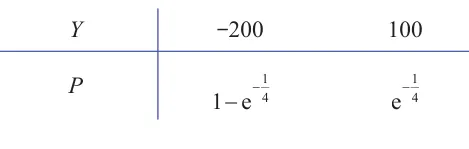随机变量的分布函数、分布律或概率密度虽然能完整地描述随机变量的统计规律,但在实际问题中,随机变量的分布往往不容易确定,而且有些问题并不需要知道随机变量分布规律的全貌,只需要知道它的某些特征就够了。例如,考察 LED灯管的质量时,常常关注的是 LED 灯管的平均寿命,这说明随机变量的平均值是一个重要的数量特征(称作期望)。又例如,比较两台机床生产精度的高低,不仅要看它们生产的零件的平均尺寸,还必须考察每个零件尺寸与平均尺寸的偏离程度,只有偏离程度较小的才是精度高的(称作方差),这说明随机变量与其平均值偏离的程度也是一个重要的数量特征。
数学期望反映了在大量重复试验中,某个随机事件的“平均结果”。例如 掷骰子 每个点数(1-6)出现的概率均为1/6,期望值为 (1+2+3+4+5+6)/6 = 3.5。虽然实际掷骰子不会出现3.5,但若重复无数次,平均点数会趋近于3.5。 再如 赌博场景 :若轮盘赌押中一个数字的概率是1/38,奖金为35倍本金,期望收益为 (1/38)×35 + (37/38)×(-1) ≈ -0.0526美元,即长期每赌一次平均亏约5美分
离散型数学期望的定义 设 X X X
P ( X = x i ) = p i , i = 1 , 2 , ⋯ P\left(X=x_i\right)=p_i, \quad i=1,2, \cdots P ( X = x i ) = p i , i = 1 , 2 , ⋯ 当级数 ∑ i x i p i \sum_i x_i p_i ∑ i x i p i ∑ i x i p i \sum_i x_i p_i ∑ i x i p i X X X E ( X ) E(X) E ( X )
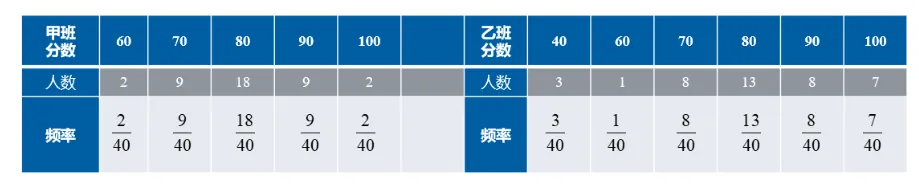
例 设甲、乙两班各 40 名学生,概率统计成绩及得分人数如表所示,
甲、乙两班概率统计的平均成绩各是多少?
解:(1)甲班平均成绩 = 60 × 2 40 + 70 × 9 40 + 80 × 18 40 + 90 × 9 40 + 100 × 2 40 = 80 =60 \times \frac{2}{40}+70 \times \frac{9}{40}+80 \times \frac{18}{40}+90 \times \frac{9}{40}+100 \times \frac{2}{40}=80 = 60 × 40 2 + 70 × 40 9 + 80 × 40 18 + 90 × 40 9 + 100 × 40 2 = 80
(2)同理,乙班平均成绩 = 80 =80 = 80
注意:
1)为保证无穷级数 ∑ i x i p i \sum_i x_i p_i ∑ i x i p i ∑ i x i p i \sum_i x_i p_i ∑ i x i p i E ( X ) E(X) E ( X )
2) 当 X X X E ( X ) E(X) E ( X ) 期望 。期望刻画随机变量取值的平均,有直观含义。
例设随机变量 X X X P ( X = 2 i i ) = 1 2 i , i = 1 , 2 , ⋯ P\left(X=\frac{2^i}{i}\right)=\frac{1}{2^i}, i=1,2, \cdots P ( X = i 2 i ) = 2 i 1 , i = 1 , 2 , ⋯ P ( X = ( − 1 ) i 2 i i ) = 1 2 i , i = 1 , 2 , ⋯ P\left(X=(-1)^i \frac{2^i}{i}\right)=\frac{1}{2^i}, i=1,2, \cdots P ( X = ( − 1 ) i i 2 i ) = 2 i 1 , i = 1 , 2 , ⋯ P ( X = ( − 1 ) i 2 i i 2 ) = 1 2 i , i = 1 , 2 , ⋯ P\left(X=(-1)^i \frac{2^i}{i^2}\right)=\frac{1}{2^i}, i=1,2, \cdots P ( X = ( − 1 ) i i 2 2 i ) = 2 i 1 , i = 1 , 2 , ⋯ X X X E ( X ) E(X) E ( X )
解(1)因为 ∑ i = 1 ∞ ∣ x i ∣ p i = ∑ i = 1 ∞ 2 i i ⋅ 1 2 i = ∑ i = 1 ∞ 1 i \sum_{i=1}^{\infty}\left|x_i\right| p_i=\sum_{i=1}^{\infty} \frac{2^i}{i} \cdot \frac{1}{2^i}=\sum_{i=1}^{\infty} \frac{1}{i} ∑ i = 1 ∞ ∣ x i ∣ p i = ∑ i = 1 ∞ i 2 i ⋅ 2 i 1 = ∑ i = 1 ∞ i 1 X X X ∑ i = 1 ∞ ∣ x i ∣ p i = ∑ i = 1 ∞ ∣ ( − 1 ) i 2 i i ∣ ⋅ 1 2 i = ∑ i = 1 ∞ 1 i \sum_{i=1}^{\infty}\left|x_i\right| p_i=\sum_{i=1}^{\infty}\left|(-1)^i \frac{2^i}{i}\right| \cdot \frac{1}{2^i}=\sum_{i=1}^{\infty} \frac{1}{i} ∑ i = 1 ∞ ∣ x i ∣ p i = ∑ i = 1 ∞ ( − 1 ) i i 2 i ⋅ 2 i 1 = ∑ i = 1 ∞ i 1 X X X ∑ i = 1 ∞ ∣ x i ∣ p i = ∑ i = 1 ∞ 2 i i 2 ⋅ 1 2 i = ∑ i = 1 ∞ 1 i 2 \sum_{i=1}^{\infty}\left|x_i\right| p_i=\sum_{i=1}^{\infty} \frac{2^i}{i^2} \cdot \frac{1}{2^i}=\sum_{i=1}^{\infty} \frac{1}{i^2} ∑ i = 1 ∞ ∣ x i ∣ p i = ∑ i = 1 ∞ i 2 2 i ⋅ 2 i 1 = ∑ i = 1 ∞ i 2 1 X X X
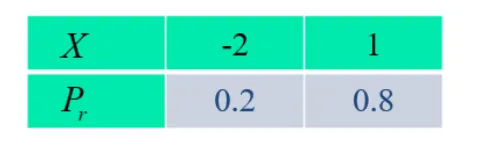
例 设离散型随机变量 X X X E ( X ) E(X) E ( X )
解 E ( X ) = ∑ i x i p i = − 2 × 0.2 + 1 × 0.8 = 0.4 E(X)=\sum_i x_i p_i=-2 \times 0.2+1 \times 0.8=0.4 E ( X ) = ∑ i x i p i = − 2 × 0.2 + 1 × 0.8 = 0.4
连续型数学期望的定义 设 X X X f ( x ) f(x) f ( x ) ∫ − ∞ + ∞ x f ( x ) d x \int_{-\infty}^{+\infty} x f(x) \mathrm{d} x ∫ − ∞ + ∞ x f ( x ) d x
E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x . E(X)=\int_{-\infty}^{+\infty} x f(x) \mathrm{d} x . E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x . 为连续型随机变量 X X X
例设有离散型随机变量 X X X X X X E ( X ) E(X) E ( X ) X ∼ B ( 1 , p ) X \sim B(1, p) X ∼ B ( 1 , p ) X ∼ B ( n , p ) X \sim B(n, p) X ∼ B ( n , p ) X ∼ P ( λ ) X \sim P(\lambda) X ∼ P ( λ ) X ∼ B ( 1 , p ) X \sim B(1, p) X ∼ B ( 1 , p ) E ( X ) = ∑ i x i p i = 0 ⋅ q + 1 ⋅ p = p E(X)=\sum_i x_i p_i=0 \cdot q+1 \cdot p=p E ( X ) = ∑ i x i p i = 0 ⋅ q + 1 ⋅ p = p X ∼ B ( n , p ) X \sim B(n, p) X ∼ B ( n , p ) P ( X = k ) = ( n k ) p k q n − k , k = 0 , 1 , 2 , ⋯ , n P(X=k)=\left(\begin{array}{l}n \\ k\end{array}\right) p^k q^{n-k}, k=0,1,2, \cdots, n P ( X = k ) = ( n k ) p k q n − k , k = 0 , 1 , 2 , ⋯ , n
E ( X ) = ∑ k = 0 n k n ! k ! ( n − k ) ! p k q n − k = ∑ k = 1 n n ! ( k − 1 ) ! ( n − k ) ! p k q n − k = n p ∑ k = 1 n ( n − 1 ) ! ( k − 1 ) ! ( n − k ) ! p k − 1 q n − 1 − ( k − 1 ) \begin{aligned}
& E(X)=\sum_{k=0}^n k \frac{n !}{k !(n-k) !} p^k q^{n-k}=\sum_{k=1}^n \frac{n !}{(k-1) !(n-k) !} p^k q^{n-k} \\
& =n p \sum_{k=1}^n \frac{(n-1) !}{(k-1) !(n-k) !} p^{k-1} q^{n-1-(k-1)} \\
&
\end{aligned} E ( X ) = k = 0 ∑ n k k ! ( n − k )! n ! p k q n − k = k = 1 ∑ n ( k − 1 )! ( n − k )! n ! p k q n − k = n p k = 1 ∑ n ( k − 1 )! ( n − k )! ( n − 1 )! p k − 1 q n − 1 − ( k − 1 ) (3) 因为 X ∼ P ( λ ) X \sim P(\lambda) X ∼ P ( λ ) P ( X = k ) = λ k k ! e − λ , k = 0 , 1 , 2 , ⋯ P(X=k)=\frac{\lambda^k}{k !} e^{-\lambda}, k=0,1,2, \cdots P ( X = k ) = k ! λ k e − λ , k = 0 , 1 , 2 , ⋯
E ( X ) = ∑ k = 0 n k λ k k ! e − λ = λ e − λ ∑ k = 1 n λ k − 1 ( k − 1 ) ! \begin{aligned}
& E(X)=\sum_{k=0}^n k \frac{\lambda^k}{k !} e^{-\lambda}=\lambda e^{-\lambda} \sum_{k=1}^n \frac{\lambda^{k-1}}{(k-1) !} \\
&
\end{aligned} E ( X ) = k = 0 ∑ n k k ! λ k e − λ = λ e − λ k = 1 ∑ n ( k − 1 )! λ k − 1 例设有连续型随机变量 X X X X X X E ( X ) E(X) E ( X ) X ∼ U ( a , b ) X \sim U(a, b) X ∼ U ( a , b ) X ∼ E ( λ ) X \sim E(\lambda) X ∼ E ( λ ) X ∼ N ( μ , σ 2 ) X \sim N\left(\mu, \sigma^2\right) X ∼ N ( μ , σ 2 )
解 (1) 因为 X ∼ U ( a , b ) X \sim U(a, b) X ∼ U ( a , b ) X X X
f ( x ) = { 1 b − a , a < x < b , 0 , 其他. f(x)= \begin{cases}\frac{1}{b-a}, & a<x<b, \\ 0, & \text { 其他. }\end{cases} f ( x ) = { b − a 1 , 0 , a < x < b , 其他 . 由期望的定义得
E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x = ∫ a b x b − a d x = a + b 2 E(X)=\int_{-\infty}^{+\infty} x f(x) d x=\int_a^b \frac{x}{b-a} d x=\frac{a+b}{2} E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x = ∫ a b b − a x d x = 2 a + b (2) 因为 X ∼ E ( λ ) X \sim E(\lambda) X ∼ E ( λ ) X X X
f ( x ) = { λ e − λ x , x > 0 , 0 , x ≤ 0. f(x)= \begin{cases}\lambda e^{-\lambda x}, & x>0, \\ 0, & x \leq 0 .\end{cases} f ( x ) = { λ e − λ x , 0 , x > 0 , x ≤ 0. 由课前导读中的积分公式 1 得
E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x = ∫ 0 + ∞ x λ e − λ x d x = λ ⋅ 1 ! λ 2 = 1 λ 或 = − x e − λ x ∣ 0 + ∞ + ∫ 0 + ∞ e − λ x d x = − 1 λ e − λ x ∣ 0 + ∞ = 1 λ \begin{array}{r}
E(X)=\int_{-\infty}^{+\infty} x f(x) d x=\int_0^{+\infty} x \lambda e^{-\lambda x} d x=\lambda \cdot \frac{1 !}{\lambda^2}=\frac{1}{\lambda} \\
\text { 或 }=-\left.x e^{-\lambda x}\right|_0 ^{+\infty}+\int_0^{+\infty} e^{-\lambda x} d x=-\left.\frac{1}{\lambda} e^{-\lambda x}\right|_0 ^{+\infty}=\frac{1}{\lambda}
\end{array} E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x = ∫ 0 + ∞ x λ e − λ x d x = λ ⋅ λ 2 1 ! = λ 1 或 = − x e − λ x 0 + ∞ + ∫ 0 + ∞ e − λ x d x = − λ 1 e − λ x 0 + ∞ = λ 1 (3)因为 X ∼ N ( μ , σ 1 2 ) X \sim N\left(\mu, \sigma_1^2\right) X ∼ N ( μ , σ 1 2 ) X X X
f ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 f(x)=\frac{1}{\sqrt{2 \pi} \sigma} e^{-\frac{(x-\mu)^2}{2 \sigma^2}} f ( x ) = 2 π σ 1 e − 2 σ 2 ( x − μ ) 2 由期望的定义得
E ( X ) = ∫ − ∞ + ∞ x 1 2 π σ e − ( x − μ ) 2 2 σ 2 d x = 今े t = x − μ σ ∫ − ∞ + ∞ ( σ t + μ ) 1 2 π σ e − t 2 2 ⋅ σ d t = μ E(X)=\int_{-\infty}^{+\infty} x \frac{1}{\sqrt{2 \pi} \sigma} e^{-\frac{(x-\mu)^2}{2 \sigma^2}} d x \stackrel{\text { 今े } t=\frac{x-\mu}{\sigma}}{=} \int_{-\infty}^{+\infty}(\sigma t+\mu) \frac{1}{\sqrt{2 \pi} \sigma} e^{-\frac{t^2}{2}} \cdot \sigma d t=\mu
E ( X ) = ∫ − ∞ + ∞ x 2 π σ 1 e − 2 σ 2 ( x − μ ) 2 d x = 今 े t = σ x − μ ∫ − ∞ + ∞ ( σ t + μ ) 2 π σ 1 e − 2 t 2 ⋅ σ d t = μ 上式使用了密度函数的规范性
例 一工厂生产的某种设备的寿命 X X X 1 4 \frac{1}{4} 4 1
解 因为 X X X 1 4 \frac{1}{4} 4 1
F ( x ) = { 1 − e − 1 4 x , x > 0 , 0 , x ⩽ 0. F(x)= \begin{cases}1-\mathrm{e}^{-\frac{1}{4} x}, & x>0, \\ 0, & x \leqslant 0 .\end{cases} F ( x ) = { 1 − e − 4 1 x , 0 , x > 0 , x ⩽ 0. 一台设备在一年内损坏的概率为 P { X < 1 } = F ( 1 ) = 1 − e − 1 4 P\{X<1\}=F(1)=1-\mathrm{e}^{-\frac{1}{4}} P { X < 1 } = F ( 1 ) = 1 − e − 4 1
P { X ⩾ 1 } = 1 − P { X < 1 } = 1 − ( 1 − e − 1 4 ) = e − 1 4 . P\{X \geqslant 1\}=1-P\{X<1\}=1-\left(1-\mathrm{e}^{-\frac{1}{4}}\right)=\mathrm{e}^{-\frac{1}{4}} . P { X ⩾ 1 } = 1 − P { X < 1 } = 1 − ( 1 − e − 4 1 ) = e − 4 1 . 设 Y Y Y
故 E ( Y ) = ( − 200 ) × ( 1 − e − 1 4 ) + 100 × e − 1 4 = 300 e − 1 4 − 200 ≈ 33.64 (元) . \begin{aligned}
&\text { 故 }\\
&E(Y)=(-200) \times\left(1-\mathrm{e}^{-\frac{1}{4}}\right)+100 \times \mathrm{e}^{-\frac{1}{4}}=300 \mathrm{e}^{-\frac{1}{4}}-200 \approx 33.64 \quad \text { (元) . }
\end{aligned} 故 E ( Y ) = ( − 200 ) × ( 1 − e − 4 1 ) + 100 × e − 4 1 = 300 e − 4 1 − 200 ≈ 33.64 ( 元 ) . 概率分布表 下面列出了常见的概率分布表,
在附录里,附带了常见的概率分布表,详见 此处