抽样
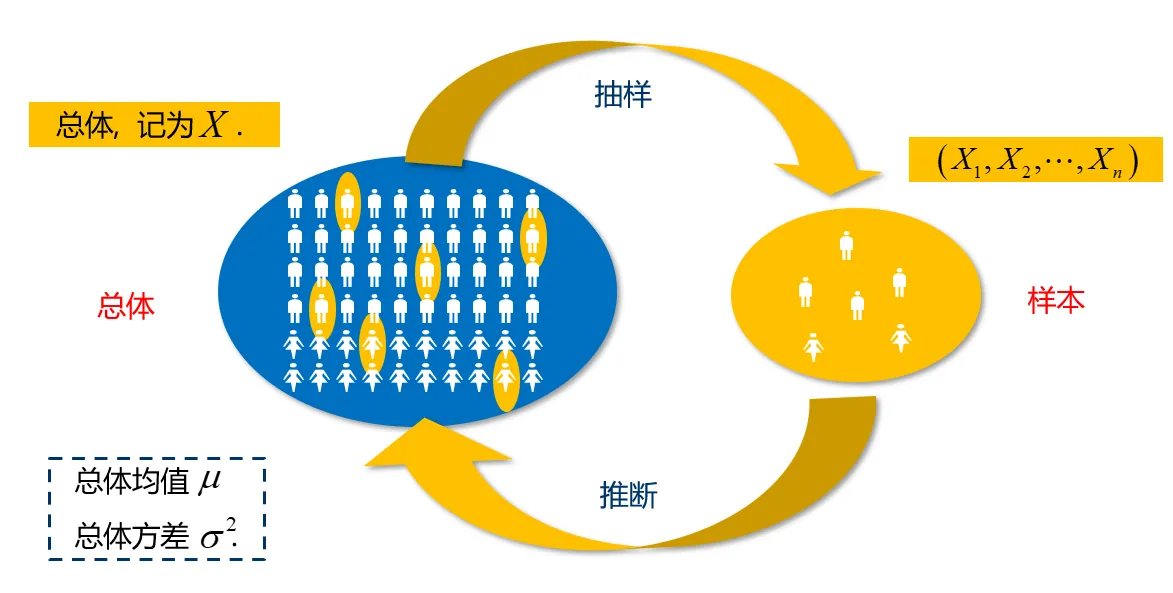
从总体中抽取样本的方法有很多,我们主要采用简单随机抽样的方法,即有放回地重复独立抽取,这样得到的样本称为简单随机样本 (简称样本). 记作 (X1,X2,⋯,Xn).
在试验前,样本的观测值是不确定的,为了体现随机性,在数理统计中样本记 作 (X1,X2,⋯,Xn) ,事实上是一个 n 维随机向量.
通过实验或观测得到的数值称为样本观测值,记作 (x1,x2,⋯,xn) ,其中 n 称为 样本容量(样本大小).
也就是说样本是一组随机变量,而样本观测值是抽样完成以后所得到的这组随机变量的
一次具体取值.
 {width=500px}
{width=500px}
简单随机样本具有两个特点:
(1) 独立性: X1,X2,⋯,Xn 是相互独立的;
(2) 代表性: 每个个体 Xi 的分布都和总体分布相同. 即 Xi∼f(xi,θ),i=1,2,⋯,n.
① 设 X 为离散型随机变量,则 X∼f(x;θ)=^P(X=x)
而样本 (X1,X2,⋯,Xn) 的联合分布律为:
f(x1,x2,⋯,xn;θ)=^P(X1=x1,X2=x2,⋯,Xn=xn;θ)=P(X1=x1)P(X2=x2)⋯P(Xn=xn)=i=1∏nP(Xi=xi;θ) 例某饮料厂生产的一种瓶装饮料规定净含量为 650 克.事实上不可能使得所有的饮料净含量均为 650 克.现从该厂生产的饮料中随机抽取 12 瓶测定其净含量,获得如下结果: 645,652,642,646,647,643,648,649,651,649,647,646 .这是一个容量为 12的样本观测值,对应的总体为该厂生产的瓶装饮料的净含量.
简单随机样本是一种非常理想化的样本,在实际应用中要获得严格意义下的简单随机样本并不容易.无特别声明,本书抽得的样本皆指简单随机样本.样本 X1,X2,⋯,Xn 可以视为相互独立的具有同一分布的随机变量,又称为独立同分布样本(即为 iid 样本),其联合分布即为总体分布。
若总体 X 的分布函数为 F(x),X1,X2,⋯,Xn 为总体 X 的一个样本,则 X1,X2,⋯,Xn 的联合分布函数为
F(x1,x2,⋯,xn)=i=1∏nF(xi). 当总体 X 为连续型随机变量时,若其概率密度为 f(x) ,则样本的联合概率密度为
f(x1,x2,⋯,xn)=i=1∏nf(xi) 当总体 X 为离散型随机变量时,若其概率分布为 p(x)=P{X=x} ,则样本的联合概率分布为
p(x1,x2,⋯,xn)=p{X=x1,X=x2,⋯,X=xn}=i=1∏np(xi). 例 考察某厂的产品质量,将其产品分为合格品和不合格品,并以 0 表示合格品,以 1 表示不合格品,显然 X∼B(1,p),0<p<1 .设 X1,X2,⋯,Xn 为来自总体 X 的样本,求该样本的概率分布。
解 总体 X 的分布律为 P{X=i}=pi(1−p)1−i,i=0,1 .
因为样本 X1,X2,⋯,Xn 相互独立,且与总体 X 同分布,所以样本的概率分布为
P{X1=x1,X2=x2,⋯,Xn=xn}=P{X1=x1}⋅P{X2=x2}⋯P{Xn=xn}=i=1∏npxi(1−p)1−xi=p∑i=1nxi(1−p)n−∑i=1nxi,xi∈{0,1},i=1,2,⋯,n. 例设总体 X∼P(λ), (X1,X2,⋯,X6) 为取自该总体的一个样本,
求样本 (X1,X2,⋯,X6) 的联合分布律 f(x1,x2,⋯,x6;λ) ?
解
f(x1,x2,⋯,x6;λ)=e−λx1!λx1⋅e−λx2!λx2⋯⋯e−λx6!λx6=e−6λ∏i=16xi!λ∑i=1nxi,x1,x2,⋯,x6=0,1,2,⋯ 例设总体 X∼U(0,θ), (X1,X2,L,Xn) 是取自上均匀分布总体 X 的一个样本,θ>0 末知,
求样本( X1,X2,⋯,X6 )的联合密度函数?
解
f(x1,x2,⋯,xn;θ)=fX1(x1;θ)fX2(x2;θ)……fxn(xn;θ)={θ−n00<x1,x2,⋯,xn<θ 其它 例设总体 X∼N(μ,σ2),(X1,X2,⋯,Xn) 为取自该总体的一个样本,求样本 (X1,X2,⋯,Xn) 的联合密度函数?
解
f(x1,x2,⋯,xn;μ,σ2)=(2πσ2)2n1e−2σ2∑(xi−μ)2,−∞<xi<+∞ 例设 (X1,X2,⋯,Xn) 是取自总体 X 的一个样本,X 的 概率密度函数为
f(x,θ)={θ22x00<x<θ 其余 试写出 (X1,X2,⋯,Xn) 的联合密度函数.
联合密度函数为
f∗(x1,x2,⋯,xn,θ)={θ2n2nx1⋯xn00<xi<θ,i=1,2,⋯,n 其余