7.4_TD_learning_of_optimal_action_values_Q-learning
7.4 TD learning of optimal action values: Q-learning
In this section, we introduce the Q-learning algorithm, one of the most classic reinforcement learning algorithms [38,39]. Recall that Sarsa can only estimate the action values of a given policy, and it must be combined with a policy improvement step to find optimal policies. By contrast, Q-learning can directly estimate optimal action values and find optimal policies.
7.4.1 Algorithm description
The Q-learning algorithm is
where . Here, is the estimate of the optimal action value of and is the learning rate for .
The expression of Q-learning is similar to that of Sarsa. They are different only in terms of their TD targets: the TD target of Q-learning is , whereas that of Sarsa is . Moreover, given , Sarsa requires in every iteration, whereas Q-learning merely requires .
Why is Q-learning designed as the expression in (7.18), and what does it do mathematically? Q-learning is a stochastic approximation algorithm for solving the following equation:
This is the Bellman optimality equation expressed in terms of action values. The proof is given in Box 7.5. The convergence analysis of Q-learning is similar to Theorem 7.1 and omitted here. More information can be found in [32, 39].
Box 7.5: Showing that (7.19) is the Bellman optimality equation
By the definition of expectation, (7.19) can be rewritten as
Taking the maximum of both sides of the equation gives
By denoting , we can rewrite the above equation as
which is clearly the Bellman optimality equation in terms of state values as introduced in Chapter 3.
7.4.2 Off-policy vs on-policy
We next introduce two important concepts: on-policy learning and off-policy learning. What makes Q-learning slightly special compared to the other TD algorithms is that Q-learning is off-policy while the others are on-policy.
Two policies exist in any reinforcement learning task: a behavior policy and a target policy. The behavior policy is the one used to generate experience samples. The target policy is the one that is constantly updated to converge to an optimal policy. When the behavior policy is the same as the target policy, such a learning process is called on-policy. Otherwise, when they are different, the learning process is called off-policy.
The advantage of off-policy learning is that it can learn optimal policies based on the experience samples generated by other policies, which may be, for example, a policy executed by a human operator. As an important case, the behavior policy can be selected to be exploratory. For example, if we would like to estimate the action values of all state-action pairs, we must generate episodes visiting every state-action pair sufficiently many times. Although Sarsa uses -greedy policies to maintain certain exploration abilities, the value of is usually small and hence the exploration ability is limited. By contrast, if we can use a policy with a strong exploration ability to generate episodes and then use off-policy learning to learn optimal policies, the learning efficiency would be significantly increased.
To determine if an algorithm is on-policy or off-policy, we can examine two aspects. The first is the mathematical problem that the algorithm aims to solve. The second is the experience samples required by the algorithm.
Sarsa is on-policy.
The reason is as follows. Sarsa has two steps in every iteration. The first step is to evaluate a policy by solving its Bellman equation. To do that, we need samples generated by . Therefore, is the behavior policy. The second step is to obtain an improved policy based on the estimated values of . As a result, is the target policy that is constantly updated and eventually converges to an optimal policy. Therefore, the behavior policy and the target policy are the same.
From another point of view, we can examine the samples required by the algorithm. The samples required by Sarsa in every iteration include . How these samples are generated is illustrated below:
As can be seen, the behavior policy is the one that generates at and at . The Sarsa algorithm aims to estimate the action value of of a policy denoted as , which is the target policy because it is improved in every iteration based on the estimated values. In fact, is the same as because the evaluation of relies on the samples , where is generated following . In other words, the policy that Sarsa evaluates is the policy used to generate samples.
Q-learning is off-policy.
The fundamental reason is that Q-learning is an algorithm for solving the Bellman optimality equation, whereas Sarsa is for solving the Bellman equation of a given policy. While solving the Bellman equation can evaluate the associated policy, solving the Bellman optimality equation can directly generate the optimal values and optimal policies.
In particular, the samples required by Q-learning in every iteration is . How these samples are generated is illustrated below:
As can be seen, the behavior policy is the one that generates at . The Q-learning algorithm aims to estimate the optimal action value of . This estimation process relies on the samples . The process of generating does not involve because it is governed by the system model (or by interacting with the environment). Therefore, the estimation of the optimal action value of does not involve and we can use any to generate at . Moreover, the target policy here is the greedy policy obtained based on the estimated optimal values (Algorithm 7.3). The behavior policy does not have to be the same as .
MC learning is on-policy. The reason is similar to that of Sarsa. The target policy to be evaluated and improved is the same as the behavior policy that generates samples.
Another concept that may be confused with on-policy/off-policy is online/offline. Online learning refers to the case where the agent updates the values and policies while interacting with the environment. Offline learning refers to the case where the agent updates the values and policies using pre-collected experience data without interacting with the environment. If an algorithm is on-policy, then it can be implemented in an online fashion, but cannot use pre-collected data generated by other policies. If an algorithm is off-policy, then it can be implemented in either an online or offline fashion.
Algorithm 7.2: Optimal policy learning via Q-learning (on-policy version)
Initialization: for all and all . . Initial for all . Initial -greedy policy derived from .
Goal: Learn an optimal path that can lead the agent to the target state from an initial state .
For each episode, do
If ( ) is not the target state, do
Collect the experience sample given : generate following ; generate by interacting with the environment.
Update -value for :
Update policy for :
Algorithm 7.3: Optimal policy learning via Q-learning (off-policy version)
Initialization: Initial guess for all . Behavior policy for all . for all and all .
Goal: Learn an optimal target policy for all states from the experience samples generated by .
For each episode generated by , do
For each step of the episode, do
Update -value for :
Update target policy for :
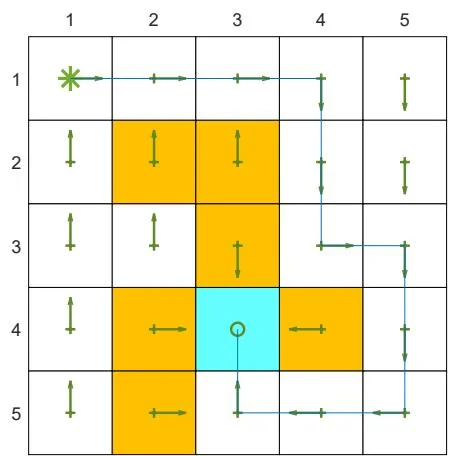
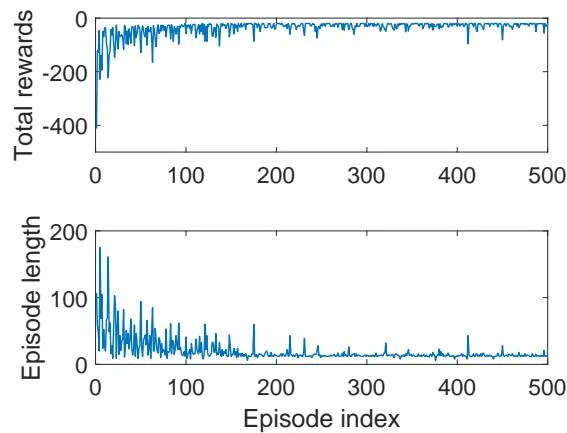
Figure 7.3: An example for demonstrating Q-learning. All the episodes start from the top-left state and terminate after reaching the target state. The aim is to find an optimal path from the starting state to the target state. The reward settings are , , and . The learning rate is and the value of is 0.1. The left figure shows the final policy obtained by the algorithm. The right figure shows the total reward and length of every episode.
7.4.3 Implementation
Since Q-learning is off-policy, it can be implemented in either an on-policy or off-policy fashion.
The on-policy version of Q-learning is shown in Algorithm 7.2. This implementation is similar to the Sarsa one in Algorithm 7.1. Here, the behavior policy is the same as the target policy, which is an -greedy policy.
The off-policy version is shown in Algorithm 7.3. The behavior policy can be any policy as long as it can generate sufficient experience samples. It is usually favorable when is exploratory. Here, the target policy is greedy rather than -greedy since it is not used to generate samples and hence is not required to be exploratory. Moreover, the off-policy version of Q-learning presented here is implemented offline: all the experience samples are collected first and then processed.
7.4.4 Illustrative examples
We next present examples to demonstrate Q-learning.
The first example is shown in Figure 7.3. It demonstrates on-policy Q-learning. The goal here is to find an optimal path from a starting state to the target state. The setup is given in the caption of Figure 7.3. As can be seen, Q-learning can eventually find an optimal path. During the learning process, the length of each episode decreases, whereas the total reward of each episode increases.
The second set of examples is shown in Figure 7.4 and Figure 7.5. They demonstrate off-policy Q-learning. The goal here is to find an optimal policy for all the states. The reward setting is , and . The discount rate is . The learning rate is .
Ground truth: To verify the effectiveness of Q-learning, we first need to know the ground truth of the optimal policies and optimal state values. Here, the ground truth is obtained by the model-based policy iteration algorithm. The ground truth is given in Figures 7.4(a) and (b).
Experience samples: The behavior policy has a uniform distribution: the probability of taking any action at any state is 0.2 (Figure 7.4(c)). A single episode with 100,000 steps is generated (Figure 7.4(d)). Due to the good exploration ability of the behavior policy, the episode visits every state-action pair many times.
Learned results: Based on the episode generated by the behavior policy, the final target policy learned by Q-learning is shown in Figure 7.4(e). This policy is optimal because the estimated state value error (root-mean-square error) converges to zero as shown in Figure 7.4(f). In addition, one may notice that the learned optimal policy is not exactly the same as that in Figure 7.4(a). In fact, there exist multiple optimal policies that have the same optimal state values.
Different initial values: Since Q-learning bootstraps, the performance of the algorithm depends on the initial guess for the action values. As shown in Figure 7.4(g), when the initial guess is close to the true value, the estimate converges within approximately 10,000 steps. Otherwise, the convergence requires more steps (Figure 7.4(h)). Nevertheless, these figures demonstrate that Q-learning can still converge rapidly even though the initial value is not accurate.
Different behavior policies: When the behavior policy is not exploratory, the learning performance drops significantly. For example, consider the behavior policies shown in Figure 7.5. They are -greedy policies with or 0.1 (the uniform policy in Figure 7.4(c) can be viewed as -greedy with ). It is shown that, when decreases from 1 to 0.5 and then to 0.1, the learning speed drops significantly. That is because the exploration ability of the policy is weak and hence the experience samples are insufficient.