The policy gradient methods that we have studied so far, including REINFORCE, QAC, and A2C, are all on-policy. The reason for this can be seen from the expression of the true gradient:
To use samples to approximate this true gradient, we must generate the action samples by following π(θ) . Hence, π(θ) is the behavior policy. Since π(θ) is also the target policy that we aim to improve, the policy gradient methods are on-policy.
In the case that we already have some samples generated by a given behavior policy, the policy gradient methods can still be applied to utilize these samples. To do that, we can employ a technique called importance sampling. It is worth mentioning that the importance sampling technique is not restricted to the field of reinforcement learning. It is a general technique for estimating expected values defined over one probability distribution using some samples drawn from another distribution.
10.3.1 Importance sampling
We next introduce the importance sampling technique. Consider a random variable X∈X . Suppose that p0(X) is a probability distribution. Our goal is to estimate EX∼p0[X] . Suppose that we have some i.i.d. samples {xi}i=1n .
⋄ First, if the samples {xi}i=1n are generated by following p0 , then the average value xˉ=n1∑i=1nxi can be used to approximate EX∼p0[X] because xˉ is an unbiased estimate of EX∼p0[X] and the estimation variance converges to zero as n→∞ (see the law of large numbers in Box 5.1 for more information). ⋄ Second, consider a new scenario where the samples {xi}i=1n are not generated by p0 . Instead, they are generated by another distribution p1 . Can we still use these samples to approximate EX∼p0[X] ? The answer is yes. However, we can no longer use xˉ=n1∑i=1nxi to approximate EX∼p0[X] since xˉ≈EX∼p1[X] rather than EX∼p0[X] .
In the second scenario, EX∼p0[X] can be approximated based on the importance sampling technique. In particular, EX∼p0[X] satisfies
Thus, estimating EX∼p0[X] becomes the problem of estimating EX∼p1[f(X)] . Let
fˉ≐n1i=1∑nf(xi).
Since fˉ can effectively approximate EX∼p1[f(X)] , it then follows from (10.9) that
EX∼p0[X]=EX∼p1[f(X)]≈fˉ=n1i=1∑nf(xi)=n1i=1∑ni m p o r t a n c ep1(xi)p0(xi)xi.(10.10)
Equation (10.10) suggests that EX∼p0[X] can be approximated by a weighted average of xi . Here, p1(xi)p0(xi) is called the importance weight. When p1=p0 , the importance weight is 1 and fˉ becomes xˉ . When p0(xi)≥p1(xi) , xi can be sampled more frequently by p0 but less frequently by p1 . In this case, the importance weight, which is greater than one, emphasizes the importance of this sample.
Some readers may ask the following question: while p0(x) is required in (10.10), why do we not directly calculate EX∼p0[X] using its definition EX∼p0[X]=∑x∈Xp0(x)x ? The answer is as follows. To use the definition, we need to know either the analytical expression of p0 or the value of p0(x) for every x∈X . However, it is difficult to obtain the analytical expression of p0 when the distribution is represented by, for example, a neural network. It is also difficult to obtain the value of p0(x) for every x∈X when X is large. By contrast, (10.10) merely requires the values of p0(xi) for some samples and is much easier to implement in practice.
An illustrative example
We next present an example to demonstrate the importance sampling technique. Consider X∈X≐{+1,−1} . Suppose that p0 is a probability distribution satisfying
p0(X=+1)=0.5,p0(X=−1)=0.5.
The expectation of X over p0 is
EX∼p0[X]=(+1)⋅0.5+(−1)⋅0.5=0.
Suppose that p1 is another distribution satisfying
p1(X=+1)=0.8,p1(X=−1)=0.2.
The expectation of X over p1 is
EX∼p1[X]=(+1)⋅0.8+(−1)⋅0.2=0.6.
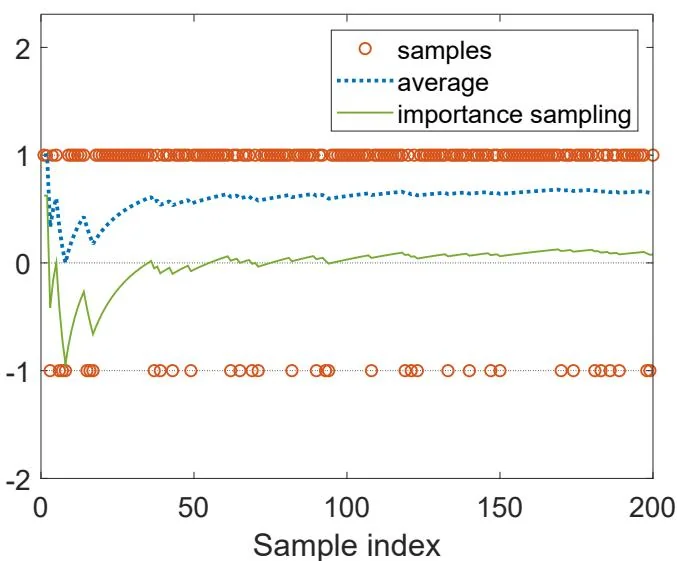
Suppose that we have some samples {xi} drawn over p1 . Our goal is to estimate EX∼p0[X] using these samples. As shown in Figure 10.2, there are more samples of +1 than −1 . That is because p1(X=+1)=0.8>p1(X=−1)=0.2 . If we directly calculate the average value ∑i=1nxi/n of the samples, this value converges to EX∼p1[X]=0.6 (see the dotted line in Figure 10.2). By contrast, if we calculate the weighted average value as in (10.10), this value can successfully converge to EX∼p0[X]=0 (see the solid line in Figure 10.2).
Figure 10.2: An example for demonstrating the importance sampling technique. Here, X∈{+1,−1} and p0(X=+1)=p0(X=−1)=0.5 . The samples are generated according to p1 where p1(X=+1)=0.8 and p1(X=−1)=0.2 . The average of the samples converges to EX∼p1[X]=0.6 , but the weighted average calculated by the importance sampling technique in (10.10) converges to EX∼p0[X]=0 .
Finally, the distribution p1 , which is used to generate samples, must satisfy that p1(x)=0 when p0(x)=0 . If p1(x)=0 while p0(x)=0 , the estimation result may be problematic. For example, if
p1(X=+1)=1,p1(X=−1)=0,
then the samples generated by p1 are all positive: {xi}={+1,+1,…,+1} . These samples cannot be used to correctly estimate EX∼p0[X]=0 because
With the importance sampling technique, we are ready to present the off-policy policy gradient theorem. Suppose that β is a behavior policy. Our goal is to use the samples generated by β to learn a target policy π that can maximize the following metric:
J(θ)=s∈S∑dβ(s)vπ(s)=ES∼dβ[vπ(S)],
where dβ is the stationary distribution under policy β and vπ is the state value under policy π . The gradient of this metric is given in the following theorem.
Theorem 10.1 (Off-policy policy gradient theorem). In the discounted case where γ∈(0,1) , the gradient of J(θ) is
∇θJ(θ)=ES∼ρ,A∼βi m p o r t a n c eβ(A∣S)π(A∣S,θ)∇θlnπ(A∣S,θ)qπ(S,A),(10.11)
where the state distribution ρ is
ρ(s)≐s′∈S∑dβ(s′)πPr(s∣s′),s∈S,
where Prπ(s∣s′)=∑k=0∞γk[Pπk]s′s=[(I−γPπ)−1]s′s is the discounted total probability of transitioning from s′ to s under policy π .
The gradient in (10.11) is similar to that in the on-policy case in Theorem 9.1, but there are two differences. The first difference is the importance weight. The second difference is that A∼β instead of A∼π . Therefore, we can use the action samples
generated by following β to approximate the true gradient. The proof of the theorem is given in Box 10.2.
Box 10.2: Proof of Theorem 10.1
Since dβ is independent of θ , the gradient of J(θ) satisfies
where Prπ(s′∣s)≐∑k=0∞γk[Pπk]ss′=[(In−γPπ)−1]ss′ . Substituting (10.13) into (10.12) yields
∇θJ(θ)=∑s∈Sdβ(s)∇θvπ(s)=∑s∈Sdβ(s)∑s′∈SPrπ(s′∣s)∑a∈A∇θπ(a∣s′,θ)qπ(s′,a)=∑s′∈S(∑s∈Sdβ(s)Prπ(s′∣s))∑a∈A∇θπ(a∣s′,θ)qπ(s′,a)=˙∑s′∈Sρ(s′)∑a∈A∇θπ(a∣s′,θ)qπ(s′,a)=∑s∈Sρ(s)∑a∈A∇θπ(a∣s,θ)qπ(s,a)(c h a n g es′t os)=ES∼ρ[∑a∈A∇θπ(a∣S,θ)qπ(S,a)].
By using the importance sampling technique, the above equation can be further rewritten as
The proof is complete. The above proof is similar to that of Theorem 9.1.
10.3.3 Algorithm description
Based on the off-policy policy gradient theorem, we are ready to present the off-policy actor-critic algorithm. Since the off-policy case is very similar to the on-policy case, we merely present some key steps.
First, the off-policy policy gradient is invariant to any additional baseline b(s) . In particular, we have
The implementation of the off-policy actor-critic algorithm is summarized in Algorithm 10.3. As can be seen, the algorithm is the same as the advantage actor-critic algorithm except that an additional importance weight is included in both the critic and the actor. It must be noted that, in addition to the actor, the critic is also converted from on-policy to off-policy by the importance sampling technique. In fact, importance sampling is a general technique that can be applied to both policy-based and value-based algorithms. Finally, Algorithm 10.3 can be extended in various ways to incorporate more techniques such as eligibility traces [73].
Algorithm 10.3: Off-policy actor-critic based on importance sampling
Initialization: A given behavior policy β(a∣s) . A target policy π(a∣s,θ0) where θ0 is the initial parameter. A value function v(s,w0) where w0 is the initial parameter. αw,αθ>0 .
Goal: Learn an optimal policy to maximize J(θ) .
At time step t in each episode, do
Generate at following β(st) and then observe rt+1,st+1