15.7_性能评价
15.7 性能评价
我们的示例程序使用CUDA事件来评价连续启动多个内核(默认为100个)的性能表现。同时它能够向我们展示系数(随模板的大小变化而变化)和模板像素的输出速率,或单位时间“内循环”迭代的数量。
执行此计算的GPU的性能是惊人的。GeForce GTX 280(GT200)计算模板像素时可以达到每秒25 Gtpix/s(250亿次),而GeForce 680 GTX(GK104)的速率可以超过100 Gtpix/s。
程序的默认参数并不能提供最理想的性能,它检测到右下角的镍币并有选择的将其写进图15-3中。特别指出,该图像很小,并不能使GPU达到充分忙碌的状态。该图像为 像素(大小为74KB),所以通过共享内存来实现的话仅需要310个线程块来执行此计算。--padWidth和--padHeight命令行选项可用于在示例程序中补齐图像的大小,所以同时执行的相关系数的计算也增加了(代码中的数据没有依赖关系,所以可以填充任意数据)。对几乎所有的GPU测试来说, 大小的图像能够使GPU得到最充分的利用。
图15-5总结了我们之前的5种实现的性能表现:
·corrTexTex:模板和图像都在纹理内存中。
·corrTexConstant:模板在常量内存中。
·corrShared:模板在常量内存中,图像在共享内存中。
·corrSharedSM:基于流处理器簇的内核启动执行corrShared。
· corrShared4: 内循环展开 执行corrSharedSM。
图15-6展示了不同显卡上的不同方法所带来的性能的对比。将模板放入常量内存中对GK104的影响最大,最大性能提高 。将图像放入共享内存中对GF100的影响最大,性能可提高 。而基于流处理器簇启动内核函数的方式影响最小,能够对GT200的性能提高 (它并不会影响其他架构上的性能,因为使用内置的乘法运算也可达到最快)。
使用GT200时,corrShared在共享内存中会受到存储片冲突的影响,以至于运行速率比corrTexConstant还慢,corrShared4能够避免存储片冲突,性能提高 。
模板的大小也会对该算法的效率有影响。模板越大,对于每个模板像素的计算就越高效。图15-6展示了模板尺寸是如何影响corrShared4的性能的。
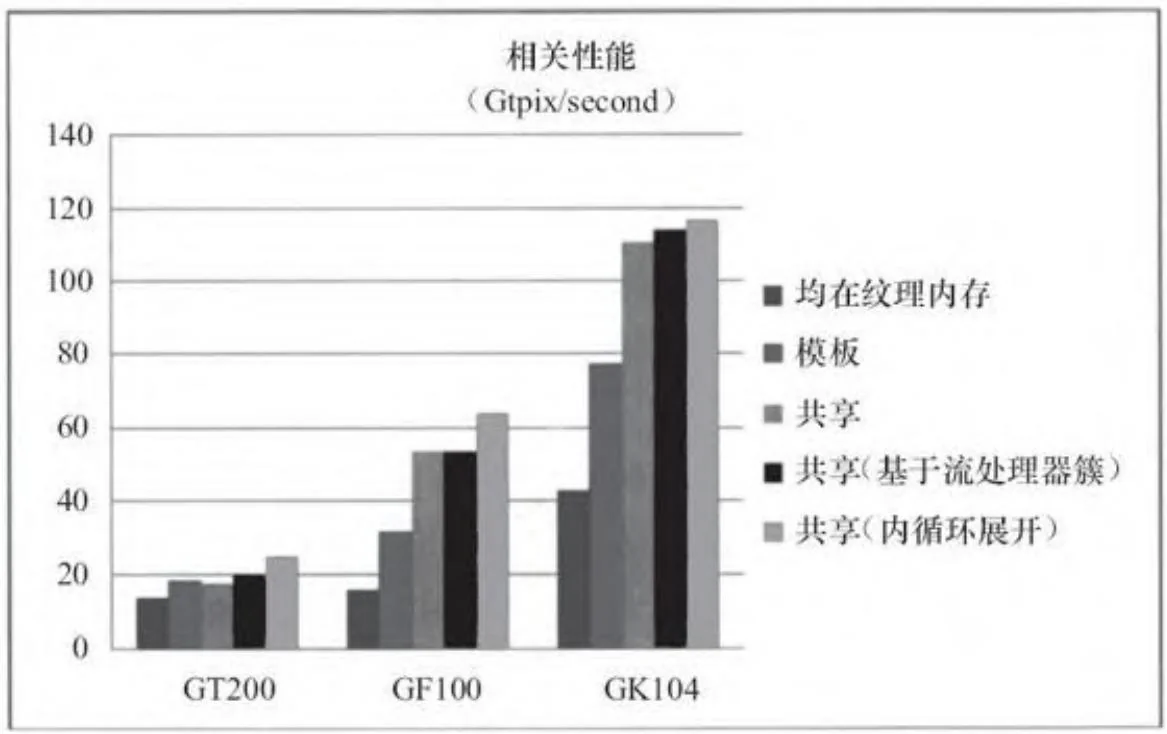
图15-5 性能比较
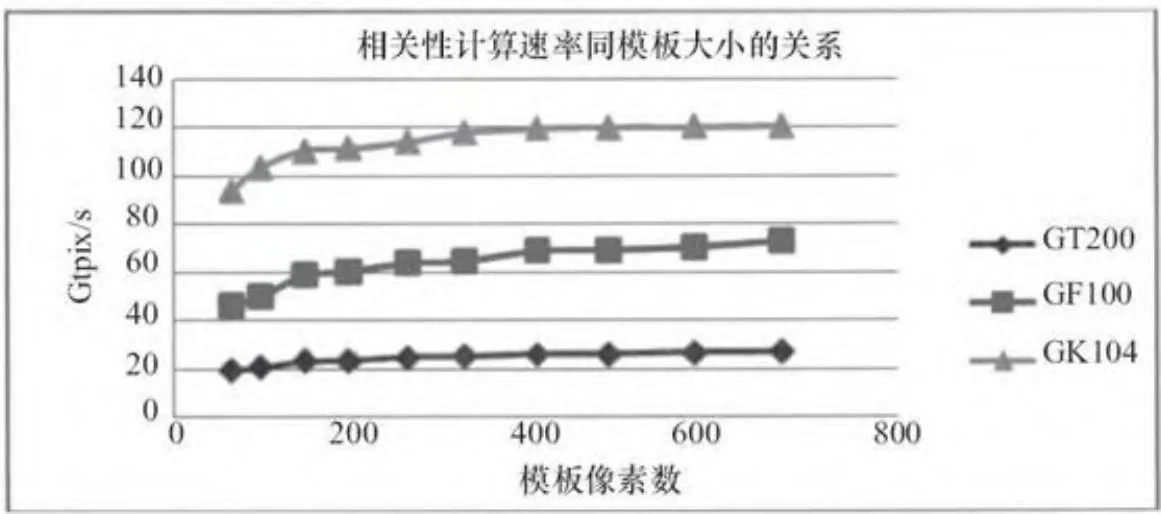
图15-6 相关系数计算速率同模板大小的关系
模板大小从 增长至 时,GT200的性能表现提高 (19.6 Gtpix/s提高至26.8 Gtpix/s)、GF100提高了57%(46.5
Gtpix/s提高至72.9 Gtpix/s)、GK104提高了 (93.9Gtpix/s提高至120.72 Gtpix/s)。
对于小模板来说,若在编译时就已知模板的大小,则编译器能够生成更快的代码。将wTemplate和hTemplate作为参数并专门为 的模板做改进后的性能如下所示: