =$ blockDim.x\*gridDim.x) { volatile int value $=$ in[i]; for (int j $= 0$ ;j $<$ cycles;j++) { value $+ =$ addValue; } out[i] $=$ value;AddKernel()流从in读出一个整数型数组到out,对每个输入值循环cycles次。通过改变cycles的值,我们可以使内核涵盖从一个简单内存带宽受限型的流内核到完全的计算受限型内核的整个范围。
程序中的这两个子程序可测量AddKernel()的性能。
·TimeSequentialMemcpyKernel()将输入数据复制到GPU、调用AddKernel()并且从GPU以独立的、顺序的方式复制到输出。
· TimeConcurrentOperations()分配了一些CUDA流,并且同时完成主机端到设备端的内存复制、内核处理以及设备端到主机端的内存复制。
TimeSequentialMemcpyKernel(),在代码清单6-4中给出,使用了4个CUDA事件来分别计时主机端到设备端的内存复制、内核处理以及设备端到主机端的内存复制。它也报告CUDA事件测量的总时间。
代码清单6-4 TimeSequentialMemcpyKernel()函数
bool
TimeSequentialMemcpyKernel( float *timesHtoD, float *timesKernel, float *timesDtoH, float *timesTotal, size_t N, const chShmooRange& cyclesRange, int numBlocks)
{udaError_t status; bool ret $=$ false; int \*hostIn $= 0$ int \*hostOut $= 0$ int \*deviceIn $= 0$ int \*deviceOut $= 0$ const int numEvents $= 4$ udaEvent_t events[numEvents]; for (int i $= 0$ ;i $<$ numEvents;i++) { events[i] $=$ NULL; CUDART_CHECK(cudaEventCreate(&events[i])); }udaMallocHost(&hostIn,N\*sizeof(int));udaMallocHost(&hostOut,N\*sizeof(int));udaMalloc(&deviceIn,N\*sizeof(int));udaMalloc(&deviceOut,N\*sizeof(int)); for (size_t i $= 0$ ;i $<$ N; i++) { hostIn[i] $=$ rand();
}udaDeviceSynchronize();
for(chShmooIterator cycles(cyclesRange);cycles;cycles++){ printf(".”); fflush( stdout);udaEventRecord(evento[O],NULL);udaMemcpyAsync deviceIn,hostIn,N\*sizeof(int),udaMemcpyHostToDevice,NULL);udaEventRecord(evento[1],NULL); AddKernel<<numBlocks,256>>deviceOut,deviceIn,N,0xcc,\*cycles);udaEventRecord(evento[2],NULL);udaMemcpyAsync(hostOut,deviceOut,N\*sizeof(int),cudamemcpyDeviceToHost, NULL);
cudaleventRecord( events[3], NULL);
cudadevicessynchronize();
cudaleventElapsedTime( timesHtoD, events[0], events[1]);
cudaleventElapsedTime( timesKernel, events[1], events[2]);
cudaleventElapsedTime( timesDtoH, events[2], events[3]);
cudaleventElapsedTime( timesTotal, events[0], events[3]);
timesHtoD += 1;
timesKernel += 1;
timesDtoH += 1;
timesTotal += 1;
}
ret = true;
Error: for ( int i = 0; i < numEvents; i++) { CUDADestroy( events[i]); } CUDAFree( deviceIn ); CUDAFree( deviceOut ); CUDAFreeHost( hostOut ); CUDAFreeHost( hostIn ); return ret;cyclesRange参数,使用了在附录A.4节中描述的“shmoo”功能,它指定了当调用AddKernel()时使用的循环值的范围。在一个EC2中的cgl.4xlarge实例上,循环值的时间是 (以毫秒计),如下:
对那些*cycles值处于48(已高亮显示)附近的结果,我们看到内核花费的时间和内存复制操作占用的时间一样多,我们可以假定并发执行操作是有利的。
TimeConcurrentMemcpyKernel()函数会把AddKernel()执行的计算分为大小为stream Increment的片段,并且分别使用单独的CUDA流计算每一片段。代码清单6-5中来自Time ConcurrentmemcpyKernel()的代码片段突出了流编程的复杂性。
代码清单6-5 TimeConcurrentmemcpyKernel()片段
intLeft $\equiv$ N;
for ( int stream $= 0$ ; stream < numStreams; stream++) { size_t intsToDo $=$ (intsLeft $< _{\cdot}$ intsPerStream) ? intsLeft : intsPerStream; CUDArt_CHECK{ CUDAMemcpyAsyncc deviceIn+stream\*intsPerStream, hostIn+stream\*intsPerStream, intsDo\*sizeof(int),udaMemcyHostToDevice, streams[stream])}; intsLeft $\equiv$ intsToDo;
}
intsLeft $\equiv$ N;
for ( int stream $= 0$ ; stream < numStreams; stream++) { size_t intsToDo $=$ (intsLeft $< _{\cdot}$ intsPerStream)? intsLeft:intsPerStream; AddKernel<<numBlocks,256,0,streams[stream]>>>( deviceOut+stream\*intsPerStream, deviceIn+stream\*intsPerStream, intsDo,0xcc,\*cycles); intsLeft $\equiv$ intsToDo;
}
intsLeft $\equiv$ N;
for ( int stream $= 0$ ; stream < numStreams; stream++) { size_t intsToDo $=$ (intsLeft $< _{\cdot}$ intsPerStream)? intsLeft:intsPerStream; CUDArt_CHECK(udaMemcpyAsyncc hostOut+stream\*intsPerStream, deviceOut+stream\*intsPerStream, intsDo\*sizeof(int),udaMemcyDeviceToHost, streams[stream])}; intsLeft $\equiv$ intsToDo;除了要求应用程序来创建和销毁CUDA流之外,对于每一个主机到设备端的内存复制、内核处理以及设备到主机端的内存复制操作,流必须分别循环遍历。如果没有这种“软件流水线”的话,将没有不同流中工作的并发执行,因为每个流中的操作都要在前面加上“互锁”操作,以防止此操作继续执行直至同一流中之前的所有操作均完成。其结果将不仅仅是无法启动引擎间的并行执行,而且由于管理流并发性的轻微开销也将有额外的性能下降。
计算无法完全并发处理,因为没有内核处理能与第一个或者最后一个内存复制重叠执行,并且在CUDA流之间的同步上会有一些开销,正如我们在之前的章节知道的,在调用内存复制上和内核操作本身上也会有一些开销。其结果是,流的最佳数目取决于应用程序,并且应该根据经验来确定。在concurrencyMemcpyKernel.cu程序中,通过在命令行上使用--numStreams参数指定流的数目。
6.5.2 性能结果
带有固定的缓冲区大小和一定数量的流的concurrencyMemcpyKernel.cu程序会根据cycles值报告相应的性能特征。在亚马逊EC2的cgl.4xlarge实例中,有一个128MB大小的缓冲区和8个流,如下报告所考查的cycles值的范围为
对应cycles从 的完整曲线见图6-7。不幸的是,对于这些设置而言,这里仅有 的加速,远低于理论上可以得到的3倍加速。
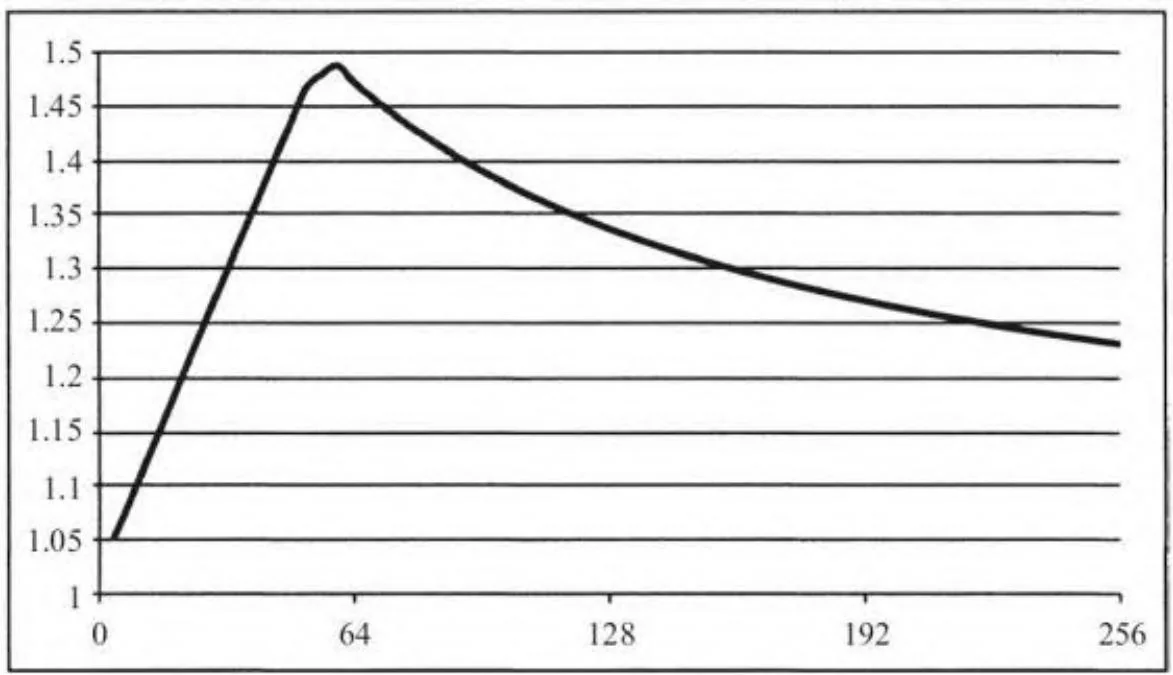
图6-7 内存复制/内核并发(Tesla M2050)带来的加速比
仅仅包含一个复制引擎的GeForce GTX 280的优势更为明显。这里图6-8展示了cycles的值变至512的结果。从图中可以看出,它的最大加速比更接近2倍这一理论上的最大值。
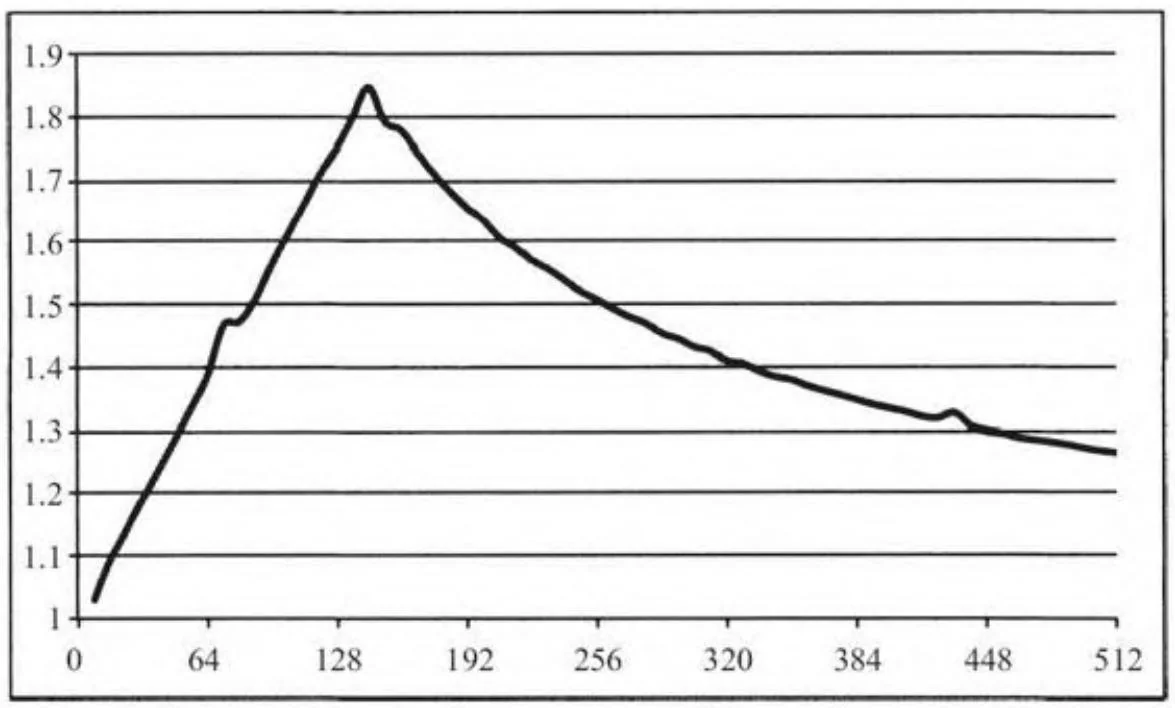
图6-8 内存复制/内核并发(GeForce GTX 280)带来的加速比
正如已写到的那样,concurrencyMemcpyKernel.cu不过就是起一个演示作用,因为AddValues()仅仅是一个花哨的内核。但是可以把自己的内核插入这个应用程序以便确定是否使用流的额外复杂性对性能提高有利。请注意,除非需要并发的内核执行(参看6-7节),代码清单6-5中的内核调用可以用同一个流中的连续的内核调用代替,并且,应用程序仍将得到理想的并发性。
附加说明,复制引擎的数量可以通过调用CUDAGetDeviceProperties()并检查CUDADeviceProp::asyncEngineCount属性查询,也可以使用带有CU_DEVICE_ATTRIBUTE_ASYNCENGINE_COUNT标志的cuDeviceQueryAttribute()来查询。
SM 1.1和部分SM 1.2硬件的复制引擎仅仅可以复制线性内存,但是更新的复制引擎全面支持2D内存复制,包括2D和3D的CUDA数组。
6.5.3 中断引擎间的并发性
使用CUDA流用于并发的内存复制和内核执行程序的同时会带来更多的“中断并发”的机会。在先前的小节中,CPU/GPU并发性能够被无意中做的一些事(可以导致CUDA执行一个完整的CPU/GPU同步)中断。在这里,CPU/GPU并发性可以被无意中执行的未指定流的CUDA操作中断。回想一下,NULL流会强制所有的GPU引擎汇聚,所以如果指定了NULL流,那么即使一个异步的内存复制也将使多个引擎之间的并发停止。
除了明确指定NULL流外,这些无意的“并发中断”的主要来源是隐式运行在NULL流的函数调用,因为它们没有使用流参数。当在CUDA1.1中第一次引入流时,一些函数比如CUDAMemset()和cuMemcpyDtoD(),以及类似CUFFT和CUBLAS库的接口,也没有以任何方
式为应用程序指定流参数。目前Thrust库仍不支持这一功能。CUDA Visual Profiler会在它的报告中定位出并发中断。