54.1_什么是Dropout
54.1 什么是Dropout
Dropout是一种通过随机删除(禁用)神经元进行训练的方法。模型在训练时随机选择隐藏层的神经元,并删除选中的神经元。如图54-1所示,被删除的神经元不传递任何信号。
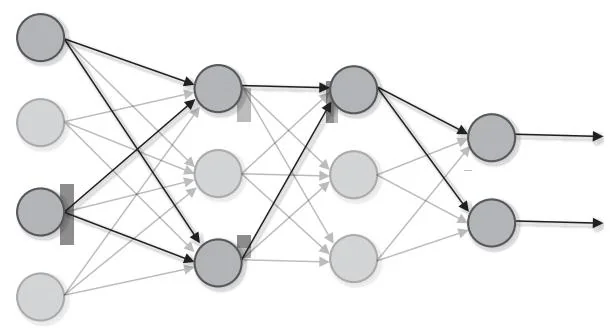
图54-1 Dropout在训练时的行为
在使用Dropout训练时,每当有数据流过,它都会随机选择要删除的神经元。假设有一个由10个神经元组成的层,我们想通过该层后面的Dropout层随机删除 的神经元。这时可以编写如下代码。
import numpy as np
dropout_ratio $= 0.6$ $\mathbf{x} = \mathbf{np}$ .ones(10)
mask $=$ np.random.randint(10) $>$ dropout_ratio
y $=$ x\*mask代码中的mask是元素为True或False的数组。mask的创建方法为首先用np.random.randint(10)生成10个 的随机值,然后将这些值与dropout_ratio 进行比较,只有大于dropout_ratio的元素会转换为True,其余的元素变为False。这个例子创建的是False所占比例为 的mask。
创建mask后,运行 。这会使与mask的False相对应的x的元素变为0(即删除它们)。结果导致平均每次只有4个神经元的输出被传递到下一层。在训练期间,每次传递数据时,Dropout层都会做上面的处理。

在机器学习中,我们经常使用集成学习(ensemble learning)。集成学习是单独训练多个模型,在推理时对多个模型的输出取平均值的方法。以神经网络为例,我们可以准备5个具有相同(或类似)结构的网络,并单独训练每个网络,然后在测试时将5个输出的平均值作为答案。经过实验发现,这种做法可以使神经网络的识别精度提高几个百分点。集成学习与Dropout相似。之所以这么说,是因为Dropout在训练时会随机删除神经元,这可以解释为每次都在训练不同的模型。换言之,我们可以把Dropout当作一种在一个网络上达到与集成学习相同效果的伪实现。
上面的代码是Dropout在训练时所做的处理。而在测试时,模型需要使用所有的神经元,“模仿”训练时集成学习的行为。这可以通过使用所有的神经元计算输出,然后“弱化”其输出来实现。弱化的比例是在训练时幸存下来的神经元的比例。具体代码如下所示。
# 训练时
mask = np.random.randint(*x.shape) > dropout_ratio
y = x * mask测试时
scale = 1 - dropout_ratio
y = x * scale上面的代码在测试时的转换比例为 scale。用具体数字来说,就是平均有 的神经元在训练时存活。考虑到这一点,测试时要使用所有的神经元进行计算,然后将输出乘以0.4。这样就可以使训练和测试在缩放幅度上保持一致。
以上是“常规的Dropout”。之所以说它是“常规的”,是因为Dropout还有其他的实现方式,这种实现方式叫作Inverted Dropout(反向Dropout)。接下来笔者将介绍Inverted Dropout。为了加以区分,今后我们将此前介绍的Dropout称为Direct Dropout(直接Dropout)。