15.3_常量内存中的模板
15.3 常量内存中的模板
在大多数模板匹配的应用中,我们都是使用同一个模板与输入图像的不同偏移区域做相关计算。在这种情况下,模板的统计量(SumT和fDenomExp)是可以被预先计算的,并且模板数据可以被放入到特殊的存储器当中。对于CUDA来说,显而易见,我们可以将模板数据放入常量内存中,这样模板数据可以以广播的方式传递给线程,并在图像中的不同位置做相关计算。
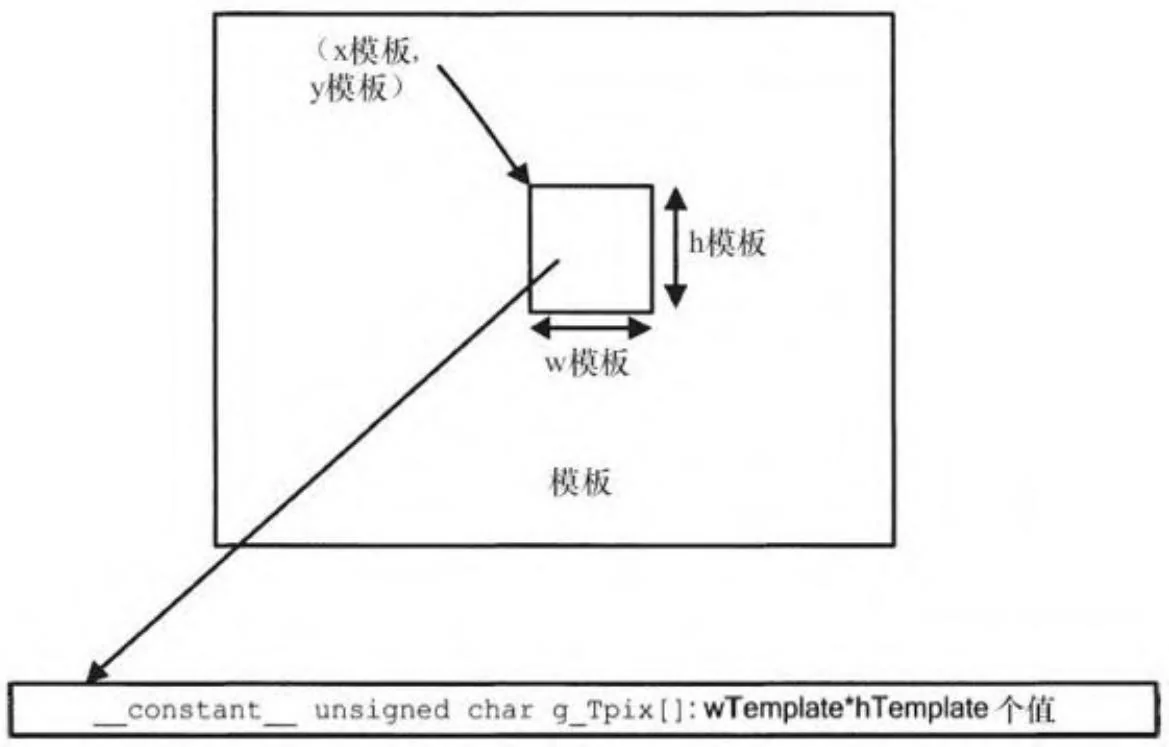
图15-3 常量内存中的模板
代码清单15-3的CopyToTemplate函数的功能是从输入图像中提取出一个矩形块,计算其统计量,然后将数据和统计量一起复制到常量内存中。
代码清单15-3 CopyToTemplate
cudaError_t
CopyToTemplate(
unsigned char *img, size_t imgPitch,
int xTemplate, int yTemplate,
int wTemplate, int hTemplate,
int OffsetX, int OffsetY
)
{
udaError_t status;
unsigned char pixels[maxTemplatePixels];
int inx = 0;
int SumT = 0;
int SumTSq = 0;
int cPixels = wTemplate*hTemplate;
size_t sizeOffsets = cPixels*sizeof(int);
float fSumT, fDenomExp, fcPixels;
cudaMemcpy2D(
pixels, wTemplate,
img+yTemplate*imgPitch+xTemplate, imgPitch,
wTemplate, hTemplate,
udaMemcpyDeviceToHost);
cudaMemcpyToSymbol(g_Tpix, pixels, cPixels);
for (int i = OffsetY; i < OffsetY+hTemplate; i++) {
for (int j = OffsetX; j < OffsetX+wTemplate; j++) {
SumT += pixels[inx];
SumTSq += pixels[inx]*pixels[inx];
poffsetx[inx] = j;
poffsety[inx] = i;
inx += 1;
}
}
g_cpuSumT = SumT;
g_cpuSumTSq = SumTSq;
cudaMemcpyToSymbol(g_xOffset, poffsetx, sizeOffsets);
cudaMemcpyToSymbol(g_yOffset, poffsety, sizeOffsets);
fSumT = (float) SumT;
cudaMemcpyToSymbol(g_SumT, &fSumT, sizeof(float));
fDenomExp = float((double)cPixels*SumTSq - (double) SumT*SumT);
cudaMemcpyToSymbol(g_fDenomExp, &fDenomExp, sizeof(float));
fcPixels = (float)cPixels;
cudaMemcpyToSymbol(g_cPixels, &fcPixels, sizeof(float));
Error:
return status;
}代码清单15-4给出了内核函数corrTemplate2D(),它从常量内存中的g_TPix[]读取模板的像素值。这个函数比corrTexTex2D()更简短,甚至都不必计算模板的统计量。
代码清单15-4 内核函数corrTemplate2D
global _void
corrTemplate2D_kernel(
float *pCorr, size_t CorrPitch,
float cPixels, float fDenomExp,
float xUL, float yUL, int w, int h,
int xOffset, int yOffset,
int wTemplate, int hTemplate)
{
size_t row = blockIdx.y*blockDim.y + threadIdx.y;
size_t col = blockIdx.x*blockDim.x + threadIdx.x;
// adjust pointers to row
pCorr = (float *) ((char *) pCorr+row*CorrPitch);
// No __syncthreads in this kernel, so we can early-out
// without worrying about the effects of divergence.
if (col >= w || row >= h)
return;
int SumI = 0;
int SumISq = 0;
int SumIT = 0;
int inx = 0;
for (int j = 0; j < hTemplate; j++) {
for (int i = 0; i < wTemplate; i++) {
unsigned char I = tex2D.texImage,
(float) col+xUL+xOffset+i,
(float) row+yUL+yOffset+j);
unsigned char T = g_Tpix[inx++] ;
SumI += I;
SumISq += I*I;
SumIT += I*T;
}
}
pCorr[col] =
CorrelationValue(
SumI, SumISq, SumIT, g_SumT, cPixels, fDenomExp);
}