正态分布的密度函数是如何得来的
正态分布是一种常见的分布,他的密度函数是
f(x)=2πσ1e−21(σx−μ)2 这个公式是德国数学家高斯推出来的,因此正态分布也被称作高斯分布
 {width=200px}
{width=200px}
关于高斯的介绍请点击 此处
正态分布如此重要,以至于原德国货币10马克上,直接把高斯、正态分布曲线及其公式都画上去了,这可见高斯和正态分布在数理统计中的重要地位。
 {width=500px}
{width=500px}
根据当年高斯发表的《天体运行论》(Theoria Motus Corporum Coelestium in Sectionibus Conicis Solem Ambientium, 1809),沿寻着高斯的思路进行推导。
推导
假设有误差概率密度函数 f(t) ,现在有 n 个独立观测的值 x1,x2,⋯xn ,假设真值为 μ ,那么误差为:
ε1ε2εn=x1−μ=x2−μ⋮=xn−μ 根据生活经验,这个误差 ε ,在做大量的观测下,其大部分的数值应在 0 附近范围波动,且出现的频数较多。而误差大的观测值,相应的 ∣ε∣ 也应很大,出现的频数也应该较小。做极大似然函数 :
L(μ)=i=1∏nf(εi)=f(x1−μ)f(x2−μ)⋯f(xn−μ) 对 L(μ) 取自然对数:
ln[L(μ)]=ln[i=1∏nf(εi)]=ln[f(x1−μ)f(x2−μ)⋯f(xn−μ)]=ln[f(x1−μ)]+ln[f(x2−μ)]+⋯+ln[f(xn−μ)]=i=1∑nln[f(xi−μ)] 为了得到 L(μ) 的最大值,对其 ln[L(μ)] 求偏导并令其等于 0 :
∂μ∂ln[L(μ)]=∂μ∂∑i=1nln[f(xi−μ)]=−i=1∑nf(xi−μ)f′(xi−μ)=0 注意上面出现的负号一;
令 g(t)=f(t)f′(t) ,则上述式子变成:
i=1∑ng(xi−μ)=0 到了这一步后,精彩的部分就开始来了,这也是高斯的高明之处,他认为 μ 的无偏估计应为 xˉ(xi 的算术平均数)。如果有学过概率论与数理统计,应该知道,根据大数定律 ,当观测值 (x1,x2,⋯xn) 的个数非常大的时候 (n→∞),xˉ 应该是无限接近 μ 。那么,把上面的 ∑ 式里 μ 用 xˉ 来代替,则原式子变为:
i=1∑ng(xi−xˉ)=0 其中,
xˉ=n1i=1∑nxi 解上述方程,对每个 xi 求偏导,比如对 x1 求偏导,可得如下方程:
∂x1∂∑i=1ng(xi−xˉ)=∂x1∂∑i=1ng(xi−n1∑i=1nxi)=g′(x1−xˉ)(1−n1)+g′(x2−xˉ)(−n1)+⋯+g′(xn−xˉ)(−n1)=0 注意,上述式子中, xˉ 为 x1 的函数,所以根据复合函数求导法则,得出上述式子。和 x1类似,依次得出 x1 和其他 xi 的表达式,可得如下方程组:
g′(x1−xˉ)(1−n1)+g′(x2−xˉ)(−n1)+⋯+g′(xn−xˉ)(−n1)=0g′(x1−xˉ)(−n1)+g′(x2−xˉ)(1−n1)+⋯+g′(xn−xˉ)(−n1)=0⋮g′(x1−xˉ)(−n1)+g′(x2−xˉ)(−n1)+⋯+g′(xn−xˉ)(1−n1)=0 将 g′(xi−xˉ) 看做未知数,把上述 n 个齐次线性方程组写成矩阵方程 Ax=0 的形式:
1−n1−n1⋮−n1−n11−n1⋮−n1⋯⋯⋮−n1−n1−n1⋮1−n1g′(x1−xˉ)g′(x2−xˉ)⋮g′(xn−xˉ)=00⋮0 解到这一步,还真的得回去翻高等代数的教材。这个方程的解并不是那么的容易。很多"容易看出"、"显然",对我来说,真的不是那么"容易看出"和"显然"的。
对于上述方程组的系数矩阵 M ,将第 2⋯n 行依次加到第 1 行,可得如下矩阵:
M=1−n1−n1⋮−n1−n11−n1⋮−n1⋯⋯⋮−n1−n1−n1⋮1−n1→0−n1⋮−n101−n1⋮−n1⋯⋯⋮−n10−n1⋮1−n1 第一行全为 0 ,那么 det(M)=0 ,这只能说明方程组有无穷多解,具体还要算出 rank(M) ,那么就要算出 M 内子式阶数小于 n 的行列式的值。按如下分析:
系数矩阵可以写成如下形式:
M=1−n1−n1⋮−n1−n11−n1⋮−n1⋯⋯⋮−n1−n1−n1⋮1−n1=11⋱1−n1n1⋮n1n1n1⋮n1⋯⋯⋮n1n1n1⋮n1=11⋱1−11⋮1(n1n1⋯n1)=In−αβT 根据《高等代数》 (第四版,谢启鸿,姚慕生,复旦大学出版社)里面的定理: A 为 m×n 矩阵, B 为 n×m 矩阵 (m>n) ,则存在等式:
∣λIm−AB∣=λm−n∣λIn−BA∣ 根据上述定理,令 A=α,B=β,λ=1 ,则:
∣M∣=In−αβT=I1−βTα=11n1⋯n1)11⋮1=∣1−1∣=0 而对于 M 的前 n−1 阶主子式 N ,形式类似,也可以拆解成如下形式,但是只有 n−1阶:
N=1−n1−n1⋮−n1−n11−n1⋮−n1⋯⋯⋮−n1−n1−n1⋮1−n1(n−1)×(n−1)=11⋱1−n1n1⋮n1n1n1⋮n1⋯⋯⋮n1n1n1⋮n1=11⋱1−11⋮1(n1n1⋯n1)=In−1−γηT 那么
∣N∣=In−1−γηT=I1−ηTγ=1−(n1n1⋯n1)1×(n−1)11⋮1(n−1)×1=1−nn−1=n1=0 所以 rank(M)=n−1 ,所以线性方程组的自由变量的个数:
n−rank(M)=n−(n−1)=1 因而,上述方程组的解可写成:
X=kg′(x1−xˉ)g′(x2−xˉ)⋮g′(xn−xˉ)=k11⋮1 即 g′(x1−xˉ)=g′(x2−xˉ)=⋯=g′(xn−xˉ)=k ,解微分方程,可得:
g(t)=kt+b 因为 ∑i=1ng(xi−xˉ)=0 ,将 g(t)=kt+b 带入该式,可得:
i=1∑n[k(xi−xˉ)+b]=0⇔ki=1∑n(xi−xˉ)+nb=0⇔k(i=1∑nxi−nxˉ)+nb=0⇔nb=0⇔b=0 求得 g(t)=kt ,即 f(t)f′(t)=kt ,求解该微分方程:
∫f(t)f′(t)dt=∫ktdt⇔∫f(t)d[f(t)]=21kt2+c⇔ln[f(t)]=21kt2+c⇔f(t)=Ke21kt2 同时,f(t) 为概率密度函数,那么其从 −∞ 到 +∞ 的积分为 1 (概率密度的正则性),则
∫−∞+∞f(t)dt=1 其中,f(t)=Ke21kt2 ,为保证积分收玫,则 k<0 ,令
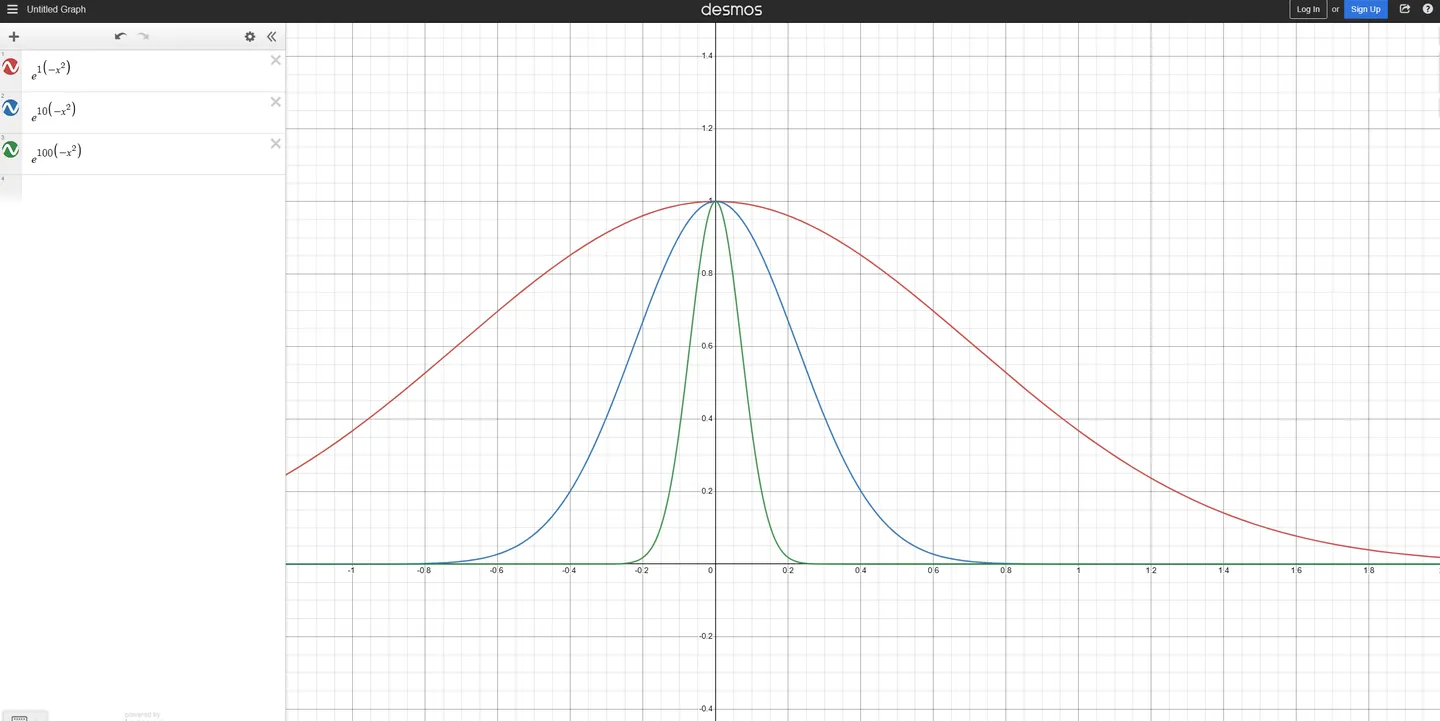
k=−σ21<0 这一步真不知道高斯是怎么想的。既能能保证 k<0 ,同时引入了方差 σ2 ,非常巧妙。盲猜和 e−x2 的形态有关。该函数为偶函数,如图,随 −x2 前面的系数的增大,函数图像形态越"尖",分布越集中。与我们所知的"方差越大,越分散;方差越小,越集中"有些相似,因而将 σ2 引入 −x2 的系数的分母中,可实现函数图像和实际概率密度函数图像的大致吻合。
求积分:
∫−∞+∞f(t)dt=∫−∞+∞Ke21kt2dt=K∫−∞+∞e−2σ2t2dt=K2σ[∫−∞+∞e−(2σt)2d(2σ1t)][2σ∫−∞+∞e−(2σs)2d(2σ1s)=K2σ∫−∞+∞∫−∞+∞e−(u2+v2)dudv=K2σ∫02πdθ∫0+∞e−r2rdr=K2σπ=1 解得 K=2πσ1
最终求得正态分布的概率密度函数
f(t)=2πσ1e−21(σt)2 本文转摘知乎不小心把你丢了的文章,点击 此处 查看原文