50.4_螺旋数据集的训练代码
50.4 螺旋数据集的训练代码
下面使用 DataLoader 类和 accuracy 函数来训练螺旋数据集。代码如下所示(省略了导入部分)。
steps/step50.py
max_epoch = 300
batch_size = 30
hidden_size = 10
lr = 1.0
train_set =dezero.datasets.Spiral(train=True)
test_set =dezero.datasets.Spiral(train=False)
trainloader = DataLoader(train_set, batch_size)
testloader = DataLoader(test_set, batch_size, shuffle=False)
model = MLP((hidden_size, 3))
optimizer = optimizers.SGD(lr).setup(model)
for epoch in range(max_epoch):
sum_loss, sum_acc = 0, 0for x, t in trainloader: # ①用于训练的小批量数据
y = model(x)
loss = F softmaxcross_entropy(y, t)
acc = FAccuracy(y, t) # ②训练数据的识别精度
model.cleargrads()
lossbackward()
optimizer.update()
sum_loss += float(loss.data) * len(t)
sum_acc += float(acc.data) * len(t)
print('epoch: {}.format(epochs+1))
print('train loss: {:.4f}', accuracy: {:.4f}.format(
sum_loss / len(train_set), sum_acc / len(train_set)))
sum_loss, sum_acc = 0, 0
withdezero.no_grad(): # ③无梯度模式
for x, t in testloader: # ④用于测试的小批量数据
y = model(x)
loss = F softmaxcross_entropy(y, t)
acc = FAccuracy(y, t) # ⑤测试数据的识别精度
sum_loss += float(loss.data) * len(t)
sum_acc += float(acc.data) * len(t)
print('test loss: {:.4f}', accuracy: {:.4f}.format(
sum_loss / len(test_set), sum_acc / len(test_set)))接下来笔者对上面代码中的①~⑤加以说明。①处使用DataLoader取出小批量数据,②处使用accuracy函数计算识别精度,③处使用测试数据集对每轮的模型进行评估。由于测试阶段不需要反向传播,所以我们将这段代码置于withdezero.no_grad():的作用域内。这样可以省掉反向传播的处理,节约相关资源(no_grad函数已在步骤18中引入)。
④处从用于测试的 DataLoader 中取出小批量的数据进行评估。最后的 ⑤ 处使用 accuracy 函数计算识别精度。
现在运行上面的代码。图50-1是结果的可视化图形。
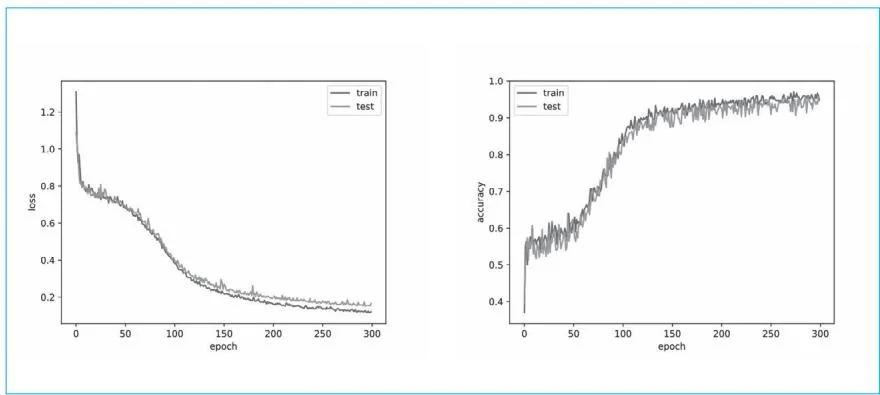
图50-1 损失和识别精度的变化情况
如图50-1所示,随着轮数的增加,损失(loss)逐渐减少,识别精度(accuracy)逐渐增加。这是训练正确进行的证据。图50-1还显示出训练(train)和测试(test)之间的差异很小。据此可以说我们的模型没有过拟合。

过拟合是模型过度拟合了特定训练数据的状态。无法预测未知数据的状态,或者说不能泛化的状态就是过拟合。由于神经网络可以创建表达能力较强的模型,所以经常出现过拟合。
以上就是本步骤的内容。下一个步骤将使用MNIST数据集来代替螺旋数据集。
步骤51
MINST 的训练
在前面的步骤,我们已经建立了易于处理数据集的机制,这里简单回顾一下。首先,我们通过Dataset类统一了数据集的处理(固定了接口);然后,让数据集的预处理可以在Dataset类中设置;最后,让小批量数据可通过DataLoader类从Dataset中创建。这些类之间的关系如图51-1所示。

图51-1 DeZero数据集的类图
图51-1中的Callable是执行预处理的对象(可调用对象)。图中各类之间的关系是:Callable由Dataset持有,Dataset由DataLoader持有。用户(用户编写的训练代码)从DataLoader请求数据,获得小批量数据。
本步骤将使用前面的数据集机制来训练另一个新的数据集。这个新的数据集就是MNIST。我们首先来简单了解一下MNIST数据集。