4.5_实践与应用
4.5 实践与应用
PEFT技术在许多领域中展现了其强大的应用潜力。本节将探讨PEFT的实践与应用。在实践部分,我们将介绍目前最流行的PEFT框架,HuggingFace开发的开源库HF-PEFT,并简述其使用方法和相关技巧。在应用部分,我们将展示PEFT技术在不同垂直领域中的应用案例,包括表格数据处理和金融领域的Text-to-SQL生成任务。这些案例不仅证明了PEFT在提升大模型特定任务性能方面的有效性,也为未来的研究和应用提供了有益的参考。
4.5.1 PEFT实践
在实际应用中,PEFT技术的实施和优化至关重要。本小节将详细介绍PEFT主流框架的使用,包括安装和配置、微调策略选择、模型准备与训练流程等内容,以及相关使用技巧。
1. PEFT主流框架
目前最流行的PEFT框架是由HuggingFace开发的开源库HF-PEFT²,它旨在提供最先进的参数高效微调方法。HF-PEFT框架的设计哲学是高效和灵活性。HF-PEFT集成了多种先进的微调技术,如LoRA、Apdater-tuning、Prompt-tuning和IA3等。HF-PEFT支持与HuggingFace的其他工具如Transformers、Diffusers和Accelerate无缝集成,并且支持从单机到分布式环境的多样化训练和推理场景。HF-PEFT特别适用于大模型,能够在消费级硬件上实现高性能,并且可以与模型量化技术兼容,进一步减少了模型的内存需求。HF-PEFT支持多种架构模型,包括Transformer和Diffusion,并且允许用户手动配置,在自己的模型上启用PEFT。
HF-PEFT 的另一个显著优势是它的易用性。它提供了详细的文档、快速入门
指南和示例代码3,可以帮助用户了解如何快速训练PEFT模型,以及如何加载已有的PEFT模型进行推理。此外,HF-PEFT拥有活跃的社区支持,并鼓励社区贡献,是一个功能强大、易于使用且持续更新的库。
2. HF-PEFT 框架使用
使用HF-PEFT框架进行模型微调可以显著提升模型在特定任务上的性能,同时保持训练的高效性。通常,使用HF-PEFT框架进行模型微调的步骤如下:
安装与配置:首先,在环境中安装HF-PEFT框架及其依赖项,主要是Hugging Face的 Transformers库。
选择模型与数据:根据任务需求,挑选合适的预训练模型,并准备相应的训练数据集。
确定微调策略:选择适合任务的微调方法,例如LoRA或适配器技术。
模型准备:加载预训练模型并为选定的微调方法进行配置,包括任务类型、推理模式、参数值等。
模型训练:定义完整的训练流程,包括损失函数、优化器设置,并执行训练,同时可应用数据增强和学习率调度等技术。
通过上述步骤,可以高效地使用HF-PEFT框架进行模型微调,以适应特定的任务需求,并提升模型性能。
3. PEFT相关技巧
HF-PEFT库提供了多种参数高效微调技术,用于在不微调所有模型参数的情况下,有效地将预训练语言模型适应各种下游应用。以下是一些PEFT技术常用的参数设置方法:
Prompt Tuning
num_virtual_tokens: 表示为每个任务添加的 virtual_tokens 的数量,也就是软
提示的长度,该长度通常设置在10-20之间,可根据输入长度进行适当调节。
prompt_tuning_init: 表示 prompt 参数的初始化方式。可以选择随机初始化 (RANDOM)、文本初始化 (TEXT), 或者其他方式。文本初始化方式下, 可以使用特定文本对 prompt embeddings 进行初始化以加速收敛。
Prefix Tuning
num_virtual_tokens: 与 Prompt Tuning 中相同,表示构造的 virtual tokens 的数量,设置和 Prompt Tuning 类似。
encoder_hidlen_size: 表示用于 Prefix 编码的多层感知机 (MLP) 层的大小, 通常与模型的隐藏层大小相匹配。
LoRA
• r: 秩的大小, 用于控制更新矩阵的复杂度。通常可以选择较小的值如 4、8、16, 对于小数据集, 可能需要设置更小的 值。
lora_alpha: 缩放因子,用于控制 LoRA 权重的大小,通常与 r 成反比,以保持权重更新的一致性。
lora_dropout: LoRA 层的 dropout 比率,用于正则化以防止过拟合,可以设置为一个较小的值,比如 0.01。
target Modules: 指定模型中 LoRA 中要应用的模块, 如注意力机制中的 query、key、value 矩阵。可以选择特定的模块进行微调, 或者微调所有线性层。
需要注意的是,具体的参数设置可能会根据所使用的模型、数据集和具体任务有所不同,因此在实际应用中可能需要根据实验结果进行调整。
4.5.2 PEFT应用
在现实应用中,大量垂直领域数据以表格的形式存储在关系型数据库中。不仅数量大,表格数据涵盖的领域也非常广泛,涉及金融、医疗、商务、气候科学众
多领域。然而,大语言模型的预训练语料中表格数据的占比通常很少,这导致其在表格数据相关的下游任务上的性能欠佳。微调大语言模型使其适应表格数据是参数高效微调的典型应用,其具有深远的现实意义。本节我们将介绍两个分别将参数高效微调技术应用在表格数据查询和表格数据分析上案例。
1. 表格数据查询
表格数据查询是处理、分析表格数据的必要步骤。对表格数据进行查询,需要编写专业的结构化查询语言(Structured Query Language,SQL)代码。然而,SQL代码通常涉及复杂的查询逻辑和严格的语法规则,专业人士都需要花费大量时间进行编写。对于初学者,熟练掌握并使用 SQL 可能需要数月或者更长的时间来学习和实践。编写 SQL 代码的为表格数据查询设置了较高的门槛。为了降低表格数据查询的门槛,可以将自然语言文本自动翻译成 SQL 代码的 Text-to-SQL 技术受到了广泛的关注。其可以将 SQL 编写时间从分钟级缩短到秒级,使数据科学家能够专注于分析和建模,加快数据驱动决策的速度,同时让广大普通人也能操作和管理数据库,显著提高了数据分析的效率,让更多的人能够挖掘和利用数据的价值。大语言模型的强大代码生成能力为 Text-to-SQL 技术带来了新的机遇。但是,在众多垂直领域,如金融领域,难以收集足够的用于微调的数据。利用少量数据进行全参数微调时则容易导致大模型过拟合,因此采用 PEFT 技术进行部分参数微调十分适合金融等垂直领域 Text-to-SQL 任务。
面向金融垂直领域,FinSQL [51]提出了一套针对金融垂直领域Text-to-SQL训练推理框架。如图4.10所示,该框架包含提示构造、参数高效微调和输出校准三个部分。首先,提示构造通过不同策略增强原始数据,并且构造高效检索器,检索与用户查询相关表格和字段。然后,采用PEFT技术对基座模型进行微调,通过LoRAHub融合多个LoRA模块,提高少样本场景的性能。最后,输出校准模块会修正生成SQL中的语法错误,并用Self-Consistency方法来选择一致性SQL。FinSQL
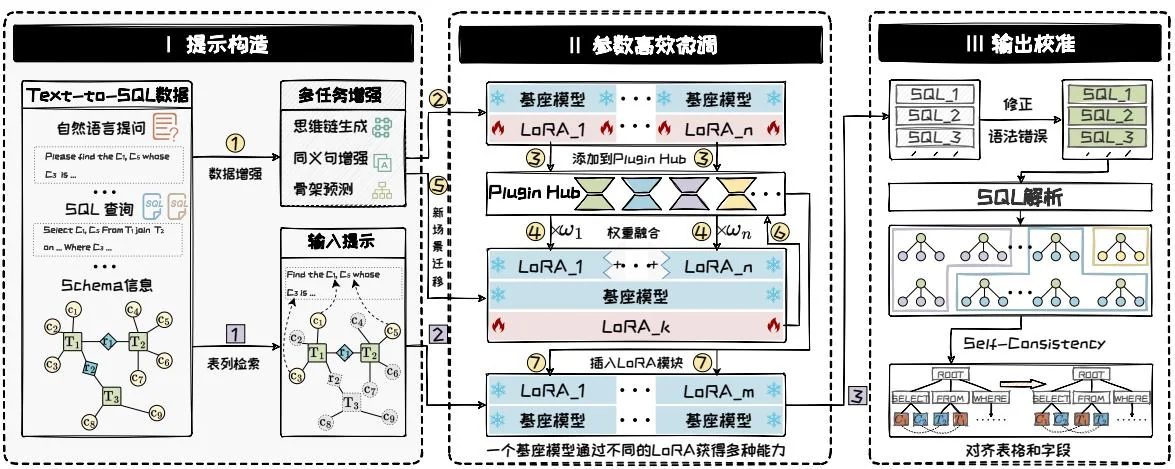
图4.10: FinSQL示意图。
相比于基线方法,不仅显著提升了准确性和效率,还展现了在处理复杂金融查询时的强大能力,为金融领域的数据分析和决策支持提供了强有力的技术支撑。
2. 表格数据分析
完成数据查询操作后,可以对查询到的数据进行进一步分析。但是,表格数据的特点——缺乏局部性、包含多种数据类型和相对较少的特征数量——使得传统的深度学习方法难以直接应用。大语言模型的参数中编码了大量先验知识,有效利用这些知识能够弥补表格数据特征不足的问题。但是,为了取得更好的性能,通常依旧需要少量标记数据使大模型适应表格任务。然而,在少量数据上进行模型微调容易导致过拟合。由于PEFT只微调部分参数,能有效降低过拟合的风险,使得大语言模型在表格数据上的性能更加稳健。
例如,TabLLM[17]提出基于大语言模型的少样本表格数据分类框架,图4.11为该方法的框架图。该框架将表格数据序列化为自然语言字符串,并附上分类问题的简短描述来提示大语言模型。在少样本设置中,使用LoRA在一些带标签的样本对大语言模型进行微调。微调后,TabLLM在多个基准数据集上超过基于深度学习的表格分类基线方法。此外,在少样本设置下,TabLLM的性能超过了梯度提升树等强大的传统基线,表现出了强大的小样本学习能力。

问题:Does this person earn more than 50000 dollars? Yes or no? Answer:
微调前模型推理
The age is 28. The education is Master. The gain is 1024.
Does this person earn more than 50000 dollars? Yes or no? Answer:
图4.11:TabLLM框架图。
微调后模型推理
The age is 28. The education is Master. The gain is 1024.
Does this person earn more than 50000 dollars? Yes or no? Answer:
本节介绍了参数高效微调技术的实践与应用。首先,我们介绍了PEFT主流框架HF-PEFT及其使用方法,并介绍了PEFT的相关技巧。最后,展示了PEFT技术如何帮助大语言模型提升在表格数据的查询与分析任务上的性能,使大语言模型适配垂域任务的同时保证训练效率。
参考文献
[1] Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. "Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning". In: ACL/IJCNLP. 2021.
[2] Alan Ansell et al. "Composable Sparse Fine-Tuning for Cross-Lingual Transfer". In: ACL. 2022.
[3] Daniel Bershatsky et al. “LoTR: Low Tensor Rank Weight Adaptation”. In: arXiv preprint arXiv:2402.01376 (2024).
[4] Dan Biderman et al. “LoRA Learns Less and Forgets Less”. In: arXiv preprint arXiv.2405.09673 (2024).
[5] Sarkar Snigdha Sarathi Das et al. “Unified Low-Resource Sequence Labeling by Sample-Aware Dynamic Sparse Finetuning”. In: EMNLP. 2023.
[6] Ning Ding et al. “Parameter-efficient fine-tuning of large-scale pre-trained language models”. In: Nat. Mac. Intell. 5.3 (2023), pp. 220–235.
[7] Ning Ding et al. "Sparse Low-rank Adaptation of Pre-trained Language Models". In: EMNLP. 2023.
[8] Qingxiu Dong et al. “A Survey for In-context Learning”. In: CoRR abs/2301.00234 (2023).
[9] Ali Edalati et al. “KronA: Parameter Efficient Tuning with Kronecker Adapter”. In: arXiv preprint arXiv:2212.10650 (2022).
[10] Vlad Fomenko et al. “A Note on LoRA”. In: arXiv preprint arXiv:2404.05086 (2024).
[11] Jonathan Frankle and Michael Carbin. “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks”. In: ICLR. 2019.
[12] Zihao Fu et al. “On the Effectiveness of Parameter-Efficient Fine-Tuning”. In: AAAI. 2023.
[13] Andi Han et al. "SLTrain: a sparse plus low-rank approach for parameter and memory efficient pretraining". In: arXiv preprint arXiv:2406.02214 (2024).
[14] Junxian He et al. “Towards a Unified View of Parameter-Efficient Transfer Learning”. In: ICLR. 2022.
[15] Shwai He et al. "SparseAdapter: An Easy Approach for Improving the Parameter-Efficiency of Adapters". In: Findings of EMNLP. 2022.
[16] Xuehai He et al. “Parameter-Efficient Model Adaptation for Vision Transformers”. In: AAAI. 2023.
[17] Stefan Hegselmann et al. “TabLLM: Few-shot Classification of Tabular Data with Large Language Models”. In: AISTATS. 2023.
[18] Neil Houlsby et al. “Parameter-Efficient Transfer Learning for NLP”. In: ICML. 2019.
[19] Edward J. Hu et al. “LoRA: Low-Rank Adaptation of Large Language Models”. In: ICLR. 2022.
[20] Chengsong Huang et al. “LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition”. In: arXiv preprint arXiv:2307.13269 (2023).
[21] Ting Jiang et al. “MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning”. In: arXiv preprint arXiv:2405.12130 (2024).
[22] Jaejun Lee, Raphael Tang, and Jimmy Lin. “What Would Elsa Do? Freezing Layers During Transformer Fine-Tuning”. In: arXiv preprint arXiv:1911.03090 (2019).
[23] Brian Lester, Rami Al-Rfou, and Noah Constant. “The Power of Scale for Parameter-Efficient Prompt Tuning”. In: EMNLP. 2021, pp. 3045–3059.
[24] Xiang Lisa Li and Percy Liang. “Prefix-Tuning: Optimizing Continuous Prompts for Generation”. In: ACL. 2021.
[25] Vladislav Lialin et al. "ReLoRA: High-Rank Training Through Low-Rank Updates". In: NIPS Workshop. 2023.
[26] Baohao Liao, Yan Meng, and Christof Monz. “Parameter-Efficient Fine-Tuning without Introducing New Latency”. In: ACL. 2023.
[27] Alisa Liu et al. "Tuning Language Models by Proxy". In: arXiv preprint arXiv:2401.08565 (2024).
[28] Jialin Liu et al. "Versatile black-box optimization". In: GECCO. 2020, pp. 620-628.
[29] Shih-Yang Liu et al. “DoRA: Weight-Decomposed Low-Rank Adaptation”. In: arXiv preprint arXiv:2402.09353 (2024).
[30] Yulong Mao et al. "DoRA: Enhancing Parameter-Efficient Fine-Tuning with Dynamic Rank Distribution". In: arXiv preprint arXiv:2405.17357 (2024).
[31] Yuren Mao et al. A Survey on LoRA of Large Language Models. 2024. arXiv: 2407.11046 [cs.LG]. URL: https://arxiv.org/abs/2407.11046.
[32] Fanxu Meng, Zhaohui Wang, and Muhan Zhang. “Pissa: Principal singular values and singular vectors adaptation of large language models”. In: arXiv preprint arXiv:2404.02948 (2024).
[33] Jinjie Ni et al. Instruction in the Wild: A User-based Instruction Dataset. https://github.com/XueFuzhao/InstructionWild.2023.
[34] Rui Pan et al. “LISA: Layerwise Importance Sampling for Memory-Efficient Large Language Model Fine-Tuning”. In: arXiv preprint arXiv.2403.17919 (2024).
[35] Jonas Pfeiffer et al. “AdapterFusion: Non-Destructive Task Composition for Transfer Learning”. In: EACL. Ed. by Paola Merlo, Jörg Tiedemann, and Reut Tsarfaty. 2021.
[36] Pengjie Ren et al. "Mini-Ensemble Low-Rank Adapters for Parameter-Efficient Fine-Tuning". In: arXiv preprint arXiv.2402.17263 (2024).
[37] Victor Sanh et al. Multitask Prompted Training Enables Zero-Shot Task Generalization. 2021.
[38] Ying Sheng et al. "S-LoRA: Serving Thousands of Concurrent LoRA Adapters". In: arXiv preprint arXiv:2311.03285 (2023).
[39] Yi-Lin Sung, Varun Nair, and Colin Raffel. "Training Neural Networks with Fixed Sparse Masks". In: NIPS. 2021.
[40] Hugo Touvron et al. "Llama 2: Open foundation and fine-tuned chat models". In: arXiv preprint arXiv:2307.09288 (2023).
[41] Mojtaba Valipour et al. “Dylora: Parameter efficient tuning of pre-trained models using dynamic search-free low-rank adaptation”. In: arXiv preprint arXiv:2210.07558 (2022).
[42] Mojtaba Valipour et al. "DyLoRA: Parameter-Efficient Tuning of Pre-trained Models using Dynamic Search-Free Low-Rank Adaptation". In: EACL. 2023.
[43] Zhongwei Wan et al. "Efficient Large Language Models: A Survey". In: arXiv preprint arXiv:2312.03863 (2023).
[44] Alex Wang et al. “GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding”. In: ICLR. 2019.
[45] Hanqing Wang et al. "MiLoRA: Harnessing Minor Singular Components for Parameter-Efficient LLM Finetuning". In: arXiv preprint arXiv:2406.09044 (2024).
[46] Yizhong Wang et al. "Self-Instruct: Aligning Language Models with Self-Generated Instructions". In: ACL. 2023.
[47] Jason Wei et al. "Finetuned language models are zero-shot learners". In: arXiv preprint arXiv:2109.01652 (2021).
[48] Wenhan Xia, Chengwei Qin, and Elad Hazan. "Chain of LoRA: Efficient Fine-tuning of Language Models via Residual Learning". In: arXiv preprint arXiv.2401.04151 (2024).
[49] Runxin Xu et al. “Raise a Child in Large Language Model: Towards Effective and Generalizable Fine-tuning”. In: EMNLP. 2021.
[50] Elad Ben Zaken, Yoav Goldberg, and Shauli Ravfogel. "BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models". In: ACL. 2022.
[51] Chao Zhang et al. "FinSQL: Model-Agnostic LLMs-based Text-to-SQL Framework for Financial Analysis". In: SIGMOD. 2024.
[52] Qingru Zhang et al. “Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning”. In: ICLR. 2023.
[53] Shengyu Zhang et al. "Instruction Tuning for Large Language Models: A Survey". In: arXiv preprint arXiv:2308.10792 (2023).
[54] Jiawei Zhao et al. "GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection". In: arXiv preprint arXiv.2403.03507 (2024).
[55] Mengjie Zhao et al. “Masking as an Efficient Alternative to Finetuning for Pre-trained Language Models”. In: EMNLP. 2020, pp. 2226–2241.
[56] Yaoming Zhu et al. “Counter-Interference Adapter for Multilingual Machine Translation”. In: Findings of EMNLP. 2021.

5 模型编辑
预训练大语言模型中,可能存在偏见、毒性、知识错误等问题。为了纠正这些问题,可以将大语言模型“回炉重造”——用清洗过的数据重新进行预训练,但成本过高,舍本逐末。此外,也可对大语言模型“继续教育”——利用高效微调技术向大语言模型注入新知识,但因为新知识相关样本有限,容易诱发过拟合和灾难性遗忘,得不偿失。为此,仅对模型中的特定知识点进行修正的模型编辑技术应运而生。本章将介绍模型编辑这一新兴技术,首先介绍模型编辑思想、定义、性质,其次从内外两个角度分别介绍模型编辑经典方法,然后举例介绍模型编辑的具体方法T-Patcher和ROME,最后介绍模型编辑的实际应用。