0x45_点分治
0x45点分治
到目前为止,我们用数据结构处理的大多是序列上的问题。这些问题的形式一般是给定序列中的两个位置 和 ,在区间 上执行查询或修改指令。如果给定一棵树,以及树上两个节点 和 ,那么与“序列上的区间”相对应的就是“树上两点之间的路径”。我们先不考虑对路径进行修改的操作。本节中介绍的点分治就是在一棵树上,对具有某些限定条件的路径静态地进行统计的算法。
【例题】Tree FOJ1741
给一棵有 个点的树,每条边都有一个权值。树上两个节点 与 之间的路径长度就是路径上各条边的权值之和。求长度不超过 的路径有多少条。
本题树中的边是无向的,即这棵树是一个由 个点、 条边构成的无向连通图。我们把这种树称为“无根树”,也就是说可以任意指定一个节点为根节点,而不影响问题的答案。
若指定节点 为根,则对 而言,树上的路径可以分为两类:
经过根节点 。
包含于 的某一棵子树中(不经过根节点)。
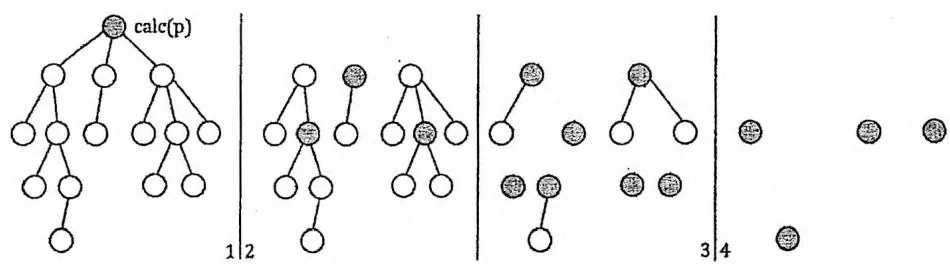
根据分治的思想,对于第2类路径,显然可以把 的每棵子树作为子问题,递归进行处理。
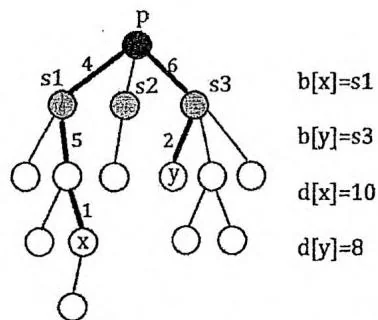
而对于第1类路径,可以从根节点 分成“ ”与“ ”两段。回顾在0x21节所学的知识,我们可以从 出发对整棵树进行DFS,求出数组 ,其中 表示点 到根节点 的距离。同时还可以求出数组 ,其中 表示点 属于根节点 的哪一棵子树,特别地,令 。
此时满足题目要求的第1类路径就是满足以下两个条件的点对 的个数:
如下图所示。
定义 表示在以 为根的树中统计上述点对的个数(第1类路径的条数)。 有两种常见的实现方式。针对不同的题目,二者各有优劣。
方法一:树上直接统计
设 的子树为 。
对于 中的每个节点 ,把在子树 中的满足 的节点 的个数累加到答案中即可。
具体来说,可以建立一个树状数组,依次处理每棵子树 。
对 中的每个节点 ,查询前缀和 ,即为所求的 的个数。
对 中的每个节点 , 执行 , 表示与 距离为 的节点增加了 1 个。
按子树一棵棵进行处理保证了 ,查询前缀和保证了 。
需要注意的是,树状数组的范围与路径长度有关,这个范围远比 要大。而本题中不易进行离散化。一种解决方案是用平衡树代替树状数组,以保证 的复杂度,但代码复杂程度显著增加。所以本题更适用下一种方法。
方法二:指针扫描数组
把树中每个点放进一个数组 ,并把数组 按照节点的 值排序。
使用两个指针 分别从前、后开始扫描 数组。
容易发现,在指针 从左向右扫描的过程中,恰好使得 的指针 的范围是从右向左单调递减的。
另外,我们用数组 维护在 与 之间满足 的位置 的个数。
于是,当路径的一端 等于 时,满足题目要求的路径另一端 的个数就是 。
总而言之,整个点分治算法的过程就是:
任选一个根节点 (后面我们将说明, 应该取树的重心)。
从 出发进行一次 DFS,求出 数组和 数组。
执行 。
删除根节点 ,对 的每棵子树(看作无根树)递归执行 1~4 步。
在点分治过程中,每一层的所有递归过程合计对每个节点处理1次。因此,若递归最深到达第 层,则整个算法的时间复杂度就是 。
如果问题中的树是一条链,最坏情况下每次都以链的一端为根,那么点分治将需要递归 层,时间复杂度退化到 。为了避免这种情况,我们每次选择树的重心(曾在0x21节中提及)作为根节点 。此时容易证明 的每棵子树的大小都不会超过整棵树大小的一半,点分治就至多递归 层,整个算法的时间复杂度为 。如下图所示。