7.3_线程块、线程、线程束、束内线程
7.3 线程块、线程、线程束、束内线程
内核以线程块构成的网格进行启动。这些线程可以进一步分为32个线程组成的线程束(warp),而每个线程束中的单个线程被称为一个束内线程。
7.3.1 线程块网格
线程块独立被调度到SM中,来自于同一线程块的线程在同一SM中执行。如图7-1显示的是二维线程块( )组成的一个二维网格( )。图7-2显示的是三维线程块( )组成的一个三维网格( )。
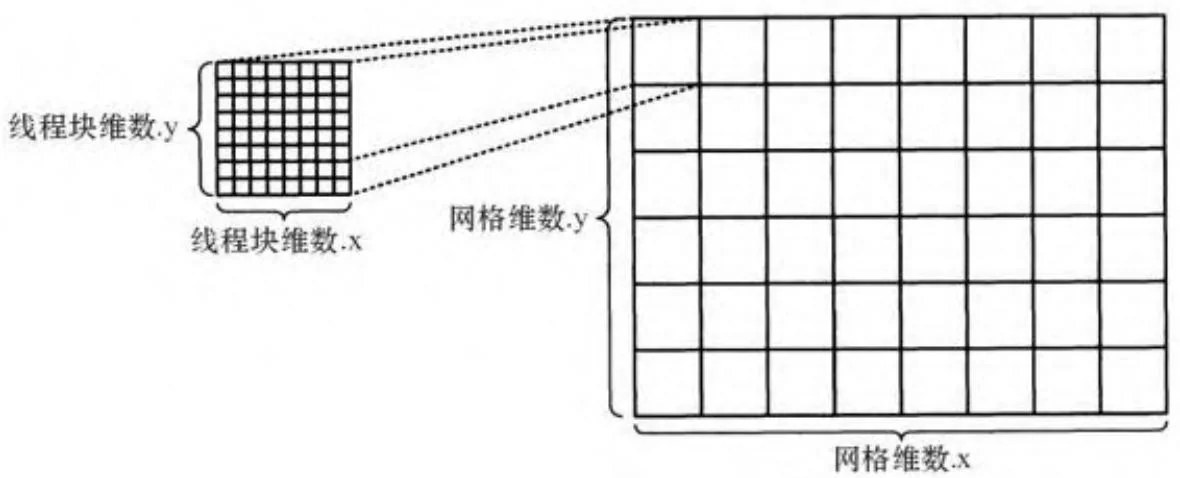
图7-1 二维网格与线程块
网格可以由高达 个线程块(对于SM1.0的硬件)或 的线程块(对于SM2.0的硬件)组成。[1]每个线程块可以由高达512或1024个线程组成[2],而线程块中的线程之间可以通过SM的共享内存进行通信。一个网格中的线程块有可能会被分配给不同的SM。为了使硬件吞吐量最大化,一个给定的SM可以在同一时间内运行来自不同线程块的线程与线程束。当所需要的资源变得可用,线程束的调度器会分派指令。
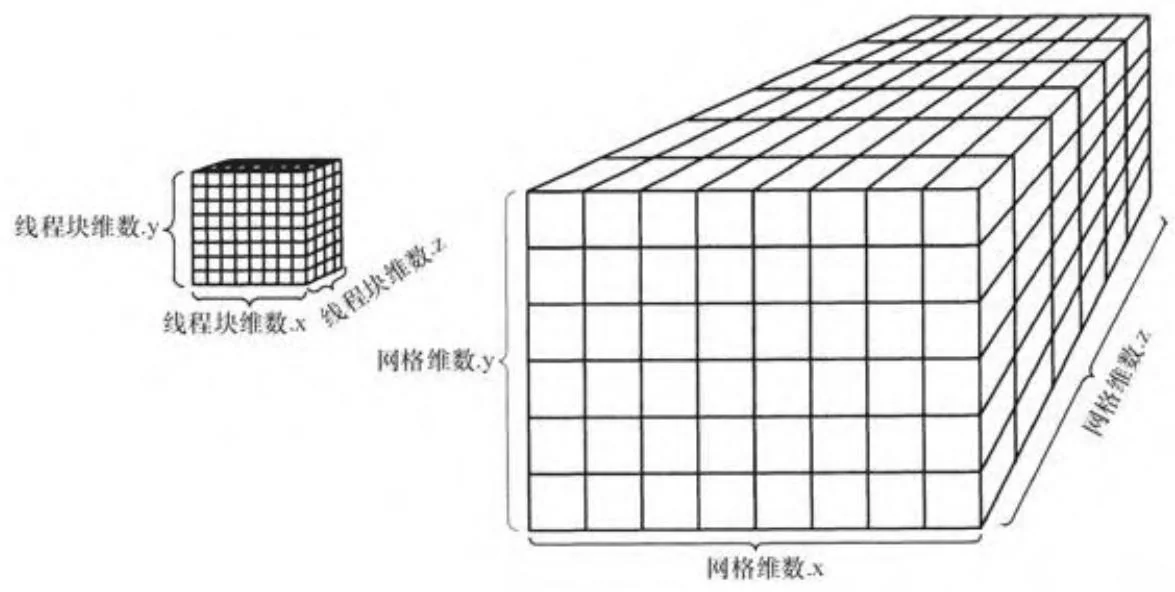
图7-2 三维网格与线程块
1. 线程
每个线程都可以得到属于自己的一组完整的寄存器 [3] 和一个线程块中唯一的线程ID。为了避免传递网格和线程块的尺寸到每一个内
核,这些尺寸在内核运行时是可读取的。而用来引用这些寄存器的内置变量已经在表7-1中给出。它们都是dim3类型的。
表7-1 引用寄存器的内置变量
综上,这些变量可以用来推断一个线程将作用到问题的哪个部分。一个线程的“全局”索引可以如下计算:
int globalThreadId = threadIdx.x+blockDim.x*(threadIdx.y+blockDim.y*threadIdx.z);2. 线程束、束内线程以及ILP
线程是成组执行的,按照SIMD的方式,每32个线程称为一个线程束,这类似于放置于“织布机”的一组平行织线 [4](见图7-3)。32个线程都执行同一个指令,且每个线程都使用私有寄存器进行这一请求操作。针对上述比喻,一个线程处于线程束中的ID将称为束内线程号(lane)。

图7-3 织布机
线程束ID和束内线程ID可以用如下的全局线程ID进行计算:
int warpID = globalThreadId >> 5;
int laneID = globalThreadId & 31;线程束是一个很重要的执行单元,因为它们是GPU可以隐藏延迟的最小粒度。关于GPU是如何使用线程束间的并行来隐藏内存延迟的,目前已有大量文档可查。满足全局内存请求需要数百个时钟周期,所以当遇到一个纹理获取或读取时,GPU会发出内存请求,然后在数据到达之前调度其他线程束的指令。一旦数据到达,线程束将再次变得有条件执行。
而言之较少的是GPU还通过发掘并行性来利用“指令级并行”(instruction level parallelism,ILP)。ILP是指在程序执行过程中发生的细粒度的并行机制,例如,当计算(a+b)*(c+d)时,加法运算a+b和c+d会在乘法运算执行之前并行地执行。因为SM已经包含有大量的用来跟踪依赖性和隐藏延迟的逻辑,它们都非常善于通过并行(这实际上是ILP)以及内存延迟来隐藏指令延时。GPU对ILP的支持是循环展开能够成为如此有效的一个优化策略的一部分原因,除了略微减少了每个循环迭代中的指令数外,它还为线程束调度器提供了更多的并行。
3. 对象作用域
可能会被内核网格引用的对象的作用域,从最小的本地(每个线程中的寄存器)到最大的全局(每个网格的全局内存和纹理引用),都已被总结于表7-2。在动态并行出现之前,线程块主要充当在一个线程块中的线程间同步(通过__syncthreads()等内建函数)和通信(通过共享内存)的一种机制。由于在内核中创建的流和事件仅适用于同一个线程块中的线程,动态并行把资源管理添加到它们的组合之中。
表7-2 对象作用域
(1)一个内核要执行的话只需要有足够的本地内存来服务于最大数目的活跃线程束即可。
②流与事件只能由CUDA内核使用动态并行来创建。
7.3.2 执行保证
开发者永远不要臆断线程块或线程执行的顺序是相当重要的。特别地,我们无法知道哪个线程块或线程会先执行,所以一般进行初始化应该由内核调用之外的代码执行。
执行保证与块间同步
在一个给定线程块中的线程保证驻留于同一SM,所以它们可以通过共享内存交换信息以及使用__syncthreads等内建函数进行同步执行。但线程块没有任何类似进行数据交换或同步的机制。
富有经验的CUDA开发者可能会问——“在全局内存中使用原子操作会如何呢?”。全局内存可以在一个使用原子操作的线程下安全地更新,所以它倾向于构建类似__syncthreads()的__syncblocks()函
数,让内核启动时的所有线程块在此处汇聚。也许在一个全局内存位置上还会执行一次atomicInc(),若该函数没有返回结果,则会轮询内存位置到返回为止。
问题是,内核的执行模式(例如,线程块映射到SM)会随着硬件配置的变化而变化。例如,SM的数量就是个限制因素,除非GPU上下文大到足够容纳所有的网格,有些线程块将会在其他线程块还没开始运行时已完成执行。这会导致死锁:因为并非所有的线程块都要驻留于GPU,所以正在轮询共享内存位置的线程块会阻止内核启动中的其他线程块执行。
这有几个块间同步有效的特殊情况。atomicCAS()可以用来实现简单的互斥。另外,线程块可以在它们完成时使用原子来发信号,所以网格中的最后一个线程块可以在退出之前执行一些操作,以表明其他线程块都已执行完毕。采用这种策略的threadFenceReduction SDK示例和reduction4SinglePass.cu示例,可以在这本书中找到(详见12.2节)。
7.3.3 线程块与线程ID
一组特殊的只读寄存器会以线程ID和线程块ID的形式提供每个线程的上下文。线程与线程块ID会在一个CUDA内核开始执行时分配。对
于2D、3D网格和线程块,它们会以行优先顺序(row-major order)进行分配。
线程块的大小最好是32的倍数,因为线程束是在GPU上执行的最细粒度。图7-4显示了线程ID在16W×2H、32W×1H和8W×4H规格的32线程构成的线程块中分别是如何分配的。
对于那些线程数不是32的倍数的线程块,某些线程束中并非所有的线程都是活跃的。图7-5就显示了 、 和 规格的28线程构成的线程块中线程ID的分配情况。在上述的每一种情况下,32线程的束中有4个线程在内核启动期间是无效的。对于任何大小不是32的倍数的线程块而言,一些执行资源会被浪费掉,因为某些线程束会包含整个内核执行期间禁用的束内线程进行启动。2D或3D的线程块或网格并没有太大的性能优势,但它们有时会有助于与应用程序更好的匹配。

线程块维数
线程块维数
线程块维数
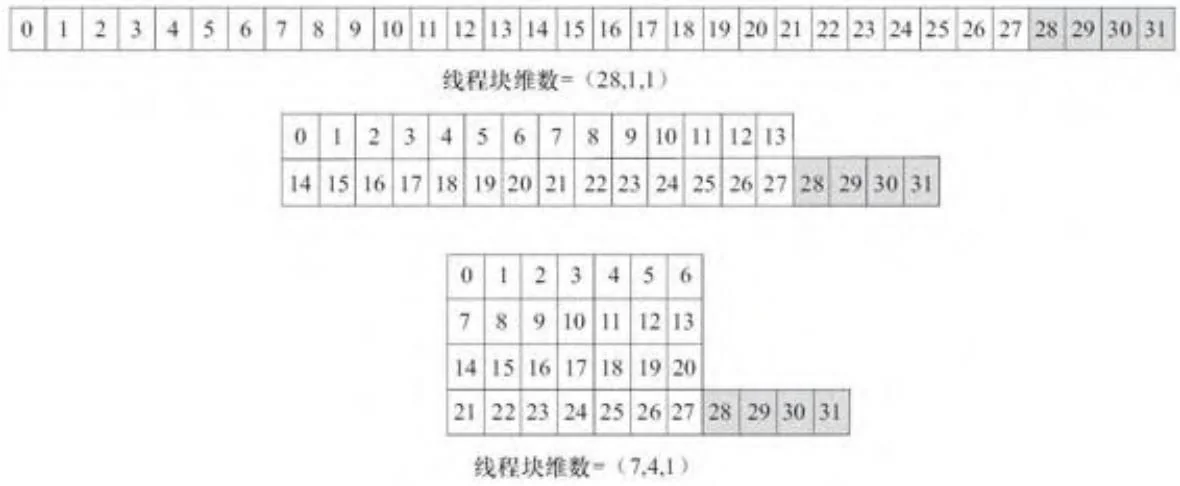
图7-4 32线程构成的线程块
图7-5 28线程块
如例7-2所示,reportClocks.cu程序说明了线程ID是如何分配的以及基于线程束的执行通常是如何工作的。
例7- 2 WriteClockValues内核
.global__void
WriteClockValues{ unsigned int \*completionTimes, unsigned int \*threadIDs
1 size_t globalBlock $=$ blockIdx.x+blockDim.x\* (blockIdx.y+blockDim.y\*blockIdx.z); size_t globalThread $=$ threadIdx.x+blockDim.x\* (threadIdx.y+blockDim.y\*threadIdx.z); size_t totalBlockSize $=$ blockDim.x\*blockDim.y\*blockDim.z; size_t globalIndex $=$ globalBlock\*totalBlockSize + globalThread; completionTimes[globalIndex] $=$ clock(); threads[globalIndex] $=$ threadIdx.y<<4|threadIdx.x;WriteClockValues()函数中使用由线程块和线程ID以及网格和线程块大小计算的全局索引来写入2个输出指针。第一个输出指针用来接
收内建clock()的返回值。该返回值为一个高分辨率计时器值,随每个线程束不断增加。在这个程序中,我们使用clock()来确定是哪个线程束处理给定值的。clock()的返回值是每个SM私有的时钟周期计数器,通过和从所有的时钟周期值计算出的最小值做减法来使该值规格化。我们称该结果值为线程的“完成时间”。
让我们来看看在一个 规格的线程块中线程的完成时间(例7-3),并与 规格中的完成时间(例7-4)进行比较。正如预期的那样,它们被分为32组,对应于线程束的大小。
例7- 3 规格线程块的完成时间
0.01 ms for 256 threads = 0.03 us/thread
Completion times (clocks):
Grid (0, 0, 0) - slice 0:
4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4
4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4 4
6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6
6 6 6 6 6 6 6 6 6 6 6 6 6 6 6 6
8 8 8 8 8 8 8 8 8 8 8 8 8 8 8 8
8 8 8 8 8 8 8 8 8 8 8 8 8 8 8
a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a
Grid (1, 0, 0) - slice 0:
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2
4 4 4 4 4 4 4 4 4 4 4
4 4 4
6
6
6
6
6
Grid (0, o, o) - slice O:
1111111111111111111111111111111111111111111111111111111111111111111111111111111111111例7- 4 规格线程块的完成时间
例7- 4中给出的 规格线程块的完成时间强调了线程ID是如何映射到线程束的。在 规格下,每一个线程束中只有28个线程。在内核执行的整个过程中,可能的线程束内 的线程数目是空
闲的。为了避免这种浪费,开发者始终应该尽量确保线程块包含32倍数的线程。
[1] 网格的最大尺寸可以通过
CU_DEVICE_ATTRIBUTE_MAXGRID_DIM_X
CU_DEVICE_ATTRIBUTE_MAXGRID_DIM_Y
CU_DEVICE_ATTRIBUTE_MAXGRID_DIM_Z查询,亦可以通过调用CUDAGetDeviceGetProperty()函数并检查CUDADeviceProp::maxGridSize进行查询。
[2] 线程块的最大尺寸可以通过
CU_DEVICE_ATTRIBUTE_MAX_THREAD_PER_BLOCK 或
deviceProp.maxThreadsPerBlock查询。
[3] 每个线程所需的寄存器越多,在一个给定SM中可以分配到寄存器
的线程也就越少。而一个SM中实际执行的线程束与其最大理论值的百
分比称为占用率(详见7-4节)。
[4] 线程束大小是可查询的, 但考虑到硬件的兼容性问题, 开发者在可
预期的未来,可将其固定当作32个。