48.2_用于训练的代码
48.2 用于训练的代码
下面是进行多分类的代码。由于代码量很大,这里笔者把它分成前后两部分来介绍,首先是代码的前半部分。
steps/step48.py
import math
import numpy as np
importdezero
fromdezero import optimizers
importdezero-functions as F
fromdezero.models import MLP设置超参数
max_epoch = 300
batch_size = 30
hidden_size = 10
lr = 1.0读入数据 创建模型和Optimizer
x, t =dezero.datasets.get Spiral(train=True)
model = MLP((hidden_size, 3))
optimizer = optimizers.SGD(lr).setup(model)上面的代码与此前我们见过的代码基本相同。首先在代码①处设置超参数。超参数是由人决定的参数,中间层的数量和学习率就属于此类。然后在②处加载数据集并创建模型和Optimizer。
上面的代码设置max_epoch = 300。轮(epoch)是训练单位。使用完所有事先准备的数据(“看过”所有数据)为1轮。代码中还有batch_size = 30,它表示一次处理30个数据。

这里要处理的数据总共有300条,比前面示例中的数据都多。在实际的工作中,要处理的数据通常会更多。在这种情况下,我们可以随机抽取一部分数据进行处理,而不是一次性处理所有的数据。这种部分数据的集合叫作小批量(mini batch)。
代码的后半部分如下所示。
steps/step48.py
data_size = len(x)
max_iter = math.ceil(data_size / batch_size) # 小数点向上取整for epoch in range(max_epoch):
# ③数据集索引重排
index = np.random.permutation(data_size)
sum_loss = 0
for i in range(max_iter):
# ④创建小批量数据
batch_index = index[i * batch_size:(i + 1) * batch_size]
batch_x = x[batch_index]
batch_t = t[batch_index]
# ⑤算出梯度 / 更新参数
y = model(batch_x)
loss = F softmax.Cross_entropy(y, batch_t)
model.cleargrads()
loss_backward()
optimizer.update()
sum_loss += float(loss.data) * len(batch_t)
# ⑥输出每轮的训练情况
avg_loss = sum_loss / data_size
print('epoch %d, loss %.2f' % (epoch + 1, avg_loss))代码③处使用np.random.permutation函数随机重新排列数据集的索引。如果调用np.random.permutation(N),那么这个函数将输出一个从0到N-1的随机排列的整数列表。上面的代码在每轮训练时都调用index = np.random.permutation(data_size),重新创建随机排列的索引列表。
代码④处创建小批量数据。小批量数据的索引(batch_index)是从之前创建的index中按顺序从头开始取出的。DeZero函数需要Variable或ndarray实例作为输入。上面的例子中小批量数据的batch_x和batch_t都是ndarray实例。当然,通过Variable(batch_x)显式地将它们转换为Variable后,计算仍然会正确进行。
代码⑤处像往常一样求梯度,更新参数。代码⑥处记录每轮损失函数的结果。以上就是用于训练螺旋数据集的代码。
现在运行上面的代码。从结果可知,损失(loss)正在稳步减少。结果如图48-2所示。
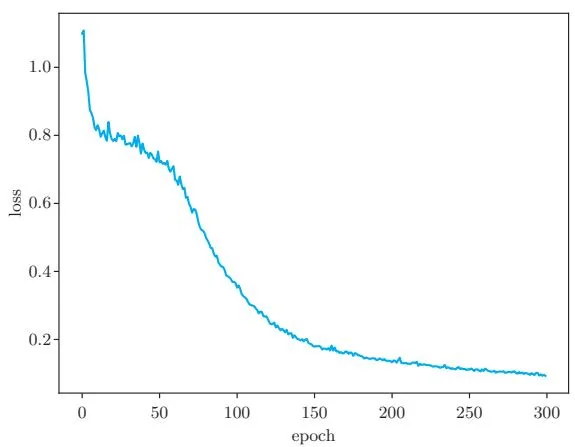
图48-2 损失的图像(横轴为轮,纵轴为每轮的平均损失)
如图48-2所示,随着训练的推进,损失逐渐减少。我们的神经网络看上去正在沿着正确的方向进行训练。下面对训练后的神经网络生成了什么样的分离区域,即决策边界(decision boundary)进行可视化操作。结果如图48-3所示。
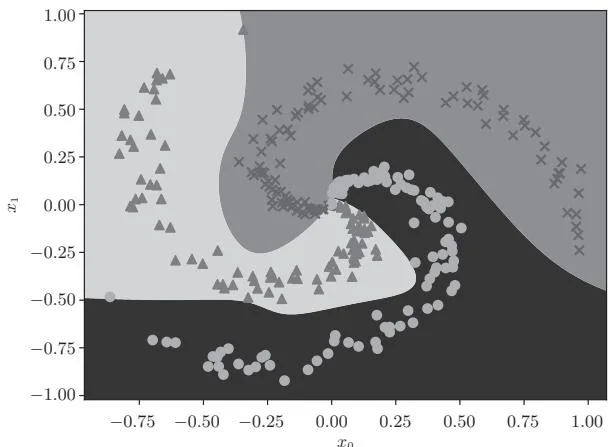
图48-3 训练后神经网络的决策边界
如图48-3所示,训练后的神经网络准确地识别出了“螺旋”模式。也就是说,它能够学习到非线性的分离区域。这说明神经网络能够通过隐藏层表示复杂的东西。通过增加更多的层来丰富表现力正是深度学习的一大特征。
步骤49
Dataset类和预处理
上一个步骤使用螺旋数据集进行了多分类。当时我们使用代码 , dezero.datasets.get Spiral() 加载了数据。读取到的 和 是 ndarray 实例, 的形状是 (300, 2), 的形状是 (300,)。换言之,我们在一个 ndarray 实例中保存了 300 条数据。
螺旋数据集是一个大约有300条数据的小数据集,所以我们能够把它当作一个ndarray实例进行处理。但是当我们处理大型数据集时,比如一个由100万个元素构成的数据集,这种数据形式就会出现问题。这是因为如果处理的是一个巨大的ndarray实例,我们必须将所有的元素都保存到内存中。为了解决此类问题,本步骤将创建一个数据集专用的Dataset类,之后在Dataset类中提供数据预处理的机制。