1.7_Markov_decision_processes
1.7 Markov decision processes
The previous sections of this chapter illustrated some fundamental concepts in reinforcement learning through examples. This section presents these concepts in a more formal way under the framework of Markov decision processes (MDPs).
An MDP is a general framework for describing stochastic dynamical systems. The key ingredients of an MDP are listed below.
Sets:
State space: the set of all states, denoted as .
Action space: a set of actions, denoted as , associated with each state .
Reward set: a set of rewards, denoted as , associated with each state-action pair .
Model:
State transition probability: In state , when taking action , the probability of transitioning to state is . It holds that for any .
Reward probability: In state , when taking action , the probability of obtaining reward is . It holds that for any .
Policy: In state , the probability of choosing action is . It holds that for any .
Markov property: The Markov property refers to the memoryless property of a stochastic process. Mathematically, it means that
where represents the current time step and represents the next time step. Equation (1.4) indicates that the next state or reward depends merely on the current state and action and is independent of the previous ones. The Markov property is important for deriving the fundamental Bellman equation of MDPs, as shown in the next chapter.
Here, and for all are called the model or dynamics. The model can be either stationary or nonstationary (or in other words, time-invariant or time-variant). A stationary model does not change over time; a nonstationary model may vary over time. For instance, in the grid world example, if a forbidden area may pop up or disappear sometimes, the model is nonstationary. In this book, we only consider stationary models.
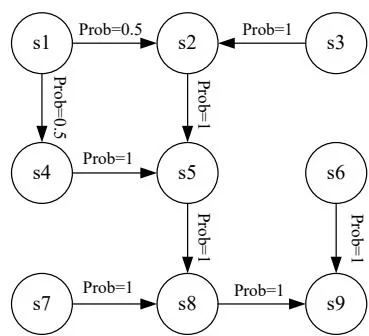
One may have heard about the Markov processes (MPs). What is the difference between an MDP and an MP? The answer is that, once the policy in an MDP is fixed, the MDP degenerates into an MP. For example, the grid world example in Figure 1.7 can be abstracted as a Markov process. In the literature on stochastic processes, a Markov process is also called a Markov chain if it is a discrete-time process and the number of states is finite or countable [1]. In this book, the terms "Markov process" and "Markov chain" are used interchangeably when the context is clear. Moreover, this book mainly considers finite MDPs where the numbers of states and actions are finite. This is the simplest case that should be fully understood.
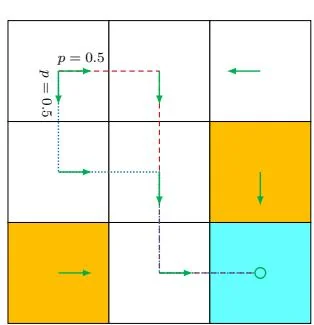
Figure 1.7: Abstraction of the grid world example as a Markov process. Here, the circles represent states and the links with arrows represent state transitions.
Finally, reinforcement learning can be described as an agent-environment interaction process. The agent is a decision-maker that can sense its state, maintain policies, and execute actions. Everything outside of the agent is regarded as the environment. In the grid world examples, the agent and environment correspond to the robot and grid world, respectively. After the agent decides to take an action, the actuator executes such a decision. Then, the state of the agent would be changed and a reward can be obtained. By using interpreters, the agent can interpret the new state and the reward. Thus, a closed loop can be formed.