51.3_改进模型
51.3 改进模型
我们之前使用的神经网络的激活函数是sigmoid函数。在神经网络的历史上,sigmoid函数很早就被人们使用了。近来,人们经常使用ReLU(Rectified Linear Unit)函数来代替它。ReLU函数在输入大于0时按原样输出,在输入小于等于0时输出0。它的式子如下所示。
正如我们所看到的那样,ReLU函数是一个非常简单的函数。在DeZero中可以很轻松地实现ReLU函数,代码如下所示。
dezero/functions.py
classReLU Function): defforward(self,x): y=np.maxum(x,0.0) returny defbackward(self,gy): x,= selfinputs mask=x.data>0 gx=gy\*mask returngx
defrelu(x): returnReLU()x正向传播通过np.maximum(x, 0.0)取出x的元素和0.0中更大的值。在反向传播中,x中大于0.0的元素,其位置的梯度按原样通过,而其他位置的梯度则被设置为0。因此,我们需要准备一个用来表示梯度是否通过的mask,
并将其与梯度相乘。

ReLU函数所做的就是“让信号通过”和“不让信号通过”两个处理。在正向传播中信号通过的元素的相应梯度会在反向传播中按原样通过,而在正向传播中信号没有通过的元素的相应梯度在反向传播中也不会通过(值是0)。
下面使用ReLU函数创建新的神经网络。这里将本步骤的训练代码中创建模型的部分修改如下。
steps/step51.py
# model = MLP((hidden_size, 10))
model = MLP((hidden_size, hidden_size, 10), activation=Frelu)与之前的代码相比,层数有所增加,神经网络变为3层。层数增加了,模型的表现力比之前更丰富了。另外,激活函数变为ReLU函数,神经网络有望更高效地进行训练。我们将这个神经网络的优化方法从SGD改为Adam后,对其进行训练。结果,在训练数据上的识别精度约为 ,在测试数据上的识别精度约为 。与之前的结果相比,精度得到了大幅改善。
★★★★★★★
第4阶段的内容到此结束。在这个阶段,我们改进了DeZero以支持神经网络。对于基本的神经网络问题,使用现在的DeZero都可以轻松解决。DeZero已经升级为神经网络的框架和深度学习的框架了。更重要的是,我们到目前为止学到的知识也适用于PyTorch和Chainer等著名框架。
试着去读一下Chainer官方的examples中的MNIST训练代码吧(参考文献[30]),你会发现大部分的代码与我们本步骤的代码相似。再去看看PyTorch的MNIST代码(参考文献[31]),你也能马上理解它。尽管类名和模块名不同,但也只是接口和名称不同,它们在本质上与DeZero基本相同。我们现在掌握了可以灵活使用PyTorch和Chainer等真正框架的“活的知识”!
专栏:深度学习框架
早期的深度学习框架之间有很大差异,而现在的框架已经十分成熟。PyTorch、Chainer和TensorFlow等流行的框架大多朝着同一个方向发展。虽然它们特点不同,接口迥异,但它们的核心设计理念有许多共同之处。具体来说,有以下几点。
可以创建 Define-by-Run 风格的计算图
有一套函数、层等类的集合
有一套更新参数的类(优化器)的集合
可以将模型分为子类来实现
有管理数据集的类
除了CPU,还可以在GPU或专用的ASIC上运行有可以作为静态计算图来运行的模式,以提高性能(以及用于产品)
上述特征是所有现代深度学习框架的共同特征。本专栏将结合具体的例子,详细探讨前3点。

严格来说,深度学习的框架不是工具或库。库和框架的区别在于由谁来控制程序。库是工具函数和数据结构的集合,用户从库中适当地取出必要的东西来使用。此时,程序的控制,即以怎样的顺序执行代码由用户决定。框架则是基础。拿深度学习的框架来说,它是自动微分的基础,用户在此基础上构建所需要的计算。此时,由框架来控制程序整体。总而言之,库和框架在程序由谁来控制这一点上是有区别的。
Define-by-Run方式的自动微分
深度学习框架中最重要的功能是自动微分。有了自动微分,我们可以毫不费力地求出导数,而且现代的框架使用的是Define-by-Run方式创建计算图。代码
会立即被执行,计算图会在幕后被创建。因此,使用Python的语法创建计算图是可行的,例如在使用PyTorch的情况下可以编写以下代码。
import torch
$\mathbf{x} =$ torch.random(1,requires_grad=True)
$y = x$
for i in range(5): $\mathrm{y} = \mathrm{y}^{*}\mathrm{2}$
y.backup()
print(x.grad)运行结果
tensor([32.])
PyTorch中处理张量的类是Tensor(DeZero中相应的类是Variable)。上面的例子使用torch.random方法创建了一个用随机数初始化的张量(torch.Tensor实例),然后使用for语句进行计算。此时计算被立即执行,计算的“连接”是在幕后完成的。这就是Define-by-Run。之后使用y.backup()来求导。这种风格与我们的DeZero相同。
除了 Define-by-Run,PyTorch、Chainer 和 TensorFlow 的框架也有以 Define-and-Run(静态计算图)方式运行的模式。Define-by-Run 适用于研究和开发中的试错阶段,Define-and-Run 更适用于注重性能的产品和边缘计算环境。

TensorFlow的版本1需要使用一种专有的领域特定语言来创建计算图。不过从版本2开始,TensorFlow增加了以Define-by-Run方式(在TensorFlow中叫作Eager Execution)运行的模式,并且以它为标准模式。
层的类集
我们可以通过组合已准备好的 Linear 层和 Sigmoid 层等来建立神经网络模型。因此,深度学习的实现往往可以通过简单地组合现有的层来完成,就像搭乐高积木一样。当然,要做到这一点,需要框架提供一套层的类集,例如 Chainer 提供了图 D-1 所列的层。
Learnable connections
图D-1 Chainer提供的部分层的示例:Chainer提供两种被称为层的模块,它们分别是link和function。图中展示的是link的一部分(图片摘自参考文献[32])
如图D-1所示,Chainer提供了各种层。用户可从中选择需要的层,并通过连接它们来建立一个神经网络。深度学习的框架就是像这样提供了各种层。这里,
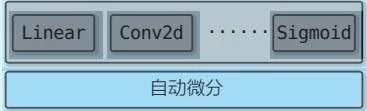
关键的点在于这些层的类集是建立在自动微分的机制之上的。具体结构如图D-2所示。
Linear
Conv2d
Sigmoid
自动微分
图D-2 框架提供的各种层的类集以自动微分机制为基础
如图D-2所示,深度学习框架以自动微分机制为基础,它们利用这种自动微分机制提供了各种层。理解了该结构后,我们就可以站在更高的维度上看待框架本身,而不会被各种框架的细节所迷惑。
优化器的类集
深度学习训练使用参数的梯度来依次更新参数。更新方法多种多样,现在人们仍在提出新的方法。在此背景下,由独立模块负责参数更新是普遍的做法。例如在 TensorFlow 中,这样的模块叫作优化器。TensorFlow 提供了一套优化器,如图 D-3 所示。
Classes
class Adelta: Optimizer that implements the Adadelta algorithm.
class Adagrad: Optimizer that implements the Adagrad algorithm.
class Adam: Optimizer that implements the Adam algorithm.
class Adamax: Optimizer that implements the Adamax algorithm.
class Ftrl: Optimizer that implements the FTRL algorithm.
class Nadam: Optimizer that implements the NAdam algorithm.
class Optimizer:Updated base class for optimizers.
class RMSprop: Optimizer that implements the RMSprop algorithm.
class SGD: Stochastic gradient descent and momentum optimizer.
如图D-3所示,TensorFlow提供了各种优化器。有了这样的优化器的类集,用户就可以在更高的层面上思考更新参数的任务了。此外,在不同的优化器之间进行切换的操作也非常简单,便于试错。
小结
本专栏探讨的是深度学习框架的核心功能。总的来说,框架具有自动微分功能,在此基础上实现了层的类集,还有用于更新参数的优化器类集。这些功能如图D-4所示。
层的类集
图D-3 TensorFlow提供的优化器列表(摘自参考文献[33])
优化器的类集

图D-4 深度学习框架的核心功能
图D-4中的3个功能是大多数框架具有的重要功能,其中作为框架支柱的是自动微分。有了自动微分功能,在此基础上创建各种层的类集,也就搭好了框架的骨架,再提供用于更新参数的优化器的类集,就能覆盖深度学习要做的大部分工作了。
了解了图D-4所示的3个核心功能的结构之后,我们就对框架有了整体印象,能够更为简单地看待它们。理解这种结构也有助于我们使用PyTorch、Chainer和TensorFlow等框架。
第5阶段
DeZero 高级挑战
在第4阶段,我们向DeZero增加了机器学习,尤其是神经网络特有的功能。具体来说是Layer、Optimizer和DataLoader等类。有了这些类,我们就可以使用DeZero轻松地创建模型,高效地训练模型。DeZero已经具备了开发神经网络的基本功能。
接下来我们要将DeZero提高到一个新的水平。具体来说就是增加一些新的功能,比如在GPU上运行DeZero和将模型保存到外部文件等。此外,DeZero还将支持在训练和测试时改变行为的层(Dropout等)。有了这些功能,DeZero会成为一个优秀的深度学习框架。
在这个阶段的后半部分,我们会实现CNN(卷积神经网络)和RNN(循环神经网络)。这些网络结构很复杂,看上去不容易实现,不过使用DeZero后,我们会发现这些复杂的网络结构非常好处理。现在我们进入最后一个阶段。

步骤52
支持GPU
深度学习所做的计算大多为矩阵的乘积。矩阵的乘积由乘法运算和加法运算构成,可以并行计算,GPU比CPU更擅长这种计算。本步骤将创建在GPU上运行DeZero的机制。

要在GPU上运行DeZero,从硬件方面来说,需要NVIDIA的GPU;从软件方面来说,需要Python的库CuPy。如果手头的环境不符合这些要求,也可以使用Google Colaboratory在云端的GPU上运行DeZero(从2020年2月开始可免费使用)。附录C介绍了Google Colaboratory的相关内容,感兴趣的读者可以查看。