9.4_计算直方图
9.4 计算直方图
通常,有些算法需要计算某个数据集的直方图。如果之前没有计算或使用过直方图,也不用担心,直方图是个很简单的概念。给定一个包含一组元素的数据集,直方图表示每个元素的出现频率。例如,如果计算词组“Programming with CUDA C”中字符频率的直方图,那么将得到图9.1所示的结果。
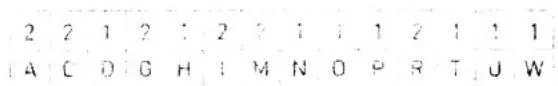
图9.1 字符串“Programming with CUDA C”中字符频率直方图
虽然直方图的定义很简单,但却在计算机科学领域得到了非常广的应用。在各种算法中都用到了直方图,包括图像处理、数据压缩、计算机视觉、机器学习、音频编码等等。我们将把直方图计算作为接下来代码示例的算法。
9.4.1 在CPU上计算直方图
由于并非所有的读者都熟悉直方图的计算,因此我们首先将给出如何在CPU上计算直方图的示例。这个示例同时也说明了在单线程应用程序中计算直方图是非常简单的。这个应用程序将处理一个大型的数据流。在实际程序中,这个数据可以是像素的颜色值,或者音频采样数据,但在我们的示例程序中,这个数据将是随机生成的字节流。我们可以通过工具函数big_random_block()来生成这个随机的字节流。在应用程序中将生成100MB的随机数据。
include"../common/book.h
#defineSIZE (100\*1024\*1024)
int main(void){ unsigned char \*buffer $=$ (unsigned char*)big_random_block(SIZE);由于每个随机字节(8比特)都有256个不同的可能取值(从0x00到0xFF),因此在直方图中需要包含256个元素,每个元素记录相应的值在数据流中的出现次数。我们创建了一个包含256个元素的数组,并将所有元素的值初始化为0。
unsigned int histo[256];
for (int i = 0; i < 256; i++)
histo[i] = 0;在创建了直方图并将数组元素初始化为0后,接下来需要计算每个值在buffer[]数据中的出现频率。算法的思想是,每当在数组buffer[]中出现某个值z时,就递增直方图数组中索引为z的元素。这样就能计算出值z的出现次数。
如果当前看到的值为buffer[i],那么将递增数组中索引等于buffer[i]的元素。由于元素buffer[i]位于histo[buffer[i]],我们只需一行代码就可以递增相应的计数器。
histo[buffer[i]]++;我们在一个简单的for()循环中对buffer[]中的每个元素执行这个操作:
for (int i=0; i<SIZE; i++)
histo[buffer[i]]++;此时,我们已经计算完了输入数据的直方图。在实际的应用程序中,这个直方图可能作为一个计算步骤的输入数据。但在这里的简单示例中,这就是要执行的所有工作,因此接下来将验证直方图的所有元素相加起来是否等于正确的值,然后结束程序。
long histoCount $= 0$
for (int $\mathrm{i} = 0$ .i<256; i++) { histoCount $+ =$ histo[i];
}
printf(“Histogram Sum: $\% 1d\backslash n$ ",histoCount);思考一下就会发现,无论输入数组的值是什么,这个和值总是相同的。每个元素都将统计相应数值的出现次数,因此所有这些元素值的总和就应该等于数组中元素的总数量。在示例中,这个值就等于SIZE。
无需多言(但我们总是会提醒),在执行完运算后需要释放内存并返回。
free(buffer); return 0;我们在一台Core2 Duo机器上测试这个程序,数组大小为100MB,数组直方图的计算时间为0.416秒。这相当于一个基线性能,稍后我们将把这个性能与GPU版本程序的性能进行比较。
9.4.2 在GPU上计算直方图
我们把这个直方图计算示例改在GPU上运行。如果输入的数组足够大,那么通过由多个线程来处理缓冲区的不同部分,将节约大量的计算时间。其中,由不同的线程来读取不同部分的输入数据是非常容易的。这与我们到目前为止看到的示例都非常相似。在计算输入数组的直方图时存在一个问题,即多个线程可能同时对输出直方图的同一个元素进行递增。在这种情况下,我们需要通过原子的递增操作来避免9.3节中提到的问题。
main()函数非常类似于CPU版本的函数,只是我们需要增加一些CUDA C的代码,包括将输入数据放入GPU以及从GPU得到结果。main()函数的开头与基于CPU的版本完全一样:
int main(void) { unsigned char *buffer = (unsigned char*)big_random_block(SIZE);由于要测量代码的执行性能,因此我们将初始化计时事件。
cudaEvent_t start, stop;
HANDLE_ERROR(udaEventCreate(&start));
HANDLE_ERROR(udaEventCreate(&stop));
HANDLE_ERROR(udaEventRecord(start, 0));在设置好输入数据和事件后,我们需要在GPU上为随机输入数据和输出直方图分配内存空间。在分配了输入缓冲区后,我们将big_random_block()生成的数组复制到GPU上。同样,在分配了直方图后,像CPU版本中那样将其初始化为0。
// 在GPU上为文件的数据分配内存
unsigned char *dev_buffer;
unsigned int *dev_histo;
HANDLE_ERROR(udaMalloc((void**)&dev_buffer, SIZE));
HANDLE_ERROR(udaMemcpy(dev_buffer, buffer, SIZE,udaMemcpyHostToDevice));
HANDLE_ERROR(udaMalloc((void**)&dev_histo,256*sizeof(int));
HANDLE_ERROR(udaMemset(dev_histo,0,256*sizeof(int));你可能已经注意到,在上面的代码中引入了一个新的CUDA运行时函数,CUDAMemset()。这个函数的原型与标准C函数memset()的原型是相似的,并且这两个函数的行为也基本相同。二者的差异在于,CUDAMemset()将返回一个错误码,而C库函数memset()则不是。这个错误码将告诉调用者在设置GPU内存时发生的错误。除了返回错误码外,还有一个不同之处就是,CUDAMemset()是在GPU内存上执行,而memset()是在主机内存上运行。
在初始化输入缓冲区和输出缓冲区后,就做好了计算直方图的准备。你马上就会看到如何准备并启动直方图核函数。我们暂时假设已经在GPU上计算好了直方图。在计算完成后,需要将直方图复制回CPU,因此我们分配了一个包含256个元素的数组,并且执行从设备到主机的复制。
unsigned int histo[256];
HANDLE_ERROR(udaMemcpy(histo, dev_histo, 256 * sizeof(int),udaMemcpyDeviceToHost));此时,我们完成了直方图的计算,因此可以停止计时器并显示经历的时间。这与在前面几章中使用的计时代码基本相同。
//得到停止时间并显示计时结果
HANDLE_ERROR(udaEventRecord(stop,0));
HANDLE_ERROR(udaEventSynchronize(stop));
float elapsedTime;
HANDLE_ERROR(udaEventElapsedTime(& elapsedTime, start,stop));
printf("Time to generate: %3.1f ms\n", elapsedTime);此时,我们可以将直方图作为输入数据传递给算法的下一个步骤。然而,在这个示例中不需要将直方图用于其他任何操作,而只是验证在GPU上计算得到的直方图与在CPU上计算得到的直方图是否相同。首先,我们验证直方图的总和等于正确的值。这与CPU版本中的代码是相同的,如下所示:
long histoCount $= 0$
for (int $\mathrm{i} = 0$ .i<256; i++) { histoCount $+ =$ histo[i];
}
printf(“Histogram Sum: %ld\n”,histoCount);为了验证在GPU上计算得到的直方图是正确的,我们将使用CPU来计算同一个直方图。一种简单的方式是分配一个新的直方图数组,使用9.4.1节中的代码来计算输入数据,并且最后验证GPU直方图中的各个元素与CPU中各个元素的值相等。然而,我们在这个示例中并没有分配一个新的直方图数组,而是首先在GPU上计算直方图,然后以“逆序”方式在CPU上计算直方图。
以“逆序”方式计算直方图意味着,首先计算出GPU直方图,并在遍历每个数值时,递减直方图中相应元素的值。因此,如果完成计算时直方图中每个元素的值都为0,那么CPU计算的直方图与GPU计算的直方图相等。从某种意义上来看,我们是在计算这两个直方图之间的差异。这段代码看上去非常像CPU直方图计算,但使用的是递减运算符而不是递增运算符。
// 验证与CPU得到的是相同的计数值
for (int i=0; i<SIZE; i++)
histo[buffer[i]]--;
for (int i=0; i<256; i++) {
if (histo[i] != 0)
printf("Failure at %d!\n", i);
}和通常一样,在程序结束时要释放已分配的CUDA事件,GPU内存和主机内存。
HANDLE_ERROR(udaEventDestroy( start ) );
HANDLE_ERROR(udaEventDestroy( stop ) );
udaFree( dev_histo );cudaFree( dev_buffer ); free( buffer ); return 0; }之前,我们假设已经通过一个核函数计算好了直方图。出于性能的考虑,这个示例中的核函数调用比通常的核函数调用要更复杂一些。由于直方图包含了256个元素,因此可以在每个线程块中包含256个线程,这种方式不仅方便而且高效。但是,在线程块的数量上还可以有更多选择。例如,在100MB数据中共有104857600个字节。我们可以启动一个线程块,并且让每个线程处理409600个数据元素。同样,我们还可以启动409600个线程块,并且让每个线程处理一个数据元素。
你可能已经猜到了,最优的接近方案是在这两种极端情况之间。通过一些性能实验,我们发现当线程块的数量为GPU中处理器数量的2倍时,将达到最优性能。例如,在GeForce GTX 280中包含了30个处理器,因此当启动60个并行线程块时,直方图核函数将运行得最快。
在第3章中,我们曾介绍了一种方法来查询GPU硬件设备的各种属性。如果要基于当前的硬件平台来动态调整线程块的数量,那么就要用到其中一个设备属性。我们通过以下代码片段来实现这个操作。虽然还没有看到这个核函数的实现,但你应该能理解它要执行的任务。
cudaDeviceProp prop;
HANDLE_ERROR( CUDAGetDeviceProperties( &prop, 0 ) );
int blocks $=$ prop.MultiProcessorCount;
histo_kernel<<<blocks\*2,256>>>(dev_buffer,SIZE,dev_histo);综上所述,以下给出了完整的main()函数:
int main(void){ unsigned char \*buffer $=$ (unsigned char\*big_random_block(SIZE);udaEvent_t start,stop; HANDLE_ERROR(udaEventCreate(&start)); HANDLE_ERROR(udaEventCreate(&stop)); HANDLE_ERROR(udaEventRecord(start,0)); //在GPU上为文件的数据分配内存 unsigned char \*dev_buffer; unsigned int \*dev_histo; HANDLE_ERROR(udaMalloc((void\*\*)&dev_buffer,SIZE)); HANDLE_ERROR(udaMemcpy( dev_buffer, buffer, SIZE,udaMemcpyHostToDevice));HANDLE_ERROR(udaMalloc( (void\*\*)&dev_histo, 256\* sizeof(int)));
HANDLE_ERROR(udaMemset( dev_histo,0, 256\* sizeof(int)));
CUDADeviceProp prop;
HANDLE_ERROR(udaGetDeviceProperties( &prop,0)); int blocks $=$ prop.MultiProcessorCount; histo_kernel<<blocks\*2,256>>>(dev_buffer,SIZE,dev_histo); unsigned int histo[256];
HANDLE_ERROR(udaMemcpy( histo,dev_histo, 256\* sizeof(int),udaMemcpyDeviceToHost));//得到停止时间并显示计时结果
HANDLE_ERROR(udaEventRecord(stop,0));
HANDLE_ERROR(udaEventSynchronize(stop));
float elapsedTime;
HANDLE_ERROR(udaEventElapsedTime(& elapsedTime, start,stop));
printf("Time to generate: $\text{忍} 3 . 1 f$ ms\n", elapsedTime);
long histoCount $= 0$ ·
for(int $\mathrm{i = 0}$ ;i<256;i++){ histoCount $+ =$ histo[i];
}
printf(“Histogram Sum:%ld\n",histoCount);// 验证与基于CPU计算得到的结果是相同的
for (int i=0; i<SIZE; i++)
histo[buffer[i]]--;
for (int i=0; i<256; i++) {
if (histo[i] != 0)
printf("Failure at %d!\n", i);
}
HANDLE_ERROR(udaEventDestroy(start));
HANDLE_ERROR(udaEventDestroy(stop));
CUDAFree(dev_histo);
CUDAFree(dev_buffer);
free(buffer);
return 0;1. 使用全局内存原子操作的直方图核函数
现在来分析有趣的部分:在GPU上计算直方图的代码!计算直方图的核函数需要的参数包括,一个指向输入数组的指针,输入数组的长度,以及一个指向输出直方图的指针。核函数执行的第一个计算就是计算输入数据数组中的偏移。每个线程的起始偏移都是0到线程数量减1之间的某个值。然后,对偏移的增量为已启动线程的总数。我们希望你记住这项技术。当你第一次学习线程时,我们使用了相同的方法来将任意长度的矢量相加起来。
include"../common/book.h"
#defineSIZE (100\*1024\*1024)
__global__void histo_kernel( unsigned char \*buffer, long size, unsigned int \*histo){ int $\mathrm{i} =$ threadIdx.x $^+$ blockIdx.x \*blockDim.x; int stride $=$ blockDim.x \*gridDim.x;当每个线程知道它的起始偏移i以及递增的数量,这段代码将遍历输入数组,并递增直方图中相应元素的值。
while $(\mathrm{i} < \mathrm{size})$ { atomicAdd(&(histo[buffer[i]]),1); i+=stride; 1粗体代码行表示在CUDA C中使用原子操作的方式。函数调用atomicAdd( addr, y)将生成一个原子的操作序列,这个操作序列包括读取地址addr处的值,将y增加到这个值,以及将结果保存回地址addr。底层硬件将确保当执行这些操作时,其他任何线程都不会读取或写入地址addr上的值,这样就能确保得到预计的结果。在这里的示例中,这个地址就是直方图中相应元素的位置。如果当前字节为buffer[i],那么直方图中相应的元素就是histo[buffer[i]]。原子操作需要这个元素的地址,因此第一个参数为&(histo[buffer[i]])。由于我们只是想把这个元素中的值递增1,因此第二个参数就是1。
在分析完这些要点后,GPU版本的直方图计算就非常类似于CPU版本的直方图计算。
include"../common/book.h"
#defineSIZE (100\*1024\*1024) _global__void histo_kernel(unsigned char \*buffer, long size,unsigned int \*histo) { int i $=$ threadIdx.x $^+$ blockIdx.x \* blockDim.x; int stride $=$ blockDim.x \* gridDim.x; while (i $<$ size) { atomicAdd( &histo[buffer[i]]),1); i $+ =$ stride; }然而,我们现在还不要高兴得太早。在运行这个示例时,我们发现在 GeForce GTX 285 的测试机器上,从 100MB 的输入数据中构造直方图需要 1.752 秒。与基于 CPU 的直方图计算相比,你会发现这个性能居然更糟糕。事实上,GPU 版本的性能比 CPU 版本的性能要慢四倍,这就是我们为什么要设置一个基线性能标准。如果只是因为程序能在 GPU 上运行而就对这种低性能的实现感到满足,那么我们应该感到惭愧。
由于在核函数中只包含了非常少的计算工作,因此很可能是全局内存上的原子操作导致了性能的降低。当数千个线程尝试访问少量的内存位置时,将发生大量的竞争。为了确保递增操作的原子性,对相同内存位置的操作都将被硬件串行化。这可能导致保存未完成操作的队列非常长,因此会抵消通过并行运行线程而获得的性能提升。我们需要改进算法本身从而重新获得这种性能。
2. 使用共享内存原子操作和全局内存原子操作的直方图核函数
尽管这些原子操作是导致这种性能降低的原因,但解决这个问题的方法却出乎意料地需要使用更多而非更少的原子操作。这里的主要问题并非在于使用了过多的原子操作,而是有数千个线程在少量的内存地址上发生竞争。要解决这个问题,我们将直方图计算分为两个阶段。
在第一个阶段中,每个并行线程块将计算它所处理数据的直方图。由于每个线程块在执行这个操作时都是相互独立的,因此可以在共享内存中计算这些直方图,这将避免每次将写入操作从芯片发送到DRAM。但是,这种方式仍然需要原子操作,因为在线程块中的多个线程之间仍然会处理相同值的数据元素。然而,现在只有256个线程在256个地址上发生竞争,这将极大地减少在使用全局内存时在数千个线程之间发生竞争的情况。
然后,在第一个阶段中分配一个共享内存缓冲区并进行初始化,用来保存每个线程块的临时直方图。回顾第5章,由于随后的步骤将包括读取和修改这个缓冲区,因此需要调用__syncthreads()来确保每个线程的写入操作在线程继续前进之前完成。
__global__void histo_kernel( unsigned char \*buffer, long size, unsigned int \*histo) { __shared__ unsigned int temp[256];temp[threadIdx.x] = 0;
__syncthreads();在将直方图初始化为0后,下一个步骤与最初GPU版本的直方图计算非常类似。这里唯一的差异在于,我们使用了共享内存缓冲区temp[]而不是全局内存缓冲区histo[],并且需要随后调用__syncthreads()来确保提交最后的写入操作。
int i = threadIdx.x + blockIdx.x * blockDim.x;
int offset = blockDim.x * gridDim.x;
while (i < size) {
atomicAdd( &temp[buffer[i]], 1);
i += offset;
}
__syncthreads();在修改后的直方图示例程序中,最后一步要求将每个线程块的临时直方图合并到全局缓冲区histo[]中。假设将输入数据分为两半,这样就有两个线程查看不同部分的数据,并计算得到两个独立的直方图。如果线程A在输入数据中发现字节0xFC出现了20次,线程B发现字节0xFC出现了5次,那么字节0xFC在输入数据中共出现了25次。同样,最终直方图的每个元素只是线程A直方图中相应元素和线程B直方图中相应元素的加和。这个逻辑可以扩展到任意数量的线程,因此将每个线程块的直方图合并为单个最终的直方图就是,将线程块的直方图的每个元素都相加到最终直方图中相应位置的元素上。这个操作需要自动完成:
atomicAdd( & (histo[threadIdx.x]), temp[threadIdx.x]); }由于我们使用了256个线程,并且直方图中包含了256个元素,因此每个线程将自动把它计算得到的元素只增加到最终直方图的元素上。如果线程数量不等于元素数量,那么这个阶段将更为复杂。注意,我们并不保证线程块将按照何种顺序将各自的值相加到最终直方图中,但由于整数加法是可交换的,无论哪种顺序都会得到相同的结果。
这就是我们的两阶段直方图计算核函数,以下是完整的代码:
__global__void histo_kernel( unsigned char \*buffer, long size, unsigned int \*histo) { __shared__ unsigned int temp[256]; temp[threadIdx.x] $= 0$ _syncthreads(); int i $=$ threadIdx.x $^+$ blockIdx.x \*blockDim.x; int offset $=$ blockDim.x \*gridDim.x; while (i $<$ size) {atomicAdd(&temp(buffer[i]), l);
i += offset;
}
__syncthreads();
atomicAdd&(histo(threadIdx.x), temp(threadIdx.x);这个直方图示例比之前的GPU版本在性能上有了极大的提升。通过使用共享内存,程序在 GeForce GTX 285上的执行时间为0.057秒。这不仅比单纯使用全局内存原子操作的版本要好很多,而且比最初CPU实现也要高一个数量级(从0.416秒提升到0.057秒),大约提升了7倍多。因此,尽管在最初将这个直方图修改为在GPU上实现反而使性能下降,但如果同时使用了共享原子操作和全局原子性,那么仍然能实现性能的提升。