We next introduce a more general algorithm called truncated policy iteration. We will see that the value iteration and policy iteration algorithms are two special cases of the truncated policy iteration algorithm.
4.3.1 Comparing value iteration and policy iteration
First of all, we compare the value iteration and policy iteration algorithms by listing their steps as follows.
⋄ Policy iteration: Select an arbitrary initial policy π0 . In the k th iteration, do the following two steps.
Step 1: Policy evaluation (PE). Given πk , solve vπk from
vπk=rπk+γPπkvπk.
Step 2: Policy improvement (PI). Given vπk , solve πk+1 from
πk+1=argπmax(rπ+γPπvπk).
⋄ Value iteration: Select an arbitrary initial value v0 . In the k th iteration, do the following two steps.
Step 1: Policy update (PU). Given vk , solve πk+1 from
πk+1=argπmax(rπ+γPπvk).
Step 2: Value update (VU). Given πk+1 , solve vk+1 from
vk+1=rπk+1+γPπk+1vk.
The above steps of the two algorithms can be illustrated as
Value iteration: v0PUπ1′VUv1PUπ2′VUv2PU…
It can be seen that the procedures of the two algorithms are very similar.
We examine their value steps more closely to see the difference between the two algorithms. In particular, let both algorithms start from the same initial condition: v0=vπ0 . The procedures of the two algorithms are listed in Table 4.6. In the first three steps, the two algorithms generate the same results since v0=vπ0 . They become
Table 4.6: A comparison between the implementation steps of policy iteration and value iteration.
different in the fourth step. During the fourth step, the value iteration algorithm executes v1=rπ1+γPπ1v0 , which is a one-step calculation, whereas the policy iteration algorithm solves vπ1=rπ1+γPπ1vπ1 , which requires an infinite number of iterations. If we explicitly write out the iterative process for solving vπ1=rπ1+γPπ1vπ1 in the fourth step, everything becomes clear. By letting vπ1(0)=v0 , we have
The following observations can be obtained from the above process.
If the iteration is run only once, then vπ1(1) is actually v1 , as calculated in the value iteration algorithm. If the iteration is run an infinite number of times, then vπ1(∞) is actually vπ1 , as calculated in the policy iteration algorithm. If the iteration is run a finite number of times (denoted as jtruncated ), then such an algorithm is called truncated policy iteration. It is called truncated because the remaining iterations from jtruncated to ∞ are truncated.
As a result, the value iteration and policy iteration algorithms can be viewed as two extreme cases of the truncated policy iteration algorithm: value iteration terminates
Algorithm 4.3: Truncated policy iteration algorithm Initialization: The probability models p(r∣s,a) and p(s′∣s,a) for all (s,a) are known. Initial guess π0 . Goal: Search for the optimal state value and an optimal policy. While vk has not converged, for the k th iteration, do Policy evaluation: Initialization: select the initial guess as vk(0)=vk−1 . The maximum number of iterations is set as jtruncated . While j<jtruncated , do For every state s∈S , do vk(j+1)(s)=∑aπk(a∣s)[∑rp(r∣s,a)r+γ∑s′p(s′∣s,a)vk(j)(s′)] Set vk=vk(jtruncated) Policy improvement: For every state s∈S , do For every action a∈A(s) , do qk(s,a)=∑rp(r∣s,a)r+γ∑s′p(s′∣s,a)vk(s′)ak∗(s)=argmaxaqk(s,a)πk+1(a∣s)=1 if a=ak∗ , and πk+1(a∣s)=0 otherwise
at jtruncate=1 , and policy iteration terminates at jtruncate=∞ . It should be noted that, although the above comparison is illustrative, it is based on the condition that vπ1(0)=v0=vπ0 . The two algorithms cannot be directly compared without this condition.
4.3.2 Truncated policy iteration algorithm
In a nutshell, the truncated policy iteration algorithm is the same as the policy iteration algorithm except that it merely runs a finite number of iterations in the policy evaluation step. Its implementation details are summarized in Algorithm 4.3. It is notable that vk and vk(j) in the algorithm are not state values. Instead, they are approximations of the true state values because only a finite number of iterations are executed in the policy evaluation step.
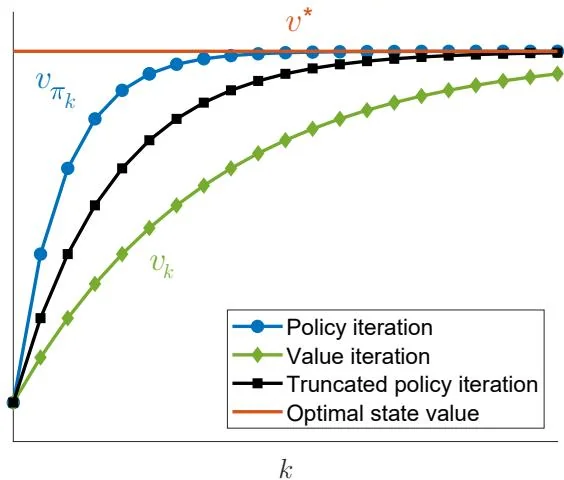
If vk does not equal vπk , will the algorithm still be able to find optimal policies? The answer is yes. Intuitively, truncated policy iteration is in between value iteration and policy iteration. On the one hand, it converges faster than the value iteration algorithm because it computes more than one iteration during the policy evaluation step. On the other hand, it converges slower than the policy iteration algorithm because it only computes a finite number of iterations. This intuition is illustrated in Figure 4.5. Such intuition is also supported by the following analysis.
Proposition 4.1 (Value improvement). Consider the iterative algorithm in the policy
Figure 4.5: An illustration of the relationships between the value iteration, policy iteration, and truncated policy iteration algorithms.
evaluation step:
vπk(j+1)=rπk+γPπkvπk(j),j=0,1,2,…
If the initial guess is selected as vπk(0)=vπk−1 , it holds that
vπk(j+1)≥vπk(j)
for j=0,1,2,…
Box 4.3: Proof of Proposition 4.1
First, since vπk(j)=rπk+γPπkvπk(j−1) and vπk(j+1)=rπk+γPπkvπk(j) , we have
where the inequality is due to πk=argmaxπ(rπ+γPπvπk−1) . Substituting vπk(1)≥vπk(0) into (4.5) yields vπk(j+1)≥vπk(j) .
Notably, Proposition 4.1 requires the assumption that vπk(0)=vπk−1 . However, vπk−1 is unavailable in practice, and only vk−1 is available. Nevertheless, Proposition 4.1 still sheds light on the convergence of the truncated policy iteration algorithm. A more in-depth discussion of this topic can be found in [2, Section 6.5].
Up to now, the advantages of truncated policy iteration are clear. Compared to the
policy iteration algorithm, the truncated one merely requires a finite number of iterations in the policy evaluation step and hence is more computationally efficient. Compared to value iteration, the truncated policy iteration algorithm can speed up its convergence rate by running for a few more iterations in the policy evaluation step.