样本均值
假设有一组学生,身高分别是 160,162,165,165,168 我要求他的平均身高,只要把这几个数加起来,除以个数即可,即
xˉ=(160+162+165+165+168)/5=164 由此可得样本均值的定义:
样本均值 xˉ=n1∑i=1nxi
样本分组均值 在分组样本场合,样本均值的近似公式为
\bar{x}=\dfrac{x_1 f_1+x_2 f_2+\cdots+x_k f_k}{n} \
其中 k 为组数,xi 为第 i 组的组中值,fi 为第 i 组的频数.
如何理解样本分组后的均值?简单的理解,就是“加权平均数”,比如电视直播歌手比赛,专业评委和观众都可以打分,同样是打9分,专业评委的权重会比观众的权重要高,因此,此时计算分数,就使用了加权平均数。
例 某单位收集到 20 名青年人某月的娱乐支出费用数据:
\begin{array}
790 & 840 & 840 & 880 & 920 & 930 & 940 & 970 & 980 & 990 \\
1000 & 1010 & 1010 & 1020 & 1020 & 1080 & 1100 & 1130 & 1180 & 1250
\end{array}
则该月这 20 名青年的平均娱乐支出为
xˉ=201(790+840+⋯+1250)=994. 将这 20 个数据分组可得到如下频数频率表:
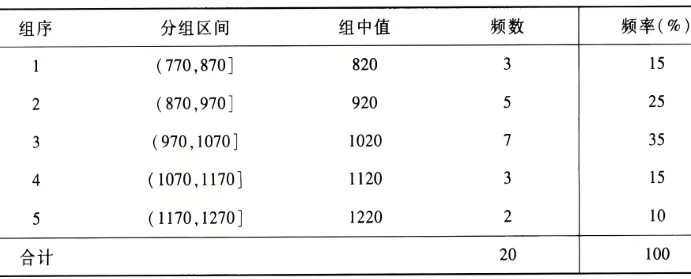
使用样本分组均值公式计算可得
xˉ=201(820×3+920×5+⋯+1220×2)=1000. 我们看到两种计算结果不同.事实上,由于上式未用到真实的样本观测数据,因而给出的是近似结果.
样本方差与样本标准差
样本方差 s2=n−11∑i=1n(xi−xˉ)2
样本标准差的观测值 s=n−11∑i=1n(xi−xˉ)2
为什么样本方差除以n−1而总体方差除以n?
在高中概率统计里学过方差,详见 此处,
样本方差计算公式里n-1与自由度有关系?那总体标准差为什么用n就没有自由度关系?
总体方差:总体方差是所有数据点与总体均值的偏差平方的平均值。如果总体数据是 X1,X2,…,Xn ,总体均值是 μ ,那么总体方差 σ2 的计算公式为:
σ2=N1i=1∑N(Xi−μ)2 这里除以 N 是因为总体方差是所有数据点的平均偏差平方。
样本方差:样本方差是样本数据点与样本均值的偏差平方的平均值。如果样本数据是 x1,x2,…,xn ,样本均值是xˉ,那么样本方差 s2 的计算公式为:
s2=n−11i=1∑n(xi−xˉ)2 样本方差是总体方差的无偏估计,那什么是无偏估计呢?
无偏估计:无偏估计是指估计量的期望值等于被估计的参数。在样本方差的计算中,使用 n−1 作为分母可以使得样本方差的期望值等于总体方差,即
E(s2)=σ2
这个性质对于统计推断非常重要,因为它保证了样本方差是一个可靠的总体方差估计。
综上所述,总体方差除以N是因为它是所有数据点的平均偏差平方,而样本方差除以 n−1 是为了对总体方差进行无偏估计。
或者说,这里除以 n−1 而不是 n 的原因是样本方差需要对总体方差进行无偏估计。样本均值xˉ是从样本数据中计算出来的,它本身也存在一定的偏差。使用 n−1 作为分母可以校正这个偏差,使得样本方差的期望值等于总体方差。
关于本题的数学推导,请参考 无偏向
如果从自由度的角度来讲,首先我们先从样本方差统计计算来看,因为一组样本值,由于其均值是一定的,即 xˉ=(x1+x2...+xn)/n ,由于有这个等式的存在,相当于增加了一个限制, 当xˉ固定了,看似有n个变量,但是真正能随便取值的是n−1 个,因此样本方差计算时,它的自由度是n−1, 即要除以n−1 n 。
那问题来了,为什么在计算整体(或称母本)方差时,而是除以n呢? 还是自由度,当计算整体时,均值为 μ=(x1+x2...+xn)/n
数据中n个可以自由变化的数字。在求解方差时,均值μ 看似增加了一个等式,其实是n个未知数,但是是n+1个等式,因此方差除以n
结论
样本方差是度量样本散布大小的统计量,使用广泛,在它的这个定义中, n 为样本量,∑i=1n(xi−xˉ)2 称为偏差平方和,n−1 称为偏差平方和的自由度。其含义是:在 xˉ 确定后,n 个偏差 x1−xˉ,x2−xˉ,⋯,xn−xˉ 中只有 n−1 个偏差可以自由变动,而第 n个则不能自由取值,因为 ∑(xi−xˉ)=0 .
样本偏差平方和有三个常用的表达式:
∑(xi−xˉ)2=∑xi2−n(∑xi)2=∑xi2−nxˉ2 它们都可用来计算样本方差.
在分组样本场合,样本方差的近似计算公式为
s2=n−11i=1∑kfi(xi−xˉ)2=n−11(i=1∑kfixi2−nxˉ2), 其中 xi,fi 分别为第 i 个区间的组中值和频数, xˉ 为分组均值里给出的样本均值近似值.
原点矩与中心矩
设 x1,x2,⋯,xn 是样本,k 为正整数,则统计量
ak=n1i=1∑nxik 称为样本 k 阶原点矩,特别,样本一阶原点矩就是样本均值.
统计量
bk=n1i=1∑n(xi−xˉ)k 称为样本 k 阶中心矩.
为什么要搞出原点矩和中心矩?如果说用样本估算总体,那我们希望估算的越准确越好。想象一下高等数学里泰勒展开 我们使用一阶导,二阶导,一直到n阶导拟合曲线。同样,如果样本期望和总体期望相同,样本方程和总体方差相同,样本3阶矩和总体3阶矩相同... 这不是最好的吗? 关于原点矩和中心矩还有矩母函数请点击附录2
例设总体 X 的均值 E(X)=μ ,方差 D(X)=σ2,(X1,X2,⋯,Xn) 为取自该总体的一个 样本,则
(1) E(xˉ)=μ,D(xˉ)=nσ2
(2) E(S2)=σ2,E(Sn2)=nn−1σ2,n≥2
(3) Xˉ⟶Pμ,S2=n−11∑i=1n(Xi−Xˉ)2→Pσ2,Sn2=n1∑i=1n(Xi−Xˉ)2⟶Pσ2.
证 (1)
E(Xˉ)=E(n1i=1∑nXi)=n1i=1∑nE(Xi)=μ,D(Xˉ)=D(n1i=1∑nXi)=n21i=1∑nD(Xi)=n1σ2, 证 (2)
(n−1)E(S2)=E(i=1∑nXi2−nXˉ2)=(i=1∑nE(Xi2)−nE(Xˉ2))=n(D(X1)+E2(X1)−D(Xˉ)−E2(Xˉ))=n(σ2−nσ2)=(n−1)σ2⇒E(S2)=σ2,E(Sn2)=nn−1σ2 证 (3)
独立同分布的大数定律,即得 Xˉ⟶Pμ
n1i=1∑nXi2→pσ2+μ2, 所以 Sn2=n1∑i=1n(Xi−Xˉ)2=n1∑i=1nXi2−Xˉ2⟶Pσ2+μ2−μ2=σ2
S2=n−1nSn2→Pσ2 例 从某班级的英语期末考试成绩中,随机抽取 10 名同学的成绩(单位:分),分别为 100,85,70,65,90,95,63,50,77,86 .求样本均值、样本方差及二阶原点矩.
解
xˉ=101i=1∑10xi=101(100+85+⋯+86)=78.1S2=n−11i=1∑n(xi−xˉ)2=91(21.92+6.92+⋯+7.92)=252.5a2=n1i=1∑nxi2=101i=1∑10xi2=101(1002+852+702+⋯+862)=6326.9 二阶矩的重要性质
设总体 X 具有二阶矩,即 E(X)=μ,D(X)=σ2<+∞,X1,X2,⋯,Xn 为来自总体 X 的样本, Xˉ 和 S2 分别是样本均值与样本方差,则
(1)E(Xˉ)=E(X)=μ ;
(2)D(Xˉ)=n1D(X)=nσ2 ;
(3)E(S2)=D(X)=σ2 .
证明:
(1)E(Xˉ)=E(n1∑i=1nXi)=n1∑i=1nE(Xi)=nnμ=μ .
(2)D(Xˉ)=D(n1∑i=1nXi)=n21∑i=1nD(Xi)=n2nσ2=nσ2 .
(3)因为 E(Xi2)=D(Xi)+E2(Xi)=σ2+μ2 ,且 E(Xˉ2)=D(Xˉ)+E2(Xˉ)=nσ2+μ2 ,所以
E(S2)=n−11E[i=1∑n(Xi−Xˉ)2]=n−11E(i=1∑nXi2−nXˉ2)=n−11[nμ2+nσ2−n(μ2+nσ2)]=σ2 例 设总体 X∼B(m,θ),X1,X2,⋯,Xn 为来自该总体的简单随机样本, Xˉ 为样本均值,求 E[∑i=1n(Xi−Xˉ)2] .
解 由上面性质可得 E(S2)=D(X)=mθ(1−θ) ,从而
E[i=1∑n(Xi−X)2]=E[(n−1)S2]=m(n−1)θ(1−θ).